The Performance Challenge Championship (PCC) is an event organized by ArchNotes. After learning about the rules of the competition, I found PostgreSQL is very suitable for this scenario. The scenario is reproduced as it is, implemented with PG, but how does it perform?
I recently drew up a wireframe for a code beautifier. The next day, I decided to turn it into a real tool. The whole project took less than two days to complete.
I'd been thinking about building a new code beautifier for a while. The idea isn't unique, but every time I use someone else's tool, I find myself reapplying the same settings and dodging advertisements every single time. 🤦🏻
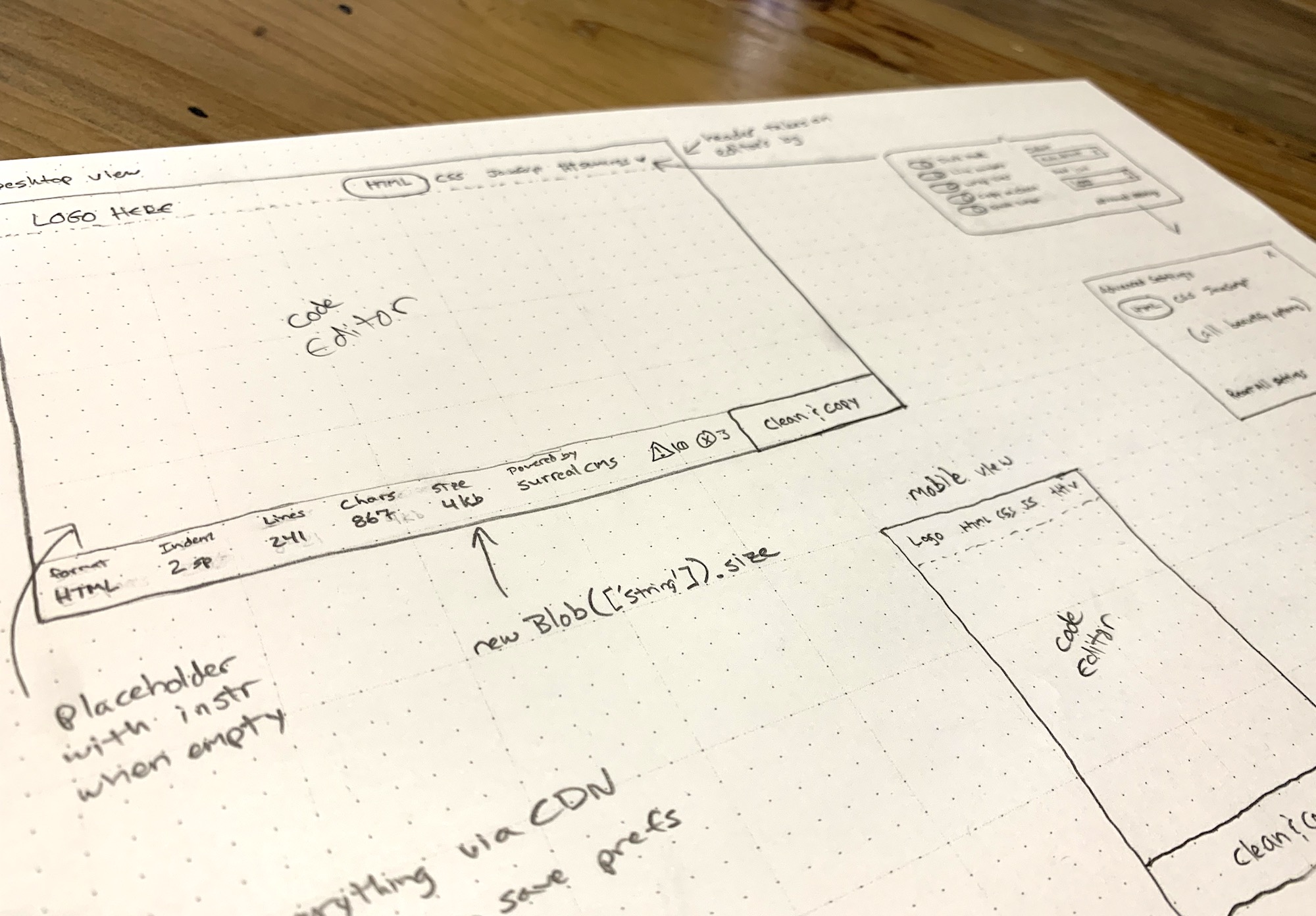
I wanted a simple tool that worked well without the hassle, so last week I grabbed some paper and started sketching one out. I'm a huge fan of wireframing by hand. There's just something about pencil and paper that makes the design part of my brain work better than staring at a screen.
I kicked off the design process by hand-drawing wireframes for the app.
