A website’s performance can make or break its success, yet in August 2020, despite many improvements we had previously made, such as implementing Server-Side Rendering (SSR), the ratio of Wix websites with good Google Core Web Vitals (CWV) scores was only 4%. It was at this point that we realized we needed to make a significant change in our approach towards performance, and that we must embrace performance as part of our culture.
Implementing this change enabled us to take major steps such as updating our infrastructure along with completely rewriting our core functionality from the ground up. We deployed these enhancements gradually over time to ensure that our users didn’t experience any disruptions, but instead only a consistent improvement of their site speed.
Since implementing these changes, we have seen a dramatic improvement in the performance of websites built and hosted on our platform. In particular, the worldwide ratio of Wix websites that receive a good (green) CWV score has increased from 4% to over 33%, which means an increase of over 750%. We also expect this upwards trend to continue as we roll out additional improvements to our platform.
You can see the impact of these efforts in the Core Web Vitals Technology Report from Google Chrome User Experience Report (CrUX) / HTTP Archive:

These performance improvements provide a lot of value to our users because sites that have good Google CWV scores are eligible for the maximum performance ranking boost in the Google search results (SERP). They also likely have increased conversion rates and lower bounce rates due to the improved visitor experience.
Now, let’s take a deeper look into the actions and processes we put in place in order to achieve these significant results.
The Wix Challenge
Let’s begin by describing who we are, what are our use-cases, and our challenges.
Wix is a SaaS platform providing products and services for any type of user to create an online presence. This includes building websites, hosting websites, managing campaigns, SEO, analytics, CRM, and much more. It was founded in 2006 and has since grown to have over 210 million users in 190 countries, and hosts over five million domains. In addition to content websites, Wix also supports e-commerce, blogs, forums, bookings and events, and membership and authentication. And Wix has its own app store with apps and themes for restaurants, fitness, hotels, and much more. To support all this, we have over 5,000 employees spread around the globe.
This high rate of growth, coupled with the current scale and diversity of offerings presents a huge challenge when setting out to improve performance. It’s one thing to identify bottlenecks and implement optimizations for a specific website or a few similar websites, and quite another when dealing with many millions of websites, having such a wide variety of functionality, and an almost total freedom of design. As a result, we cannot optimize for a specific layout or set of features that are known in advance. Instead, we have to accommodate all of this variability, mostly on-demand. On the positive side, since there are so many users and websites on Wix, improvements that we make benefit millions of websites, and can have a positive impact on the Web as a whole.
There are more challenges for us in addition to scale and diversity:
- Retaining existing design and behavior
A key requirement we set for ourselves was to improve the performance of all existing websites built on Wix without altering any aspect of their look and feel. So essentially, they need to continue to look and work exactly the same, only operate faster.
- Maintaining development velocity
Improving performance requires a significant amount of resources and effort. And the last thing we want is to negatively impact our developers' momentum, or our ability to release new features at a high rate. So once a certain level of performance is achieved, we want to be able to preserve it without being constantly required to invest additional effort, or slow down the development process. In other words, we needed to find a way to automate the process of preventing performance degradations.
- Education
In order to create change across our entire organization, we needed to get all the relevant employees, partners, and even customers up to speed about performance quickly and efficiently. This required a lot of planning and forethought, and quite a bit of trial and error.
Creating A Performance Culture
Initially, at Wix, performance was a task assigned to a relatively small dedicated group within the company. This team was tasked with identifying and addressing specific performance bottlenecks, while others throughout the organization were only brought in on a case-by-case basis. While some noticeable progress was made, it was challenging to implement significant changes just for the sake of speed.
This was because the amount of effort required often exceeded the capacity of the performance team, and also because ongoing work on various features and capabilities often got in the way. Another limiting factor was the lack of data and insight into exactly what the bottlenecks were so that we could know exactly where to focus our efforts for maximum effect.
About two years ago, we came to the conclusion that we cannot continue with this approach. That in order to provide the level of performance that our users require and expect we need to operate at the organizational level. And that if we do not provide this level of performance it will be detrimental to our business and future success. There were several catalysts for this understanding, some due to changes in the Web ecosystem in general, and others to our own market segment in particular:
- Changes in device landscape
Six years ago, over 70% of sessions for Wix websites originated from desktops, with under 30% coming from mobile devices. Since then the situation has flipped, and now over 70% of sessions originate on mobile. While mobile devices have come a long way in terms of network and CPU speed, many of them are still significantly underpowered when compared to desktops, especially in countries where mobile connectivity is still poor. As a result, unless performance improves, many visitors experience a decline in the quality of experience they receive over time.
