i have 1 function that give me an array of a line points...
on these array, how can i get the array size without using the UBound() and LBound()?
VB6: how we get an array size?


Tips, Expertise, Articles and Advice from the Pro's for Your Website or Blog to Succeed
i have 1 function that give me an array of a line points...
on these array, how can i get the array size without using the UBound() and LBound()?
Knowing what you can and can't automate is important, but the real question is: Can you automate yourself out of a job?
On this week’s episode I brought in tenured software engineer and automation expert Judy Johnson to answer my questions about automation. In this episode Judy helps me answer questions like:
Jonathan Desrosiers, a WordPress core committer and software engineer at Bluehost, has published a new workshop titled “How to Use Trac” on the Learn WordPress platform. The 20-minute video offers a crash course on the ticket tracking software that WordPress relies on to manage core development. Trac is also used for contributing to WordPress’ meta component, which includes WordPress.org sites and API, directories, support areas, and other projects.
Trac’s antiquated UI can be intimidating for newcomers, posing another barrier to contribution. Even experienced WordPress contributors are eager to move core development to GitHub or some other platform. It can get confusing since bugs related to the editor need to be reported on GitHub instead of Trac. Until WordPress adopts another platform, the ability to navigate Trac remains an important skill.
Desrosiers’ workshop covers topics like searching for pre-existing tickets before reporting a new issue, how to write a good bug report or feature request, how to identify component maintainers, attaching patches, and how proper classification of the ticket can help other teams get involved. He also helps workshop students understand ticket resolutions so they can frame their expectations accordingly. This video includes a full walkthrough of creating a new ticket where Desrosiers explains each field on the form.
Once you get up to speed on learning Trac and start contributing, you may also want to follow the WordPress Trac on Twitter. New contributors may also want to explore WPTracSearch, an unofficial project that provides an alternative Elasticsearch-powered interface for searching WordPress Trac tickets. WPTracSearch delivers more accurate results, even for basic queries, that can be filtered based on milestone, component, focuses, usernames, and more criteria.
When developing an application for only one client or only a single version, the main subjects you focus on are how to implement the features, security, performance, design, time to market, etc. What will happen if the number of clients increases, and each one of them has different requests that contradict each other? Are we going to duplicate our codebase and have different apps, which we have to implement common features to every instance separately? Or are we going to manage them from one codebase?
Diversity in labels might be managed with different property files, but will this be enough for all kinds of requests? The flow in the logic might be directed with control blocks. What will happen to them when you have 100 different clients? What will happen to the readability/manageability of the code? We might decide to extract the logic that differs from one client to another and have multiple microservices. This will allow us to have clean code, but will we be able to turn all the logic that differs from client to client into microservices? Is our structure suitable for this process? How about managing and deploying all those services? Is it worth the cost?
Automation is one of the fundamental components that makes Kubernetes so robust as a containerization engine. Even complex cloud infrastructure creation can be automated in order to simplify the process of managing cloud deployments. Despite the capability of leveraging so many resources and components to support an application, your cloud environment can still be fairly manageable.
Despite the many tools available on Kubernetes, the effort to make cloud infrastructure management more scalable and automated is ongoing. Kubernetes operator is one of the tools designed to push automation past its limits. You can do so much more without having to rely on manual inputs every time.
For some people, Christmas arrived a couple of days early. Gutenberg 9.6 launched with its first iteration of drag-and-drop blocks from the inserter. There are some other enhancements like vertical buttons, heaps of bug fixes, new APIs, and other improvements. But, let’s be real. The ability to drag blocks from the inserter into the content canvas is the highlight of this release.
Another key feature is that the Query block, which is only available when Full Site Editing is enabled, now inherits from the global query arguments. As has been usual as of late, much of the work in the Gutenberg plugin has focused on improving the site editor.

Perhaps the Gutenberg development team has seen your comments and your other comments. If there is one common thread among the comments on our Gutenberg-related posts, it is that a segment of the WordPress user base wants more drag-and-drop capabilities.
The new feature only works with blocks right now. Users cannot yet drag and drop patterns from the inserter.