I was immediately inspired after drawing the wireframe. The next day, I took a break from my usual routine to turn it into a something real. 👨🏻💻
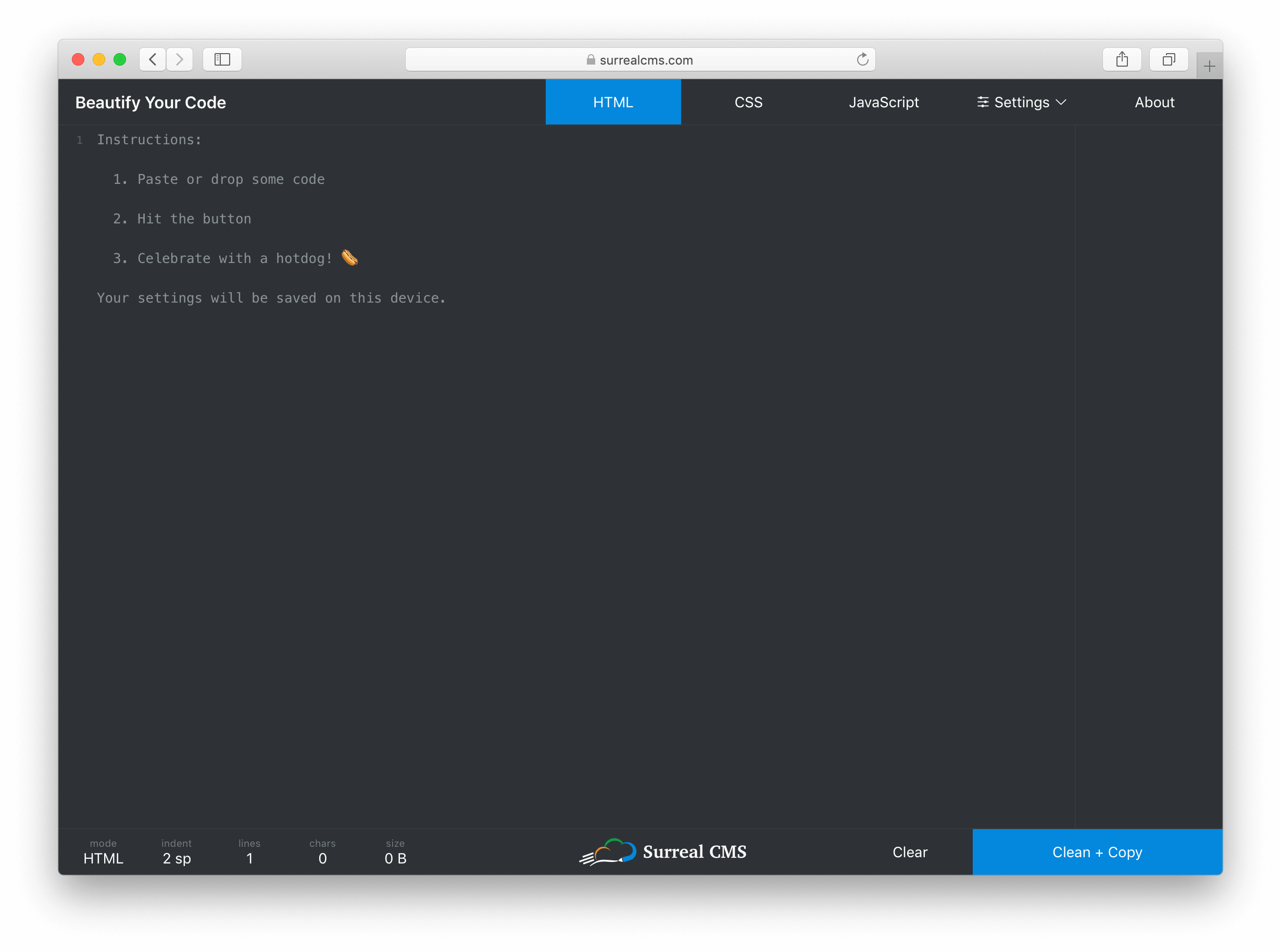
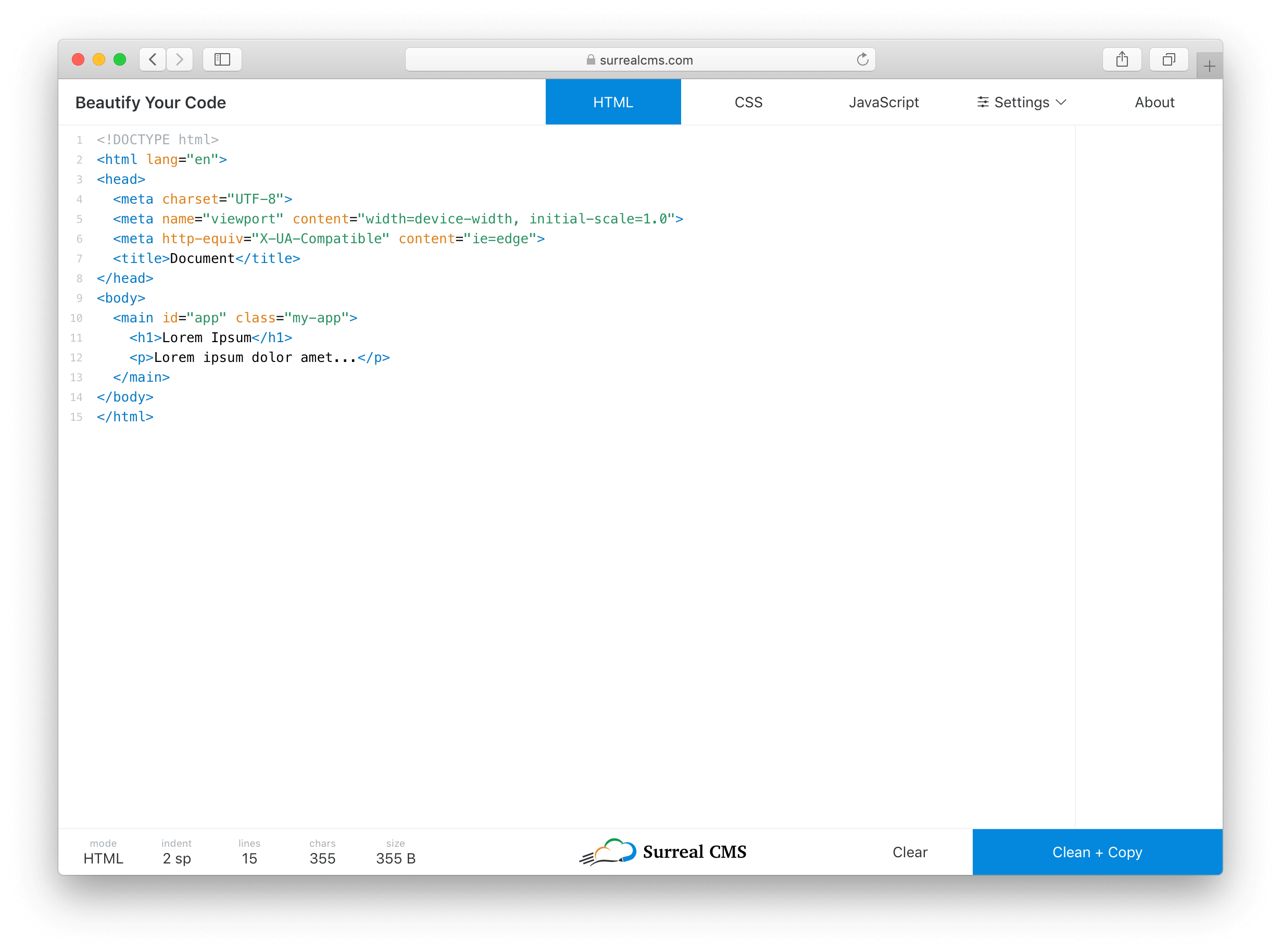
I knew I wanted the code editor to be the main focus of the tool, so I created a thin menu bar at the top that controls the mode (i.e. HTML, CSS, JavaScript) and settings. I eventually added an About button too.