- Customer expectations
Over the past few years, we’ve seen a significant shift in customer expectations regarding performance. Thanks to activities by Google and others, website owners now understand that having good loading speed is a major factor in the success of their sites. As a result, customers prefer platforms that provide good performance — and avoid or leave those that don’t.
- Google search ranking
Back in 2018 Google announced that sites with especially slow pages on mobile would be penalized. But starting in 2021, Google shifted its approach to instead boost the ranking of mobile sites that have good performance. This has increased the motivation of site owners and SEOs to use platforms that can create fast sites.
- Heavier websites
As the demand for faster websites increases, so does the expectation that websites provide a richer and more engaging experience. This includes features like videos and animations, sophisticated interactions, and greater customization. As websites become heavier and more complex, the task of maintaining performance becomes ever more challenging.
- Better tooling and metrics standardization
Measuring website performance used to be challenging and required specific expertise. But in recent years the ability to gauge the speed and responsiveness of websites has improved significantly and has become much simpler, thanks to tools like Google Lighthouse and PageSpeed Insights. Moreover, the industry has primarily standardized on Google’s Core Web Vitals (CWV) performance metrics, and monitoring them is now integrated into services such as the Google Search Console.
These changes dramatically shifted our perception of website performance from being just a part of our offerings to become an imperative company focus and a strategic priority. And that in order to achieve this strategy implementing a culture of performance throughout the organization is a must. In order to accomplish this, we took a two-pronged approach. First, at an “all hands” company update, our CEO announced that going forward ensuring good performance for websites built on our platform will be a strategic priority for the company as a whole. And that the various units within the company will be measured on their ability to deliver on this goal.
At the same time, the performance team underwent a huge transformation in order to support the company-wide prioritization of performance. It went from working on specific speed enhancements to interfacing with all levels of the organization, in order to support their performance efforts. The first task was providing education on what website performance actually means, and how it can be measured. And once the teams started working off of the knowledge, it meant organizing performance-focused design and code reviews, training and education, plus providing tools and assets to support these ongoing efforts.
To this end, the team built on the expertise that it had already gained while working on specific performance projects. And it also engaged with the performance community as a whole, for example by attending conferences, bringing in domain experts, and studying up on modern architectures such as the Jamstack.
Measuring And Monitoring
Peter Drucker, one of the best-known management consultants, famously stated:
“If you can’t measure it, you can’t improve it.”
This statement is true for management, and it’s undoubtedly true for website performance.
But which metrics should be measured in order to determine website performance? Over the years many metrics have been proposed and used, which made it difficult to compare results taken from different tools. In other words, the field lacked standardization. This changed approximately two years ago when Google introduced three primary metrics for measuring website performance, known collectively as Google Core Web Vitals (CWV).
The three metrics are:
- LCP: Largest Contentful Paint (measures visibility)
- FID: First Input Delay (measures response time)
- CLS: Cumulative Layout Shift (measures visual stability)
CWV have enabled the industry to focus on a small number of metrics that cover the main aspects of the website loading experience. And the fact that Google is now using CWV as a search ranking signal provides additional motivation for people to improve them.
Recommended Reading: “An In-Depth Guide To Measuring Core Web Vitals” by Barry Pollard
At Wix, we focus on CWV when analyzing field data, but also use lab measurements during the development process. In particular, lab tests are critical for implementing performance budgets in order to prevent performance degradations. The best implementations of performance budgets integrate their enforcement into the CI/CD process, so they are applied automatically, and prevent deployment to production when a regression is detected. When such a regression does occur it breaks the build, forcing the team to fix it before deployment can proceed.
There are various performance budgeting products and open-source tools available, but we decided to create our own custom budgeting service called Perfer. This is because we operate at a much larger scale than most web development operations, and at any given moment hundreds of different components are being developed at Wix and are used in thousands of different combinations in millions of different websites.
This requires the ability to test a very large number of configurations. Moreover, in order to avoid breaking builds with random fluctuations, tests that measure performance metrics or scores are run multiple times and an aggregate of the results is used for the budget. In order to accommodate such a high number of test runs without negatively impacting build time, Perfer executes the performance measurements in parallel on a cluster of dedicated servers called WatchTower. Currently, WatchTower is able to execute up to 1,000 Lighthouse tests per minute.