After several tests since Gutenberg 9.6 Release Candidate 1 landed last week, I have had no issues with it. For the most part, the experience felt smooth and easy to use.
I have never seen the allure of drag-and-drop features in a content editor. If I am not typing in Markdown, I am in the WordPress editor and using keyboard shortcuts. Throughout my career, I have either been writing code or writing words daily. Picking up my fingers from the keyboard only serves to waste time.
Sometimes I forget that the block editor already has some drag-and-drop capabilities available, which allow end-users to move blocks from one position to another in the canvas. I tend to work with the top toolbar enabled, so I rarely see the feature.
Nevertheless, I do see how dragging and dropping blocks could be useful to some users. I use them in other types of editors, such as Gimp or Photoshop, at times. The one thing I like about those is the toolset is always available in the sidebar. This is not the case with the block inserter. While it will stay open for users to drag multiple elements into their content, it disappears once users begin working elsewhere. That could become irritating if the user is in more of a visual-design workflow instead of a content-editing mode.
Dragging blocks from the inserter would make more sense for my workflow in the upcoming site editor rather than the post editor. The feature works great in that context too.
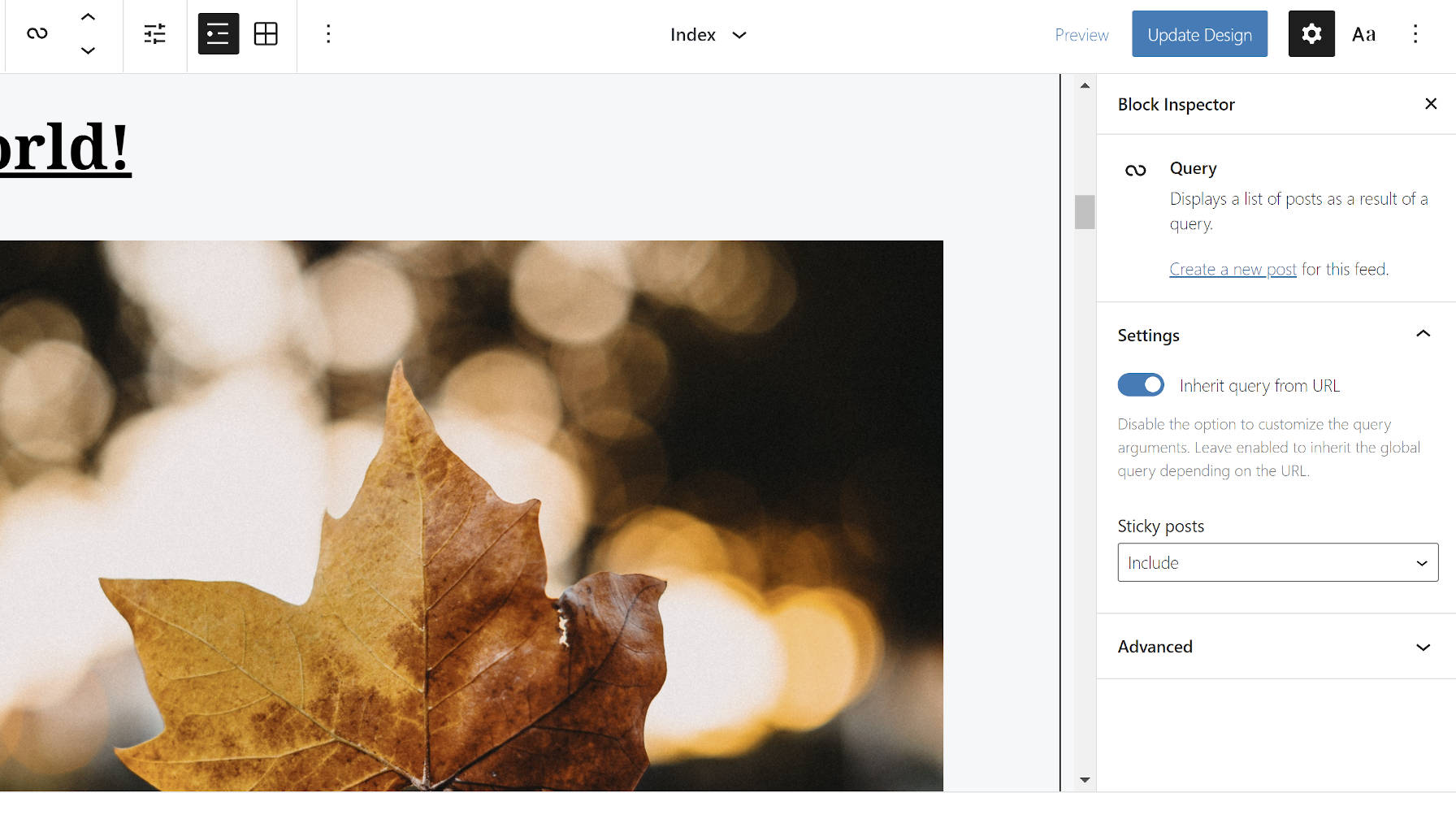
The low-key star of this release is an update to the Query block, which is only available when using a block-based theme. The update is one of the most important breakthroughs for Full Site Editing, a pivotal moment in the history of the Gutenberg project.