The editor itself takes up most of the screen, but it blends in so you don't really notice it. Instead of wasting space with instructions, I used a placeholder that disappears when you start typing.
The Dark Mode UI is based on a toggle that updates the styles.
At the bottom, I created a status bar that shows live stats about the code including the current mode, indentation settings, number of lines, number of characters, and document size in bytes. The right side of the status bar has a "Clear" and "Clean + Copy" button. The center has a logo shamelessly plugging my own service.
I don't think many developers really code on phones, but I wanted this to work on mobile devices anyway. Aside from the usual responsive techniques, I had to watch the window size and adjust the tab position when the screen becomes too narrow.
I'm using flexbox and viewport units for vertical sizing. This was actually pretty easy to do with the exception of a little iOS quirk. Here’s a pen showing the basic wireframe. Notice how the textarea stretches to fill the unused space between the header and footer.
If you look at the JavaScript tab, you’ll see the iOS quirk and the workaround. I’m not sure how to feature detect something like this, so for now it’s just a simple device check.
Handling settings
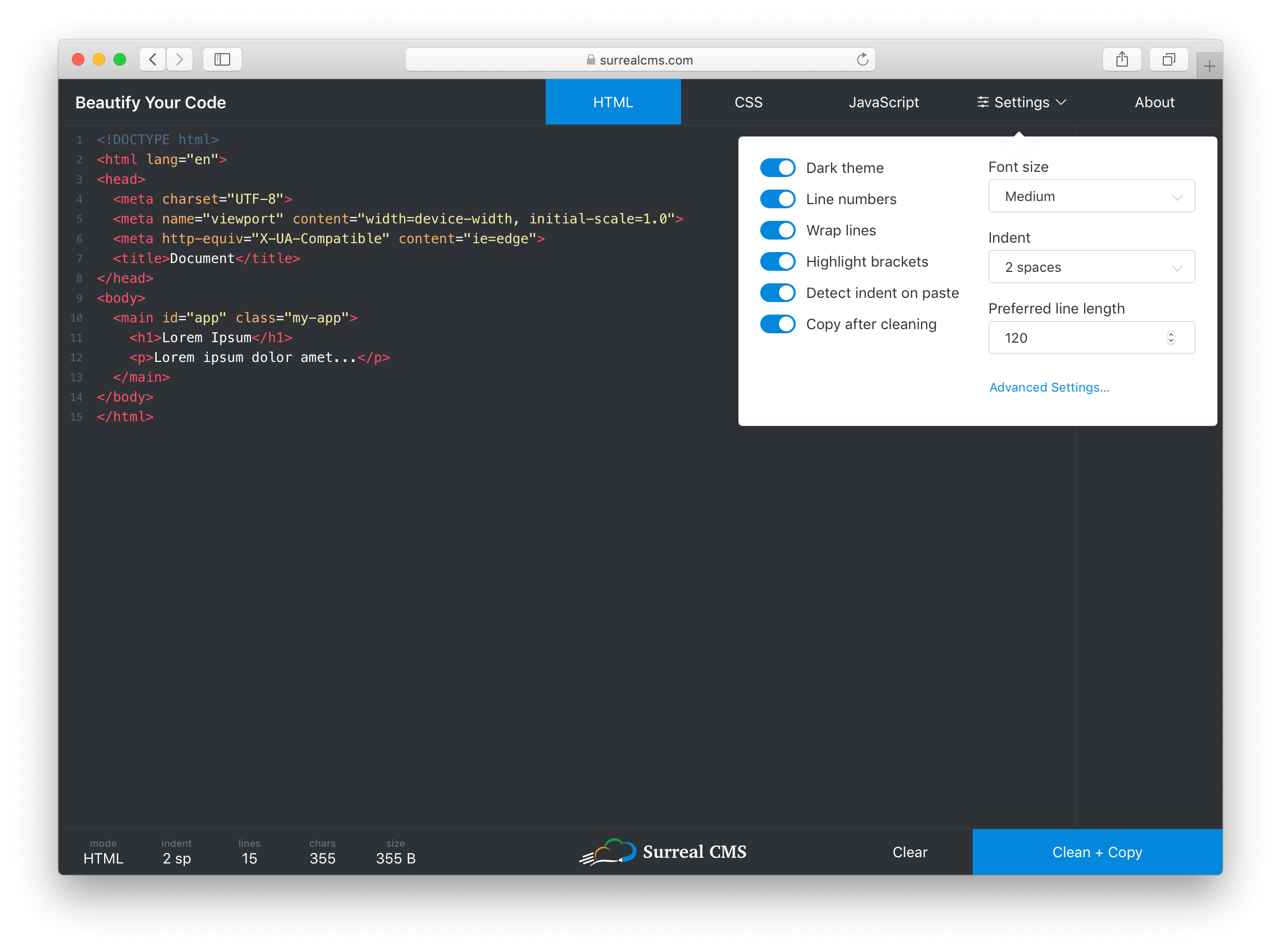
I wanted to keep the most commonly used settings easy to access, but also expose advanced settings for each mode. To do this, I made the settings button a popover with a link to more advanced settings inside. When a setting is changed, the UI updates immediately and the settings are persisted to localStorage.
The most common settings are contained in a small panel that provides quick access to them, while advanced settings are still accessible via a link in the panel.