After deployment performance data is collected anonymously from all Wix sessions in the field. This is especially important in our case because the huge variety of Wix websites makes it effectively impossible to test all relevant configurations and scenarios “in the lab.” By collecting and analyzing RUM data, we ensure that we have the best possible insight into the experiences of actual visitors to the websites. If we identify that a certain deployment degrades performance and harms that experience, even though this degradation was not identified by our lab tests, we can quickly roll it back.
Another advantage of field measurements is that they match the approach taken by Google in order to collect performance data into the CrUX database. Since it is the CrUX data that is used as an input for Google’s performance ranking signal, utilizing the same approach for performance analysis is very important.
All Wix sessions contain custom instrumentation code that gathers performance metrics and transmits this information anonymously back to our telemetry servers. In addition to the three CWV, this code also reports Time To First Byte (TTFB), First Contentful Paint (FCP), Total Blocking Time (TBT), and Time To Interactive (TTI), and also low-level metrics such as DNS lookup time and SSL handshake time. Collecting all this information makes it possible for us to not only quickly identify performance issues in production, but also to analyze the root causes of such issues. For example, we can determine if an issue was caused by changes in our own software by the changes in our infrastructure configuration, or even by issues affecting third-party services that we utilize (such as CDNs).
Upgrading Our Services And Infrastructure
Back when I joined Wix seven years ago, we only had a single data center (along with a fallback data center) in the USA which was used to serve users from all around the world. Since then we’ve expanded the number of data centers significantly, and have multiple such centers spread around the globe. This ensures that wherever our users connect from, they’ll be serviced both quickly and reliably. In addition, we use CDNs from multiple providers to ensure rapid content delivery regardless of location. This is especially important given that we now have users in 190 countries.
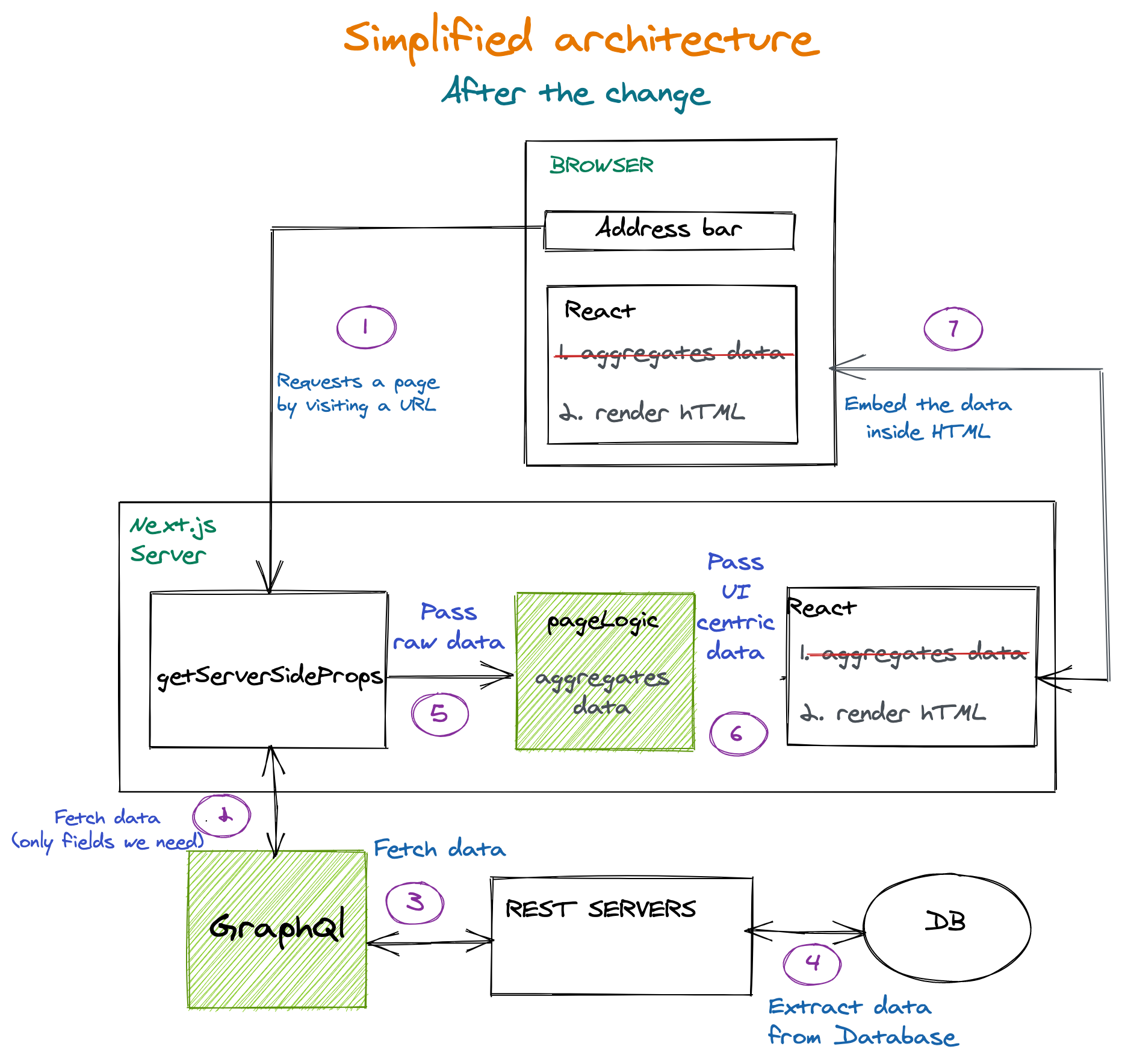
In order to make the best possible use of this enhanced infrastructure, we completely redesigned and rewrote significant portions of our front-end code. The goal was to shift as much of the computation as possible off of the browsers and onto fast servers. This is especially beneficial in the case of mobile devices, which are often less powerful and slower. In addition, this significantly reduced the amount of JavaScript code that needs to be downloaded by the browser.
