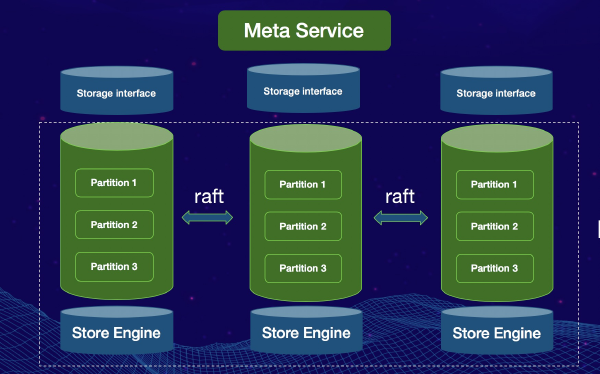
This article is written by Liu Jiahao, an engineer at the big data team of IntSig Information Co. Ltd (IntSig). He has been playing around with Nebula Graph and is one of our proud GitHub contributors. This post shares his experience importing data to Nebula Graph with Spark.
Why Nebula Graph?
The graph-related business has grown more and more complex, and performance bottlenecks are identified in some popular graph databases. For example, a single machine has difficulties in scaling to larger graphs. In terms of performance, the native graph storage of Neo4j has irreplaceable advantages. In my survey, JanusGraph, Dgraph, and other graph databases cannot be comparable to Neo4j in this regard. JanusGraph performs very well in OLAP and can support OLTP to some extent. However, this cannot be an advantage of JanusGraph anymore, because some technologies, such as GraphFrame, are sufficient for the OLAP requirements. Besides, since Spark 3.0 starts to support Cypher, I found that comparing with the OLTP requirements of graphs, their OLAP requirements can be satisfied with more technologies. Therefore, Nebula Graph undoubtedly turns out to be a breakthrough to the low efficiency distributed OLTP databases.