I took advantage of Vue.js here. Each setting gets mapped to a data property, and when one of them changes, the UI updates (if required) and I call saveSettings(). It works something like this.
function saveSettings() {
const settings = {};
// settingsToStore is an array of property names that will be persisted
// and "this" is referencing the current Vue model
settingsToStore.map(key => settings[key] = this[key]);
localStorage.setItem('settings', JSON.stringify(settings);
}
Every setting is a data property that gets synced to localStorage. This is a rather primitive way to store state, so I might update the app to use a state management library such as Vuex later on.
To restore settings, I have a restoreSettings() function that runs when the app starts up.
function restoreSettings() {
const json = localStorage.getItem('settings');
if (json) {
try {
const settings = JSON.parse(json);
Object.keys(settings).forEach(key => {
if (settingsToStore.includes(key)) {
this[key] = settings[key];
}
});
} catch (err) {
window.alert('There was an error loading your previous settings');
}
}
}
The function fetches settings from localStorage, then applies them one by one ensuring only valid settings in settingsToStore get imported.
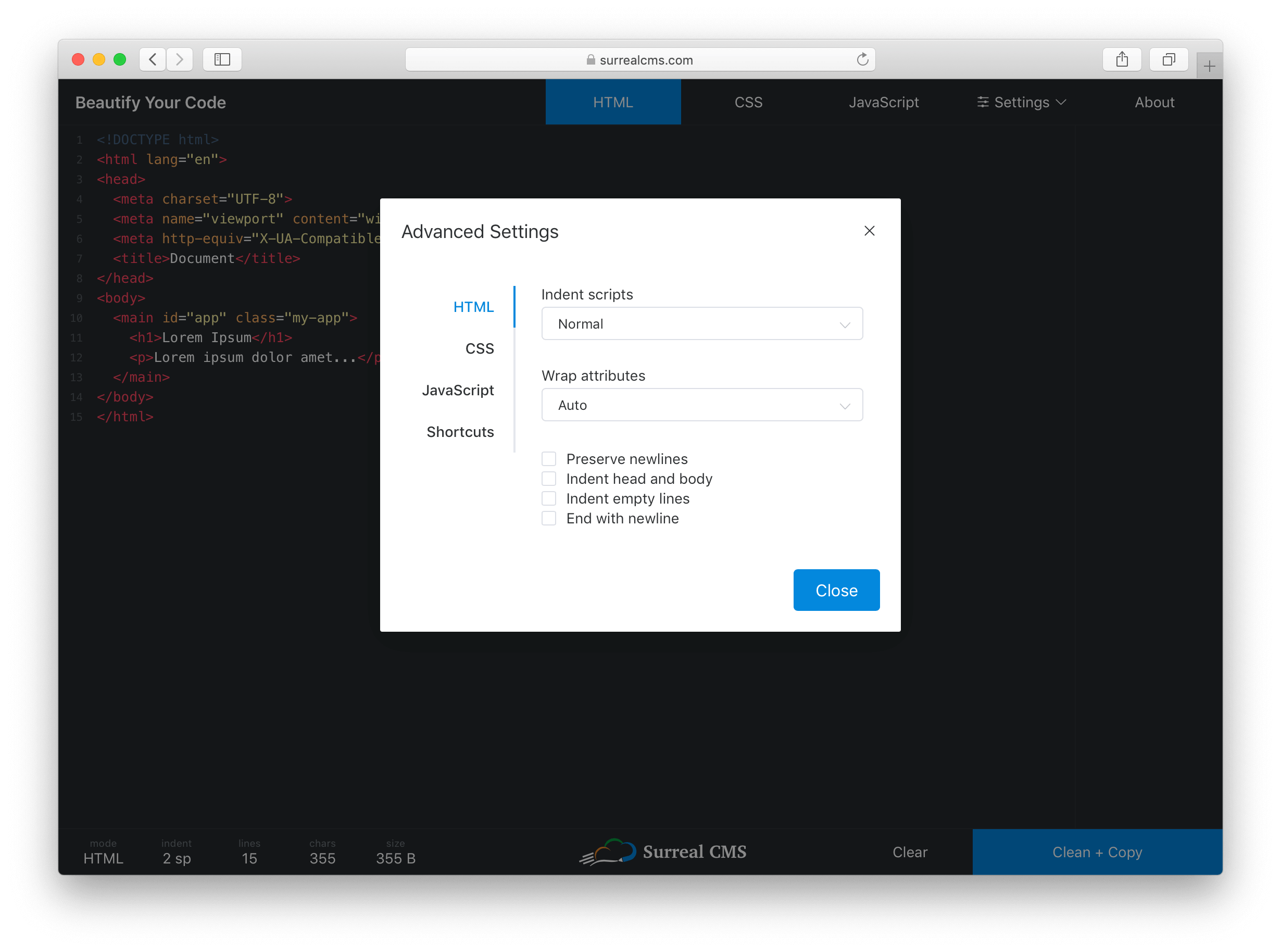
The Advanced Settings link opens a dialog with tabs for each mode. Despite having over 30 settings total, everything is organized and easy to access so users won't feel overwhelmed.
Clicking the "Advanced Settings" link opens up language-specific preferences and shortcuts.
Applying themes
Dark mode is all the rage these days, so it's enabled by default. There's also a light theme for those who prefer it. The entire UI changes, except for popovers and dialogs.
I considered using prefers-color-scheme, which coincidentally landed in Firefox 67 recently, but I decided a toggle would probably be better. Browser support for the color theme preference query isn't that great yet, plus developers are weird. (For example, I use macOS with the light theme, but my text editor is dark.)
The app with Light Mode UI enabled.
Defining features
Coming up with feature ideas is fairly easy. It’s limiting features for an initial release that’s hard. Here are the most relevant features I shipped right away:
Beautifies HTML, CSS, and JavaScript code
Syntax highlighting with tag/bracket matching
Paste or drop files to load code
Auto-detects indentation preference based on pasted code or dropped file
Light and dark themes
Clean and copy in one click
Keyboard shortcuts
Most JS Beautify options are configurable
Settings get stored indefinitely in localStorage
Minimal UI without ads (just an unobtrusive plug to my own service) 🙈
I also threw in a few easter eggs for fun. Try refreshing the page, exploring shortcuts, and sharing it on Facebook or Twitter to find them. 😉
The tools and libraries I used
I'm a big fan of Vue.js. It's probably overkill for this project, but the Vue CLI let me start building with all the latest tooling via one simple command.
vue create beautify-code
I didn't have to waste any time scaffolding, which helped me build this out quickly. Plus, Vue came in handy for things like live stats, changing themes, toggling settings, etc. I used various Element UI components for things like buttons, form elements, popovers, and dialogs.