Reducing JavaScript size almost always benefits performance because it decreases the overhead of the actual download as well as parsing and execution. Our measurements showed a direct correlation between the JavaScript size reduction and performance improvements:

Another benefit of moving computations from browsers to servers is that the results of these computations can often be cached and reused between sessions even for unrelated visitors, thus reducing per-session execution time dramatically. In particular, when a visitor navigates to a Wix site for the first time, the HTML of the landing page is generated on the server by Server-Side Rendering (SSR) and the resulting HTML can then be propagated to a CDN.
Navigations to the same site — even by unrelated visitors — can then be served directly from the CDN, without even accessing our servers. If this workflow sounds familiar that’s because it’s essentially the same as the on-demand mechanism provided by some advanced Jamstack services.
Note: “On-demand” means that instead of Static Site Generation performed at build time, the HTML is generated in response to the first visitor request, and propagated to a CDN at runtime.

Similarly to Jamstack, client-side code can enhance the user interface, making it more dynamic by invoking backend services using APIs. The results of some of these APIs are also cached in a CDN as appropriate. For example, in the case of a shopping cart checkout icon, the HTML for the button is generated on the server, but the actual number of items in the cart is determined on the client-side and then rendered into that icon. This way, the page HTML can be cached even though each visitor is able to see a different item count value. If the HTML of the page does need to change, for example, if the site owner publishes a new version, then the copy in the CDN is immediately purged.
In order to reduce the impact of computations on end-point devices, we moved business logic that does need to run in the browsers into Web Workers. For example, business logic that is invoked in response to user interactions. The code that runs in the browser’s main thread is mostly dedicated to the actual rendering operations. Because Web Workers execute their JavaScript code off of the main thread, they don’t block event handling, enabling the browser to quickly respond to user interactions and other events.
Examples of code that runs in Web Workers include the business logic of various vertical solutions such as e-commerce and bookings. Sending requests to backend services is mostly done from Web Workers, and the responses are parsed, stored and managed in the Web Workers as well. As a result, using Web Workers can reduce blocking and improve the FID metric significantly, providing better responsiveness in general. In lab measurements, this improved TBT measurements.

Enhanced Media Delivery
Modern websites often provide a richer user experience by downloading and presenting much more media resources, such as images and videos, than ever before. Over the past decade the median amount of bytes of images downloaded by websites, according to the Google CrUX database, has increased more than eightfold! This is more than the median improvement in network speeds during the same period, which results in slower loading times. Additionally, our RUM data (field measurements) shows that for almost ¾ of Wix sessions the LCP element is an image. All of this highlights the need to deliver images to the browsers as efficiently as possible and to quickly display the images that are in a webpage’s initially visible viewport area.
At the same time, it is crucial to deliver the highest quality of images possible in order to provide an engaging and delightful user experience. This means that improving performance by noticeably degrading visual experience is almost always out of the question. The performance enhancements we implement need to preserve the original quality of images used, unless explicitly specified otherwise by the user.
One technique for improving media-related performance is optimizing the delivery process. This means downloading required media resources as quickly as possible. In order to achieve this for Wix websites, we use a CDN to deliver the media content, as we do with other resources such as the HTML itself. And by specifying a lengthy caching duration in the HTTP response header, we allow images to be cached by browsers as well. This can improve the loading speed for repeat visits to the same page significantly by completely avoiding downloading the images over the network again.