In previous iterations, the Query block required that themes via their block templates or end-users via the site editor define which posts to display. While that is a necessary function of the block, the missing piece was the global query support.
In the simplest terms, whatever URL a visitor lands upon tells WordPress which posts to load. The data for loading these posts is all stored in a global set of query arguments. Themes can then loop through these posts to display them.
In Gutenberg 9.6, the Query block can now inherit these query arguments. This means that things like the blog posts page, category archives, search results, and more will display the correct posts when someone visits one of those specific URLs.
On the surface, this change merely adds a single option to the interface. However, under the hood, it is a achievement that clears a gaping path for developing block-based themes.
If you’re like most developers, you don’t have a ton of spare time (and perhaps also not much desire) to learn how to create and maintain Kubernetes objects. Where developers are required to manage Kubernetes, slower application delivery is often the result. In these scenarios, platform and DevSecOps teams must also work to support developers’ Kubernetes efforts, and cope with ever-greater chances that deployed applications will suffer from misconfigured objects. Platform teams are usually tasked with creating an extra platform layer as well, adding to costs and making maintenance and scaling more difficult (while also increasing the potential for failure).
Take a scenario in which you deploy a single 3-tier application. This requires maintaining a dozen Kubernetes objects, creating a container image of your application, and optimizing the container OS for storage, security, compliance, and more. Enterprise IT must carefully consider the time it takes for developers to deploy and operate the application, scale clusters, and create Kubernetes objects and YAML files. They must also factor in the tools they use for security monitoring, the frequency with which they must write Ansible and Terraform scripts, and whether they have time to focus on cloud infrastructure APIs.
Every day, the ProgrammableWeb team is busy, updating its three primary directories for APIs, clients (language-specific libraries or SDKs for consuming or providing APIs), and source code samples.
One of the most common issues that we usually tackle with customers when modernizing legacy integrations is when they have a collection of legacy SOAP web services that don't integrate well enough with the modern RESTful-based clients.
In this article, we are going to use Apache Camel to build a REST endpoint that will translate REST calls to a SOAP envelope, get the response, and send it back to the client.
If someone told you that the following C++ function would cause the program to crash, what would you think it is that caused the problem?
xxxxxxxxxx
std::string b2s(bool b) {
return b ? "true" : "false";
}
Even though GitHub Readme files (typically ./readme.md) are Markdown, and although Markdown supports HTML, you can’t put <style> or <script> tags init. (Well, you can, they just get stripped.) So you can’t apply custom styles there. Or can you?
<img src="./file.svg" alt="" /> (anywhere).<text> for textual content, but also <foreignObject> for regular ol’ HTML content. <style> tags.readme.md file does support <img> with SVG sources. Sindre Sorhus combined all that into an example.