The editor is powered by CodeMirror using custom styles. It’s a well-supported and fantastic project that I can’t recommend enough for in-browser code editing.
The library that does all the beautifying is called JS Beautify, which handles JavaScript, HTML, and CSS. JS Beautify runs on the client-side, so there’s really no backend to this app — your browser does all the work!
JS Beautify is incredibly easy to use. Install it with npm install js-beautify and run your code through the appropriate function.
import beautify from 'js-beautify';
const code = 'Your code here';
const settings = {
// Your settings here
};
// HTML
const html = beautify.html(code, settings)
// CSS
const css = beautify.css(code, settings)
// JavaScript
const js = beautify.js(code, settings)
Each function returns a string containing the beautified code. You can change how each language is output by passing in your own settings.
I’ve been asked a few times about Prettier, which is a comparable tool, so it’s worth mentioning that I chose JS Beautify because it’s less opinionated and more configurable. If there’s enough demand, I’ll consider adding an option to toggle between JS Beautify and Prettier.
I've used all of these libraries before, so integration was actually pretty easy. 😅
This project was made possible by my app, Surreal CMS. If you’re looking for a great CMS for static websites, check it out — it’s free for personal, educational, and non-profit websites!
Oh, and if you’re wondering what editor I used... it’s Visual Studio Code. 👨🏻💻
"Any information that can be named" ... "a document or image, a temporal service (e.g. “today’s weather in Los Angeles”), a collection of other resources, a non-virtual object (e.g. a person), and so on. In other words, any concept that might be the target of an author’s hypertext reference must fit within the definition of a resource. A resource is a conceptual mapping to a set of entities, not the entity that corresponds to the mapping at any particular point in time."
Defining a resource is both a science and an art. It requires both domain knowledge and API architectural skills. The following points detailed below serve as a checklist that may help you determine the shape of your resource, what data it should contain, and how it should be presented to consumers of your API.
In this article, I’ll show how to build a natural language interface for a typical home light switch so that you could turn the lights on and off with simple commands like Turn off all the lights, please, or Get the lights on in the kids bedroom.
We’ll concentrate on Natural Language Interface (NLI) part, and I’ll leave speech-to-text and the actual light controlling outside of the scope of this short blog. You can easily add speech-to-text with WebSpeech, if necessary, while Arduino/HomeKit can provide simple API to control the lights in your house.
To gather insights on the current and future state of API management, we asked IT professionals from 18 companies to share their thoughts. We asked them, "What techniques and tools are most effective for securing APIs?" Here's what they told us:
Authentication
We are frequently providing API access to known B2B partners. In these kinds of situations, the ability to limit API access to partner IP addresses only (whitelisting) is very powerful. You still need to authenticate and rate limit, but you have cut traffic to only known partners. This eliminates a great deal of the nefarious traffic that is seen on APIs open to the broader Internet such as brute force attempts to gain access and denial of service attacks.
Even with IP whitelisting in place, having an API gateway in place is still best practice. This aids in authentication and ensures the backend is only receiving properly formed API calls.
The most common is OAuth and OAuth2 for communicating and securing communications between APIs. Underneath is token-based and claims-based authentication where the APIs are passing digitally signed tokens back and forth to verify the token is representative of who is making the call.
Authentication is unevenly implemented by providers. Even with OAuth, the way tokens are persisted by others can be a problem. How is the lifecycle of tokens managed? Do the tokens get refreshed? Within our own infrastructure, we use one-time tokens heavily scoped to the type of operation we’re trying to do. It comes down to secure token management and certification-based authentication.
Always authenticate APIs before Authorizing — There are many ways to do API authentication, but multi-factor authentication is the commonly recommended approach. For APIs, it is pretty common to get access token using an external process e.g. through OAuth protocol. Authentication keys are most sensitive and must be kept secure; however, it is recommended that a management store be used to automate the whole process.
That said, authentication alone is not enough to grant access to an API, there should be an authorization step to determine what resources have access to the API. There various ways to check for proper authorization include content-based access control (CBAC), role-based access control (RBAC) or policy-based access control (PBAC) — these methods ensure business data remains fully protected against unapproved access.
Rate Limit
Securing the API environment involves every API touchpoint — authenticating and authorizing API clients (third‑party applications and developers or microservices), rate-limiting API calls to mitigate distributed denial-of-service (DDoS) attacks and protecting the backend applications that process the API calls.
Some techniques and tools for securing APIs are:
1) Using JSON Web Tokens (JWTs) in authenticating and authorizing API clients — these tokens include information about the client such as administrative privilege or expiration date. When the client presents a JWT with its API request, the API gateway validates the JWT and verifies that the claims in it match the access policy you have set for the resource the client is requesting.
2) Defining and implementing access control policies that allow only certain kinds of clients to perform write operations or access sensitive data such as pricing.
3) Defining Role-based access control that allows only certain users (such as developers within a specific org) to publish APIs that expose sensitive information such as pricing or inventory levels.
4) Securing the APIs themselves by applying a rate-limiting policy that sets a threshold on the number of requests the API gateway accepts each second (or other time period) from a specified source, such as a client IP address.
5) Protecting the backend applications using HTTPS — HTTPS protocol should be used traffic between API gateway and the backend systems that process the API requests.
Circuit Breakers - Throttling and Quotas — A good practice is to enforce per-app data usage quota so that the backend won’t be impacted in case of DoS, DDoS attacks or to prevent improper use of the API by unauthorized users. Throttling and quotas per resource not only act as a circuit breaker, but they can also prevent a negative impact on the downstream systems during an unwanted surge in usage. A sophisticated API management platform with policies like quotas and throttling can offer this capability.
