

I was ogling the idea of Exit Animations recently, that is, a recent proposal for (something like) @exit-style which could allow us to animate elements as we remove them from the DOM. That is largely just a proposal at the moment, with many challenges ahead.
But there is new tech that helps with exit (and entrance!) animations right now (in Chrome, anyway). They are some relatively new things that, if you’re like me, don’t pop to mind immediately just yet when we’re in these DOM enter/exit situations. Una Kravets and Joey Arhar covered them in a great blog post back in August: Four new CSS features for smooth entry and exit animations. Allow me to summarize!
- If you’re using a
@keyframesanimation, you can now set thedisplayproperty anywhere within it and it’ll flip at that keyframe. It didn’t use to be like this. Animations would immediately move thedisplayproperty to the final value. This makes “exit” animations where the very last thing you do is setdisplay: none, which removes the element from view and the accessibility tree, very possible with@keyframes. - If you’re using
transition, however, thedisplayproperty still instantly flips to the final value. That is, unless you use the newtransition-behavior: allow-discrete;property/value which flips it so thatdisplaychanges at the end of a transition instead of the beginning. - Those first two are pretty darn handy for exit animations (they don’t help with leaving-DOM situations, but are still “exits” of a sort). But for entrance or “starting” animations, when an element is added to the DOM, now we have
@starting-stylethat allows us to set some styles which then immediatelytransitionto the styles set on the element outside of that at-rule, assuming they are present. - Common HTML elements that you can imagine having entrances and exists are
<dialog>and any element behaving as a “popover” (like a menu or tooltip). These elements benefit from being magically transported to a “top layer”, meaning less fiddling withz-indexand stacking context problems and such. But now, if you decide to animate the transitions in and out of visibility, in order to make that happen smoothly, you need to add a new keywordoverlayto your transitions. Hey, sometimes you gotta do more work to have nice things.

And all of that doesn’t even get into View Transitions. View Transitions can actually help with “real” exit animations, so that’s worth a look if you’re in that situation. Una and Joey do cover that, so definitely dig into that blog post.
You know how some analytics tools can track clicks on outgoing links on websites? That always boggled my mind. In order for the analytics tool to know that, it needs to shoot that information to a server in the tiny split second of time before the website is gone and replaced with the new one at the link the user followed. I just assume that is fairly unreliable.
There is actually a web platform API that is specifically designed for this “just before a user leaves” situation: navigator.sendBeacon(). That’s nice to have, but you still have to call it, and call it at the right time. Erik Witt researched this in the blog post Unload Beacon Reliability: Benchmarking Strategies for Minimal Data Loss.
He compared calling sendBeacon in an event listener for unload, beforeunload, pagehide, and visibilitychange. I would have put my money on beforeunload, but that was by far the worst reporting only 37% of data reliably. The best of the four is visibilitychange at 90%. Erik also covers an experimental API in Chrome that is reporting 98% so check out the post for that (it also looks a bit easier to use).
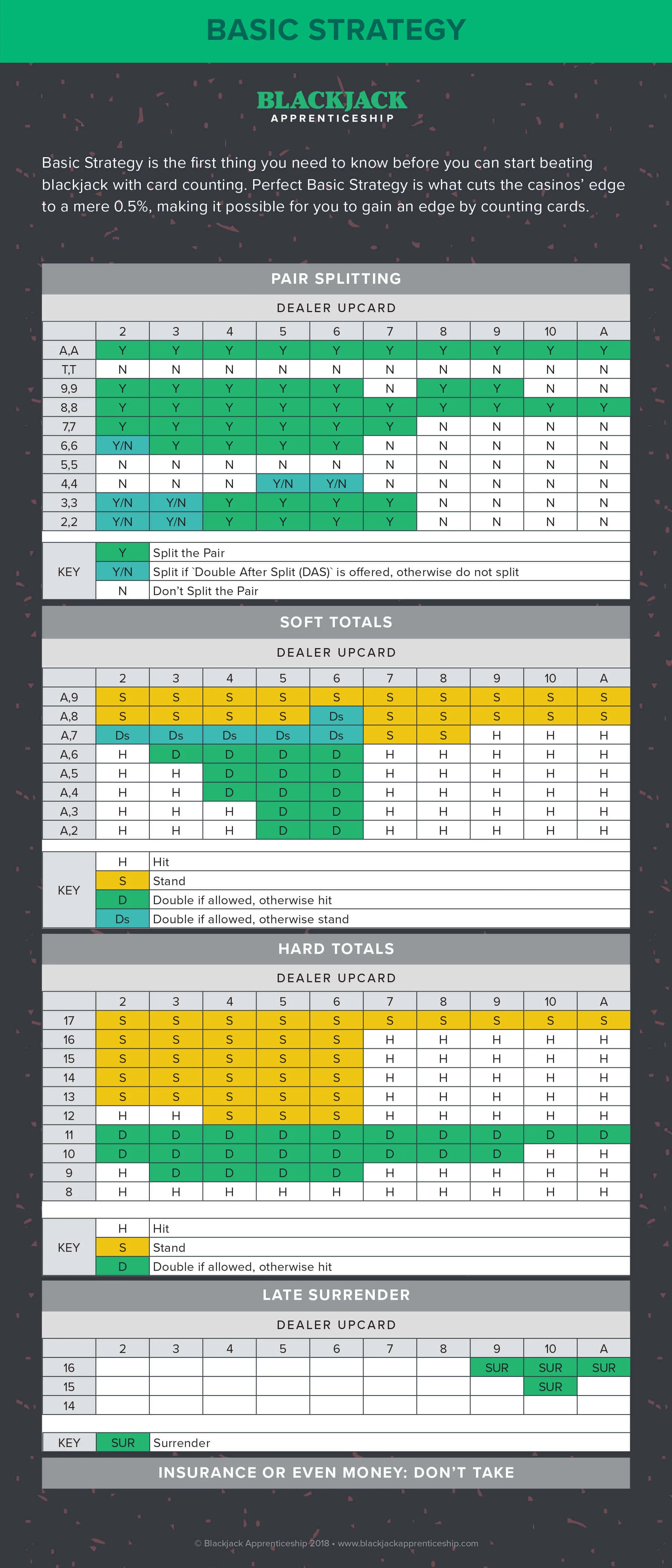
Once in a while, I see an AI/LLM API example that I’m like OK fine that’s pretty clever. I thought that when reading Raymond Camden’s Can GenAI help you win in Vegas? As Raymond says, uh, no, it can’t, but it can help you make the best-possible decision at a game like Blackjack that has a reasonably complex decision tree.
Of course what you could/should do, if you were going to write software to help you with Blackjack, is have the software return the correct result from the data in that tree. But there is something more fun and futuristic about asking an LLM for the answer instead. Like talking to a computer in your ear.
I’m playing blackjack and the dealer has a six of diamonds showing. I’ve got a jack of clubs and a jack of hearts. Should I hit or should I stay?
You have 20, which is a good hand. The dealer has 16, which is below the average. If you hit, you risk getting a card that will bust you. So it’s better to stay and hope that the dealer busts.
Again this isn’t a good idea, because as Raymond struggled through the AI was more than happy to provided horrible answers, but there is something interesting about crafting the prompt to get the best results and getting the results in “plain language” way that feels less boring than coordinates off a chart.