That same SVG source will work here:

The post Custom Styles in GitHub Readme Files appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
Recently, I gave a talk at Agile Testing Days called “How to Keep Testers Motivated.” This topic is one that’s close to my heart because as COO, I manage all of Abstracta’s operations that rely on the effort of more than 100 software testers. Therefore, the motivation of the people working with us is a key factor to success: the company’s success, the different teams’ success, and their personal success.
I remember last year during the TestingUY conference in Uruguay, Melissa Eaden was answering a question from the audience and she said that everyone can do testing, but only a tester does good testing. I fully agree with her, but I like to add a little detail to this affirmation, which is that only a motivated tester does good testing.
In many domains, the transfer of static and batch files is an important part of systems integrations and a large number of applications produce and expect data in the form of files rather than network-based APIs. In this article, we shall see how Zato makes multi-protocol integrations of this kind possible in a way that is secure, scalable and easy to extend in Python.
File transfer is often found in scenarios such as:
Hi Everyone!
I am new here, and the main purpose of joining this community is getting some help. Actually, I am designing a PHP website where I need to fetch US vehicles data into PHP. I have already used this source to get the vehicle's dataset from here https://www.back4app.com/database/back4app/car-make-model-dataset. Still, now my client wants to include images, and according to my team we should consider a source which provides both images and other details dataset into PHP.
I have done much research but unable to find such a source. I also found Teoalida's dataset very useful I am not sure either it provides images or not. Please share car dataset that also includes images in PHP format. I am also thinking to use Kaggle Datasets from here https://www.kaggle.com/datasets but I am not sure about images.
Any suggestions?
The now popular Agile methodology, with Scrum methodologies being popular cousins to Agile, has taken off since the publication of the Agile Manifesto in 2001. Many things changed with the coronavirus, however, as remote working became one solution for the current problem. This imposed changes in the current approach of managing Agile teams. Since these teams work based on close groups and one location, the main challenge is to keep the same productivity level in a sudden transition.
Agile teamwork enables direct contact, immediate communication, and problem solving. This will speed up the decision-making process, allowing for better fact-based decisions. Agile teams that don’t have experience with remote working will find the sudden change difficult. The new approach will decrease cohesion and, therefore, obstruct the whole process.
Lighthouse is a free and open-source tool for assessing your website’s performance, accessibility, progressive web app metrics, SEO, and more. The easiest way to use it is through the Chrome DevTools panel. Once you open the DevTools, you will see a “Lighthouse” tab. Clicking the “Generate report” button will run a series of tests on the web page and display the results right there in the Lighthouse tab. This makes it easy to test any web page, whether public or requiring authentication.

If you don’t use Chrome or Chromium-based browsers, like Microsoft Edge or Brave, you can run Lighthouse through its web interface but it only works with publicly available web pages. A Node CLI tool is also provided for those who wish to run Lighthouse audits from the command line.
All the options listed above require some form of manual intervention. Wouldn‘t it be great if we could integrate Lighthouse testing in the continuous integration process so that the impact of our code changes can be displayed inline with each pull request, and so that we can fail the builds if certain performance thresholds are not net? Well, that’s exactly why Lighthouse CI exists!
It is a suite of tools that help you identify the impact of specific code changes on you site not just performance-wise, but in terms of SEO, accessibility, offline support, and other best practices. It’s offers a great way to enforce performance budgets, and also helps you keep track of each reported metric so you can see how they have changed over time.
In this article, we’ll go over how to set up Lighthouse CI and run it locally, then how to get it working as part of a CI workflow through GitHub Actions. Note that Lighthouse CI also works with other CI providers such as Travis CI, GitLab CI, and Circle CI in case you prefer to not to use GitHub Actions.
In this section, you will configure and run the Lighthouse CI command line tool locally on your machine. Before you proceed, ensure you have Node.js v10 LTS or later and Google Chrome (stable) installed on your machine, then proceed to install the Lighthouse CI tool globally:
$ npm install -g @lhci/cliOnce the CLI has been installed successfully, ru lhci --help to view all the available commands that the tool provides. There are eight commands available at the time of writing.