Broader
Three key areas in our approach to API security:
1) Have a prescriptive approach
2) Think carefully about how application identities are connected to user identities
3) Think about API security in its broadest sense beyond authentication to mitigate intrusion attempts.
Prescriptive model: Customers move towards OAuth 2 and overlay with Open ID Connect. There are a lot of choices to be made with OAuth 2, Open ID restricts the choice and directs people on best practices. Ultimately, it’s better to implement a clearly understood standard. Look at a balance between security, usability, and scalability similar to the world of storage.
Roles of application and user identities: There is a number of API management vendors try to do both. It just isn’t scalable. Identity management is so robust you cannot keep up with the pace of change and new standard. We integrate with external identity management solutions and have full out of the box integration or OAuth2 and Open ID use cases. We have open interfaces for customers to swap us out for their own implementation if they want.
For broader security concerns: We take the approach of distributing implementation of security. By default, API management is focused on providing an API gateway. We take an approach that an API gateway should be focused on authentication and authorization of traffic. We recommend taking a multi-layered approach and include a web app firewall in a separate layer with Apache Mod Security. When deploying additional security to deploy to the network edge. The last is using heuristics or machine learning to monitor traffic behavior and determine if traffic is malicious.
Other
API management security is still one of the areas where people are struggling. We need to recognize that APIs are inherently insecure. We need to relearn what is security for APIs and understand the internet fragility that is being attacked. Cloud providers are more mature. AWS and Azure API management tools provide an additional security layer. Think about the security of the user name, password, keys, and know who is using your APIs. Think about the data now that APIs are exposing legacy systems have the same mindset for securing the data that is there. More APIs consume more user data — how and where do you store?
APIs can be a security risk in two key ways. First, as dependencies are like a set of Russian dolls. Inside your dependencies are the dependencies’ dependencies… and inside them your dependencies, dependencies’, dependencies’ and so on and so on. From a functionality perspective, this enables each development organization to focus on the code for which they add the most value.
However, from a security perspective, as the end consumer, you inherit the entire chain of vulnerabilities. Application security professions must go beyond basic software composition analysis, which matches known CVEs to version strings because they only go one layer deep. As an example, Jackson-databind is a popular open-source library that is leveraged in many 3rd party communications SDKs.
The “jacksploit” deserialization vulnerability, that has plagued many version of the library, was exploitable for some of the SDK users, but the vulnerable version of Jackson-databind was obfuscated and not identifiable by traditional SCA. Hence, security professionals must look for tools that evaluate how the source code works, rather than relying on looking up CVE databases.
Second, since APIs often pass data externally, it is important to map critical data flows to ensure critical data isn’t inadvertently leaked into them. This means identifying which variables are critical and mapping their journey from source to sink and all the transformations on the way. That way unencrypted or unredacted critical data can be caught in development before leaky routes are pushed into production.
You need to have good API management platform in place. It will enforce the rules and roles you put in place to control who has access to what data. You can use a gateway or platform with options or use built-in authentication and authorization tools. Being able to control access in a friendly, easy-to-configure way. The web interface is the best way to do and control who has access without requiring a deployment or digging into the server and update complex configuration or files. Control at the gateway level and then it's easy to configure or manage.
API security is important and requires a comprehensive approach to prevent data leakage. Because of the way data can be shared via API, users can inadvertently leak data in just a few clicks This occurs when employees authorize OAuth API connectivity between sanctioned apps and unsanctioned, third-party apps, granting the latter permissions to read and even write data (e.g. Email, Google Drive, Box, Office 365, and SharePoint). This functionality provides great business value but can expose data when not properly secured.
Structured data can be synced between apps via JSON, XML, or file-based APIs (to name a few). This structured data may contain sensitive information that should be protected with encryption or tokenization. In these scenarios, it’s critical to leverage a bring-your-own-key (BYOK) approach; this is because data is not truly secure if an encryption key is stored with the app that houses the encrypted data. Fortunately, leading multi-mode cloud access security brokers (CASBs) provide visibility and real-time protections for all of these use cases, ensuring data is secure on any app, any device, anywhere.
When it comes to securing APIs, serving them via HTTPS is a basic yet absolute requirement. It’s relatively straightforward to setup: the tools and processes involved are widely available and well understood. Moving away from the common username/password couple is also a practice we would recommend. Usernames are an easy target for social engineering. Passwords, while uses are evolving, are still too often created manually — constraining their size or composition leads to frustrating experiences. We prefer to go for API keys instead.
Our API keys have the form we devised. We can assign several API keys to the same customer. A single API key can be exchanged to several entities for a given customer. We can revoke API keys. All of this can be done independently from actual customer account management.
Enforce Encryption all the way — A fundamental security requirement is to encrypt the data using the latest cryptographic protocols to ensure proper protection while the data is in transit. Weak protocol version and ciphers should always be disabled. TLS1.0 and 1.1. Encryption in transit is great, but not enough. It should be enforced all the way, including while the data is at rest.
Audit and Logging — Auditing is usually an afterthought, whereas it should be considered as a feature during the API development cycle. The more logging the better, since the cost of having this capability far outweighs the cost of not having them when you need this capability the most (during the attack). Logging should be systematic and independent, and resistant to log injection attacks. Auditing should be used for detecting and proactively deterring attacks.
Alert and Monitoring — Alert and monitoring are key to see what is going on in your world to protect against bad behaviors. Logging and auditing should be used proactively in detecting and alerting you against threats and attack.
Protect HTTP Verbs and Cross-Site Request Forgery (CSRF) — It is common with APIs to allow multiple methods for a URL for different operations. For example, a GET request to read data, PUT to update data, POST to create data, and DELETE to delete data. It is important for the APIs to restrict the allowed HTTP verbs so that only the allowed methods will work, while the others will result in an exception along with a proper response code sent back to the client. It is important for PUT, POST, and DELETE methods to be protected from Cross-Site Request Forgery (CSRF). Typically one would use a token-based approach to enforce this capability.