Another technique for improving performance is to deliver the required image information more efficiently by reducing the number of bytes that need to be downloaded while preserving the desired image quality. One method to achieve this is to use a modern image format such as WebP. Images encoded as WebP are generally 25% to 35% smaller than equivalent images encoded as PNG or JPG. Images uploaded to Wix are automatically converted to WebP before being delivered to browsers that support this format.
Very often images need to be resized, cropped, or otherwise manipulated when displayed within a webpage. This manipulation can be performed inside the browser using CSS, but this usually means that more data needs to be downloaded than is actually used. For example, all the pixels of an image that have been cropped out aren’t actually needed but are still delivered. We also take into account viewport size and resolution, and display pixel depth, to optimize the image size. For Wix sites, we perform these manipulations on the server-side before the images are downloaded, this way we can ensure that only the pixels that are actually required are transmitted over the network. On the servers, we employ AI and ML models to generate resized images at the best quality possible.
Yet another technique that is used for reducing the amount of image data that needs to be downloaded upfront is lazy loading images. This means not loading images that are wholly outside the visible viewport until they are about to scroll in. Deferring image download in this way, and even avoiding it completely (if a visitor never scrolls to that part of the page), reduces network contention for resources that are already required as soon as the page loads, such as an LCP image. Wix websites automatically utilize lazy loading for images, and for various other types of resources as well.

Looking Forward
Over the past two years, we have deployed numerous enhancements to our platform intended to improve performance. The result of all these enhancements is a dramatic increase in the percentage of Wix websites that get a good score for all three CWVs compared to a year ago. But performance is a journey, not a destination, and we still have many more action items and future plans for improving websites’ speed. To that end, we are investigating new browser capabilities as well as additional changes to our own infrastructure. The performance budgets and monitoring that we have implemented provide safeguards that these changes provide actual benefits.
New media formats are being introduced that have the potential to reduce download sizes even more while retaining image quality. We are currently investigating AVIF, which looks to be especially promising for photographic images that can use lossy compression. In such scenarios, AVIF can provide significantly reduced download sizes even compared to WebP, while retaining image quality. AVIF also supports progressive rendering which may improve perceived performance and user experience, especially on slower connections, but currently won’t provide any benefits for CWV.
Another promising browser innovation that we are researching is the content-visibility CSS property. This property enables the browser to skip the effort of rendering an HTML element until it’s actually needed. In particular, when content-visibility:auto setting is applied to an element that is off-screen its descendants are not rendered. This enables the browser to skip most of the rendering work, such as styling and layout of the element’s subtree. This is especially desirable for many Wix pages that tend to be lengthy and content-rich. In particular, Wix’s new EditorX responsive sites editor support sophisticated grid and flexbox layouts that can be expensive for the browser to render, so that avoiding unnecessary rendering operations is especially desirable. Unfortunately, this property is currently only supported in Chromium-based browsers. Also, it’s challenging to implement this functionality in such a way that no Wix website is ever adversely affected in terms of its visual appearance or behavior.
Priority Hints is an upcoming browser feature that we are also investigating, which promises to improve performance by providing greater control over when and how browsers download resources. This feature will inform browsers about which resources are more urgent and should be downloaded ahead of other resources. For example, a foreground image could be assigned a higher priority than a background image since it’s more likely to contain significant content. On the other hand, if applied incorrectly, priority hints can actually degrade download speed, and hence also CWV scores. Priority hints are currently undergoing Origin Trial in Chrome.
In addition to enhancing Wix’s own infrastructure, we’re also working on providing better tooling for our users so that they can design and implement faster websites. Since Wix is highly customizable, users have the freedom and flexibility to create both fast and slow websites on our platform, depending on the decisions they make while building these sites. Our goal is to inform users about the performance of their decisions so that they can make appropriate choices. This is similar to the SEO Wiz tool that we already provide.
Summary
Implementing a performance culture at Wix enabled us to apply performance enhancements to almost every part of our technological stack — from infrastructure to software architecture and media formats. While some of these enhancements have had a greater impact than others, it’s the cumulative effect that provides the overall benefits. And these benefits aren’t just measurable at a large scale; they’re also apparent to our users, thanks to tools like WebPageTest and Google PageSpeed Insights and actual feedback that they receive from their own users.


The feedback we ourselves receive, from our users and the industry at large, and the tangible benefits we experience, drive us forward to continue improving our speed. The performance culture that we’ve implemented is here to stay.
Related Resources