$ lhci --help
lhci <command> <options>
Commands:
lhci collect Run Lighthouse and save the results to a local folder
lhci upload Save the results to the server
lhci assert Assert that the latest results meet expectations
lhci autorun Run collect/assert/upload with sensible defaults
lhci healthcheck Run diagnostics to ensure a valid configuration
lhci open Opens the HTML reports of collected runs
lhci wizard Step-by-step wizard for CI tasks like creating a project
lhci server Run Lighthouse CI server
Options:
--help Show help [boolean]
--version Show version number [boolean]
--no-lighthouserc Disables automatic usage of a .lighthouserc file. [boolean]
--config Path to JSON config fileAt this point, you‘re ready to configure the CLI for your project. The Lighthouse CI configuration can be managed through (in order of increasing precedence) a configuration file, environmental variables, or CLI flags. It uses the Yargs API to read its configuration options, which means there’s a lot of flexibility in how it can be configured. The full documentation covers it all. In this post, we’ll make use of the configuration file option.
Go ahead and create a lighthouserc.js file in the root of your project directory. Make sure the project is being tracked with Git because the Lighthouse CI automatically infers the build context settings from the Git repository. If your project does not use Git, you can control the build context settings through environmental variables instead.
touch lighthouserc.jsHere’s the simplest configuration that will run and collect Lighthouse reports for a static website project, and upload them to temporary public storage.
// lighthouserc.js
module.exports = {
ci: {
collect: {
staticDistDir: './public',
},
upload: {
target: 'temporary-public-storage',
},
},
};The ci.collect object offers several options to control how the Lighthouse CI collects test reports. The staticDistDir option is used to indicate the location of your static HTML files — for example, Hugo builds to a public directory, Jekyll places its build files in a _site directory, and so on. All you need to do is update the staticDistDir option to wherever your build is located. When the Lighthouse CI is run, it will start a server that’s able to run the tests accordingly. Once the test finishes, the server will automatically shut dow.
If your project requires the use of a custom server, you can enter the command used to start the server through the startServerCommand property. When this option is used, you also need to specify the URLs to test against through the url option. This URL should be serveable by the custom server that you specified.
module.exports = {
ci: {
collect: {
startServerCommand: 'npm run server',
url: ['http://localhost:4000/'],
},
upload: {
target: 'temporary-public-storage',
},
},
};When the Lighthouse CI runs, it executes the server command and watches for the listen or ready string to determine if the server has started. If it does not detect this string after 10 seconds, it assumes the server has started and continues with the test. It then runs Lighthouse three times against each URL in the url array. Once the test has finished running, it shuts down the server process.
You can configure both the pattern string to watch for and timeout duration through the startServerReadyPattern and startServerReadyTimeout options respectively. If you want to change the number of times to run Lighthouse against each URL, use the numberOfRuns property.
// lighthouserc.js
module.exports = {
ci: {
collect: {
startServerCommand: 'npm run server',
url: ['http://localhost:4000/'],
startServerReadyPattern: 'Server is running on PORT 4000',
startServerReadyTimeout: 20000 // milliseconds
numberOfRuns: 5,
},
upload: {
target: 'temporary-public-storage',
},
},
};The target property inside the ci.upload object is used to configure where Lighthouse CI uploads the results after a test is completed. The temporary-public-storage option indicates that the report will be uploaded to Google’s Cloud Storage and retained for a few days. It will also be available to anyone who has the link, with no authentication required. If you want more control over how the reports are stored, refer to the documentation.
At this point, you should be ready to run the Lighthouse CI tool. Use the command below to start the CLI. It will run Lighthouse thrice against the provided URLs (unless changed via the numberOfRuns option), and upload the median result to the configured target.
lhci autorunThe output should be similar to what is shown below:
✅ .lighthouseci/ directory writable
✅ Configuration file found
✅ Chrome installation found
⚠️ GitHub token not set
Healthcheck passed!
Started a web server on port 52195...
Running Lighthouse 3 time(s) on http://localhost:52195/web-development-with-go/
Run #1...done.
Run #2...done.
Run #3...done.
Running Lighthouse 3 time(s) on http://localhost:52195/custom-html5-video/
Run #1...done.
Run #2...done.
Run #3...done.
Done running Lighthouse!