There's an external way and an internal way. External SSL or TLS for encryption, make sure traffic is secure and encrypted. Make sure the client and server are both SSL. Make sure you are encrypting data. Know who the person is that’s calling the application – OAuth, OpenID connect. The last one is securely based on who you are. External is a web application firewall to scan the request and make sure nothing is suspicious. Internally see other stuff like after already past the gateway two microservices talking to each other with MTLS. Limit the audience of the job. Only give permission to go to a certain place. Identity management.
Because we’ve taken microservices to their logical extreme, with each team producing APIs on the public internet for direct consumption, we don’t have the benefit of a gateway as a chokepoint for access. In our world, there’s no such thing as a “backend API.” That makes securing our APIs an especially diffuse problem, but it also means no one in our company relies on a false sense of security built on assumptions that only the “right” callers can reach their APIs.
As a result, every team is responsible for the security of their APIs, and we achieve this by following a few key principles:
1) Every caller (human or programmatic) authenticates using the same standard (OAuth2 bearer tokens in the form of JWTs signed by our identity vendor, Auth0)
2) Every API validates the identity and access rights of the caller for each action
3) Every API presents the original caller’s credentials for subsequent requests it must make to our APIs
In this way, every API knows exactly who initiated a call chain and can accurately reason about the access rights of the caller. These techniques have served us well as every developer has the same expectations and responsibilities for securing access. We haven’t found great tooling to automate security testing. We have found that human ingenuity and vigilance are always necessary.
We use crowdsourced testing services for an external perspective but also empower internal teams to red flag, up to the highest levels of the organization, any security issues they identify in anyone’s APIs. The latter works particularly well because, again, we’re all responsible for the security of APIs exposed on the public internet, so every developer has a well-honed sense for good and bad practices.
For RESTful APIs — OAuth2 and JWT are pretty much de-facto standard. We use both. OAuth from customer to our cloud-platform and JWT internally for performance benefits. With the growing popularity of Webhooks, it is a must to sign your payloads when customers “sign-up” for API notifications.
We use HMAC signatures so customers can confirm data is coming from us and hasn’t been altered. I’m surprised how frequently we encounter API providers who are still not doing that. We use more advanced measures on some occasions, but those are sufficient for most cases.
You also have to have some sort of single API entry point before API calls hit your microservices or monolith applications. Normally this is an API gateway that will block any calls very fast if they haven’t been properly authenticated.
Most security issues result from too much complexity and too many APIs. Simplicity is key, with all data security being handled centrally so there is one place to keep it current. Protocols like GraphQL and SPARQL allow consumers to describe their own data needs through a single API, substantially minimizing the need for so many APIs to manage to begin with.
Restrict the list of users that are authorized to access the token. Token-based authorization is there for a reason. Second, there’s a need to track and control the use of resources allocated for a single user, which is absolutely essential to protect from DDoS attacks.
The Apollo GraphQL language received a major upvote from Netflix, reports TechTarget’s SearchMicroservices news writer Darryl K. Taft. At the 2019 QCon New York conference, Garrett Heinlen, a Netflix software engineer, said that GraphQL and TypeScript are now used as foundational technologies in the company's new data integration system.
To understand the current and future state of the cybersecurity landscape we spoke to, and received written responses from, 50 security professionals. We asked them, "What are some use cases you’d like to highlight?"
While we covered application use cases in the previous article, here's what they told us about use cases in different industries.
To understand the current and future state of the cybersecurity landscape we spoke to, and received written responses from, 50 security professionals. We asked them, "What are the most common security fails you see today?"
In Part 1, the lack of fundamentals, training, and vision were covered. In Part 2, a lack of strategy, up-to-date technology and tools, patching and data best practices were provided. The following are the responses that fell into the "other" category:
As a flexible content management system that’s here to stay, WordPress is an excellent place to set up your online community. However, you may only be accustomed to using the platform for blogging, and not sure how to best adapt it for a community website. Fortunately, you can create just about any type of online […]
You’ve started your online business, and it starts doing well after some time, but have you checked your business website compatibility across all the browsers that visitors use to access it?
This tutorial shows you how to quickly deploy a Grafana application in KubeSphere via an Application Template, demonstrating the basic functionality of the application repository, application templates, and application management.
This article is the first in the series where we are going to build a simple ASP.NET Core web application, containerize it with Docker and run it on the local host. And we will push everything to GitHub for later use.
In later posts, we will set up a Microsoft Azure DevOps Build pipeline to automate the process of building and pushing the Docker image to Docker Hub. Next, we will use Azure DevOps Release pipeline to deploy our application on Azure Web App Service as a container.
Why do people go for Docker? Though we have many container technologies, people preferred Docker for one reason: Docker made great leaps in the simplification of containers. It was always hard implementing containers in an organization before Docker.
Is Docker the only container technology? Can we create a container without Docker? This article talks about how we can create containers without Docker
Change has always been at the center of mankind's evolution, mapping the journey since the primitive era to this digital age. Continuous experimentation, trials and errors, continuous improvement and integration into everyday life, and then the continuous distribution of the experimented, adapted technology has led us to where we stand today. From simply surviving on necessities to building a life of luxury and convenience, mankind has surely come a long way. The extent to which we have evolved, the distance that we have traversed, has brought us to the point of advancement where we exist physically but survive digitally.
Evolution has been the only constant over the centuries of our existence. But what makes digital transformation so revolutionizing is its capability of bridging the difference between physical and digital. When a snake sheds its skin, it changes; when a caterpillar becomes a butterfly, it transforms. Digital transformation is metamorphosizing every industry into a winged butterfly. But, if done wrong, you'll only have a really fast caterpillar who may complete the designated tasks much faster, but at the cost of quality and efficiency. This is where continuous testing takes the reins — to ensure that your organization truly transforms into an enterprise capable of delivering excellent customer satisfaction rapidly.
Selenium is a tool that allows you to automate browser actions. It is often used by QA engineers to automatically and efficiently test the functionality of web applications. You can create Selenium scripts that examine specific functionality of a web application, ensuring that it produces the expected results.
One of the types of pages that you need to test in the case of most web applications are login pages. Selenium scripts are often used to ensure that changes in the web application do not break the login functionality. These Selenium scripts can now be converted and used by Acunetix to log into the site as part of the security scan.