A Discord I’m in was chatting it up the other day about a recent Kevin Powell video: A new approach to container and wrapper classes (he credits a handful of others). The idea was setting up a grid with columns like this:
.grid {
display: grid;
grid-template-columns:
[full-width-start] minmax(var(--padding-inline), 1fr)
[breakout-start] minmax(0, var(--breakout-size))
[content-start] min(
100% - (var(--padding-inline) * 2),
var(--content-max-width)
)
[content-end]
minmax(0, var(--breakout-size)) [breakout-end]
minmax(var(--padding-inline), 1fr) [full-width-end];
}Kinda complicated looking right? Broken down into steps it’s really not that bad, it’s mostly the naming-things that makes it look like a lot. But the real beauty of it is in the naming. With this in place, you can very easily place an item edge-to-edge on the grid by just calling grid-column: full-width;, but regular content is set in the middle. There are some nice details to pick up in the video. Perhaps the best of which is how you can set the content within a full-width container back to the same center content area by applying the exact same template columns to that container.

Anything layout-related that requires JavaScript I usually side-eye pretty hard. The idea of layout failing, or even shifting, when JavaScript loads (or doesn’t) just bothers me.
But sometimes, when the layout updating is entirely a bonus enhancement, I relent. I think I might be there with Yihui Xie’s idea for making elements “full width” (like the class names Kevin makes available in the section above).
The idea is that you can use a little bit of JavaScript to dynamically decide if an element should be full width or not. Here are the situations:
- Code blocks (
<pre><code>).If thescrollWidthis greater thanoffsetWidth, it means the code block has a horizontal scrollbar, and we may want to make it full-width.- Tables (
<table>).If itsoffsetWidthis greater than its parent’soffsetWidth, it is too wide.- Table of contents (an element that has the ID
TableOfContents, e.g.,<nav id="TableOfContents">).If any TOC item has multiple rectangles on the layout (getClientRects().length > 1), it means the item is wrapped, and the TOC may benefit from more space.
If the elements become full-width, great, it’s a likely enhancement, but if they don’t, it’s not a big deal.
Yihui Xie does the full-width-ing with a class like this:
.fullwidth {
width: 100vw;
margin-left: calc(50% - 50vw);
}Which is also a classic technique, but I’d say isn’t quite as robust or flexible as the above techniques.
Say you wanted to track page views on a site, but very much want to avoid any bots. That is, anything requesting your site that isn’t a real life human user. Herman Martinus is trying that with his Bear blogging platform like this:
body:hover {
border-image: url("/hit/{{ post.id }}/?ref={{ request.META.HTTP_REFERER }}");
}Now, when a person hovers their cursor over the page (or scrolls on mobile) it triggers
body:hoverwhich calls the URL for the post hit. I don’t think any bots hover and instead just use JS to interact with the page, so I can, with reasonable certainty, assume that this is a human reader.I then confirm the user-agent isn’t a bot (which isn’t perfect, but still something). I also extract the browser and platform from the user-agent string.
Perhaps not rigorous computer science but I bet it’s a lot more useful number than just a server side counter.

























































{kind=link}