Uploading median LHR of http://localhost:52195/web-development-with-go/...success!
Open the report at https://storage.googleapis.com/lighthouse-infrastructure.appspot.com/reports/1606403407045-45763.report.html
Uploading median LHR of http://localhost:52195/custom-html5-video/...success!
Open the report at https://storage.googleapis.com/lighthouse-infrastructure.appspot.com/reports/1606403400243-5952.report.html
Saving URL map for GitHub repository ayoisaiah/freshman...success!
No GitHub token set, skipping GitHub status check.
Done running autorun.
The GitHub token message can be ignored for now. We‘ll configure one when it’s time to set up Lighthouse CI with a GitHub action. You can open the Lighthouse report link in your browser to view the median test results for reach URL.

Using the Lighthouse CI tool to run and collect Lighthouse reports works well enough, but we can go a step further and configure the tool so that a build fails if the tests results do not match certain criteria. The options that control this behavior can be configured through the assert property. Here’s a snippet showing a sample configuration:
// lighthouserc.js
module.exports = {
ci: {
assert: {
preset: 'lighthouse:no-pwa',
assertions: {
'categories:performance': ['error', { minScore: 0.9 }],
'categories:accessibility': ['warn', { minScore: 0.9 }],
},
},
},
};The preset option is a quick way to configure Lighthouse assertions. There are three options:
lighthouse:all: Asserts that every audit received a perfect scorelighthouse:recommended: Asserts that every audit outside performance received a perfect score, and warns when metric values drop below a score of 90lighthouse:no-pwa: The same as lighthouse:recommended but without any of the PWA auditsYou can use the assertions object to override or extend the presets, or build a custom set of assertions from scratch. The above configuration asserts a baseline score of 90 for the performance and accessibility categories. The difference is that failure in the former will result in a non-zero exit code while the latter will not. The result of any audit in Lighthouse can be asserted so there’s so much you can do here. Be sure to consult the documentation to discover all of the available options.

You can also configure assertions against a budget.json file. This can be created manually or generated through performancebudget.io. Once you have your file, feed it to the assert object as shown below:
// lighthouserc.js
module.exports = {
ci: {
collect: {
staticDistDir: './public',
url: ['/'],
},
assert: {
budgetFile: './budget.json',
},
upload: {
target: 'temporary-public-storage',
},
},
};
A useful way to integrate Lighthouse CI into your development workflow is to generate new reports for each commit or pull request to the project’s GitHub repository. This is where GitHub Actions come into play.
To set it up, you need to create a .github/workflow directory at the root of your project. This is where all the workflows for your project will be placed. If you’re new to GitHub Actions, you can think of a workflow as a set of one or more actions to be executed once an event is triggered (such as when a new pull request is made to the repo). Sarah Drasner has a nice primer on using GitHub Actions.
mkdir -p .github/workflowNext, create a YAML file in the .github/workflow directory. You can name it anything you want as long as it ends with the .yml or .yaml extension. This file is where the workflow configuration for the Lighthouse CI will be placed.
cd .github/workflow
touch lighthouse-ci.yamlThe contents of the lighthouse-ci.yaml file will vary depending on the type of project. I‘ll describe how I set it up for my Hugo website so you can adapt it for other types of projects. Here’s my configuration file in full:
# .github/workflow/lighthouse-ci.yaml
name: Lighthouse
on: [push]
jobs:
ci:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
with:
token: ${{ secrets.PAT }}
submodules: recursive
- name: Setup Hugo
uses: peaceiris/actions-hugo@v2
with:
hugo-version: "0.76.5"
extended: true
- name: Build site
run: hugo
- name: Use Node.js 15.x
uses: actions/setup-node@v2
with:
node-version: 15.x
- name: Run the Lighthouse CI
run: |
npm install -g @lhci/cli@0.6.x
lhci autorunThe above configuration creates a workflow called Lighthouse consisting of a single job (ci) which runs on an Ubuntu instance and is triggered whenever code is pushed to any branch in the repository. The job consists of the following steps:
repo scope enabled, then add it as a repository secret at https://github.com/<username>/<repo>/settings/secret. Without this token, this step will fail if it encounters a private repo.
public folder through the hugo command.lhci autorun command.Once you’ve set up the config file, you can commit and push the changes to your GitHub repository. This will trigger the workflow you just added provided your configuration was set up correctly. Go to the Actions tab in the project repository to see the status of the workflow under your most recent commit.