The way that we develop and deliver software has changed dramatically in the past five years — but the metrics we use to measure quality remain largely the same. Despite seismic shifts in business expectations, development methodologies, system architectures, and team structures, most organizations still rely on quality metrics that were designed for a much different era.
Every other aspect of application delivery has been scrutinized and optimized as we transform our processes for DevOps. Why not put quality metrics under the microscope as well?
When teams adopting DevOps ask me, “What should we measure to know that we’re improving?” I have reflexively rattled off the metrics from Accelerate.
Throughput
Deployment frequency (frequency an app is released)
Lead Time (time from code commit to working in prod)
Stability
Change failure rate (changes requiring a subsequent fix or causing outage)
Time to restore (typical restoration time when an outage occurs)
These broadly make sense and point to a high degree of automated deployment, testing, and robust monitoring. These tenants of DevOps have been helpful. The State of DevOps Report shows that strong performers in these areas outperform their competition in the market. The reality of that is something I have wagered on and won.
This isn’t our first rodeo! I started ARTIFACT back in 2013 with Christopher Schmitt and Ari Stiles (the team behind the legendary In Control and CSS Dev conferences). At that time, the sudden avalanche of web-enabled mobile devices was throwing the web design community for a loop. How do we best leverage the recently-introduced Responsive Design techniques to adapt our designs to a spectrum of screen sizes?! What does that do to our workflows?! What happens to our beloved Photoshop comps?! How do we educate our clients and structure our billing cycles?! It was an exciting time when we needed to adjust our processes quickly to take on a radically new web viewing environment.
After four events in 2013 and 2014, ARTIFACT took a little hiatus, but we are back for a five-year reunion in 2019. We are returning to a landscape where a lot of the challenges we faced in 2013 have been figured out or, at the very least, have settled down (although there is always room for innovation and improvement).
Is our work making the web better done? Not by a long shot! Now that we’ve got a handle on the low-bar requirement of getting something readable on all those screens, we can focus our energy on higher-order challenges. How do we make our sites work easier for people of all abilities? How do we make our content, products, and services welcoming to everyone? Does our code need to be so bloated and complicated? How can we make our sites simpler and faster? How can I put new tools like CSS Grid, Progressive Web Apps, static sites, and animation to good use?
To that end, this time around ARTIFACT is expanding its focus from “designing for all the devices” to “designing for all the people.” Simply put, we want a web that doesn’t leave anyone out, and we’ve curated our program to address inclusivity, performance, and the ways that new possibilities on the web affect our workflow.
A web for everyone
Inclusive design—including accessibility, diversity, and internationalization—has been bubbling to the top of the collective consciousness of the web-crafting community. I’m incredibly encouraged to see articles, conference talks, and podcasts devoted to improving the reach of the web. At ARTIFACT, inclusivity is a major theme that winds its way throughout our program.
Photo by Jopwell from Pexels
Benjamin Evans will talk about his efforts as the Inclusive Design Lead at AirBnB to create a user experience that does not alienate minority communities.
Accessibility expert Elle Waters will share best practices for integrating accessibility measures into our workflows..
We’ll also hear from David Dylan Thomas on how to recognize and address cognitive bias that can affect content and the overall user experience.
Even better performance
Visitors may also be turned away from our sites if pages take too long to load or use too much data. We know performance matters, yet sites on the whole grow more bloated with every passing year. Tim Kadlec (who knows more about performance than just about anybody) will examine the intersection of performance and inclusion in his talk “Outside Looking In” with lots of practical code examples for how to do better.
We’ll also look at performance through the lens of Progressive Web Apps (presented by Jason Grigsby of Cloud Four). In fact, improving performance is a subtext to many of our developer-oriented talks.
Leveraging the modern browser
In the Good News Department, another big change since the first ARTIFACT is that browsers offer a lot more features out of the box, allowing us to leverage native browser behavior and simplify our code (Viva Performance!). Chris Ferdinandi will be demonstrating exactly that in his talk “Lean Web Development,” where he’ll point out ways that taking advantage of built-in browser functionality and writing JavaScript for just the interactivity you need may make a big framework unnecessary.
Better native browser features also means un-learning some of our old coping mechanisms. We’ll get to delight at all the polyfills and workarounds that have been kicked to the curb since 2012 in Dave Rupert’s tale of “The Greatest Redesign Ever Told,” and we’ll see what best practices make sense going forward.
Workflow and process
One thing that hasn’t changed—and likely never will—is that never-ending hamster wheel of trying to keep up with an ever-changing web development landscape. I’m guessing that if you are reading CSS-Tricks right now, you know that feeling. The methods we use to build the web are always evolving with new tools, approaches, and possibilities, which is why best practices for adapting our workflows and processes have always been a central focus at ARTIFACT. This year is no different. Jen Simmons will share her thinking process for designing a CSS grid-based layout by live-coding a site before our very eyes.
Design systems, which have become a cornerstone of large-scale site production, get the treatment in talks by Kim Williams, Dan Mall, and Brad Frost. (Dan and Brad are also running their acclaimed “Designer + Developer Collaboration Workflow” workshop on October 3.)
Divya Sasidharan will show off the possibilities and performance advantages of static sites in her “JAMstackin” presentation
We’ll get a glimpse of the future of web animation from Sarah Drasner. (She’s bringing her popular “Design for Developers” workshop on October 3 as well).
The web can always do better to serve the people who use it. We’re proud to provide an occasion for designers and developers who care about putting their users front and center to mingle and share ideas. And yes, there will be milkshakes! The very best milkshakes.


 As a flexible content management system that’s here to stay, WordPress is an excellent place to set up your online community. However, you may only be accustomed to using the platform for blogging, and not sure how to best adapt it for a community website. Fortunately, you can create just about any type of online […]
As a flexible content management system that’s here to stay, WordPress is an excellent place to set up your online community. However, you may only be accustomed to using the platform for blogging, and not sure how to best adapt it for a community website. Fortunately, you can create just about any type of online […]