If you click through and expand the ci job, you will see the logs for each of the steps in the job. In my case, everything ran successfully but my assertions failed — hence the failure status. Just as we saw when we ran the test locally, the results are uploaded to the temporary public storage and you can view them by clicking the appropriate link in the logs.

At the moment, the Lighthouse CI has been configured to run as soon as code is pushed to the repo whether directly to a branch or through a pull request. The status of the test is displayed on the commit page, but you have click through and expand the logs to see the full details, including the links to the report.
You can set up a GitHub status check so that build reports are displayed directly in the pull request. To set it up, go to the Lighthouse CI GitHub App page, click the “Configure” option, then install and authorize it on your GitHub account or the organization that owns the GitHub repository you want to use. Next, copy the app token provided on the confirmation page and add it to your repository secrets with the name field set to LHCI_GITHUB_APP_TOKEN.

The status check is now ready to use. You can try it out by opening a new pull request or pushing a commit to an already existing pull request.

Using the temporary public storage option to store Lighthouse reports is great way to get started, but it is insufficient if you want to keep your data private or for a longer duration. This is where the Lighthouse CI server can help. It provides a dashboard for exploring historical Lighthouse data and offers an great comparison UI to uncover differences between builds.

To utilize the Lighthouse CI server, you need to deploy it to your own infrastructure. Detailed instructions and recipes for deploying to Heroku and Docker can be found on GitHub.
When setting up your configuration, it is a good idea to include a few different URLs to ensure good test coverage. For a typical blog, you definitely want to include to include the homepage, a post or two which is representative of the type of content on the site, and any other important pages.
Although we didn’t cover the full extent of what the Lighthouse CI tool can do, I hope this article not only helps you get up and running with it, but gives you a good idea of what else it can do. Thanks for reading, and happy coding!
The post Continuous Performance Analysis with Lighthouse CI and GitHub Actions appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
Hello, I'm new into PHP. Just migrated from Java recently.
I'm trying to make a conversion machine that conver number to romans number.
Here is the code I wrote :
!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Latins to Romans Conversion</title>
</head>
<body>
<h2>Latin to Romans Conversion</h2>
<form method="post">
Input Your Number : <input type="text" name="number"><br><br>
<input type="submit" name="convert" value="submit">
<input type="reset" value="reset"><br><br>
<?php
if(isset($_POST['convert'])) {
$number = $_POST['number'];
function convertToRoman($number) {
function getNum($digit, $lowStr, $midStr, $nextStr) {
switch (true) {
case $digit <= 3: return str_repeat($lowStr, $digit);
case $digit == 4: return $lowStr + $midStr;
case $digit <= 8: return $midStr + str_repeat($lowStr, $digit);
default: return $lowStr + $nextStr;
}
}
$str = "0";
//Ribuan
$str += str_repeat("M", floor($number / 1000)) . $number %= 1000;
//Ratusan
$str += getNum(floor($number / 100), 'C', 'D', 'M') . $number %= 100;
//Puluhan
$str += getNum(floor($number / 10), 'X','L', 'C') . $number %= 10;
//Satuan
$str += getNum($number, 'I', 'V', 'X');
return $str;
}
$decimal = $number;
echo "The Roman's form of this decimal number is", convertToRoman($decimal);
return $decimal;
}
?>
</body>
</html>It display these errors:
Warning: A non-numeric value encountered in D:\xampp\htdocs\omniwrench\latinromans.php on line 39
Warning: A non-numeric value encountered in D:\xampp\htdocs\omniwrench\latinromans.php on line 42
Anyway, I'm still using PHP 7. I tried declare of each romans value in an array like this (just example) :
$mapHundreds = array('M' => 1000);Anyone got solution? I've been searching the problem about this for an hour now. Thanks!