JSON, or JavaScript Object Notation, is a ubiquitous data format used by all sorts of mobile and web apps for asynchronous browser-server communication. JSON is an extremely popular data format, very easy to work with, compatible with every major programming language, and is supported by every major browser. However, just like any programming language, it throws a lot of errors when it decides that today is not going to be your day.
JSON.Parse Syntax Errors
In most web applications, nearly all data transferred from a web server is transmitted in a string format. To convert that string into JSON, we use the JSON.parse() function, and this is the main function that throws errors. Nearly all JSON.parse errors are a subset of the SyntaxError error type. The debugging console throws around 32 different error messages when you mess up your JSON data. And some of them are very tricky to debug; and yes I am talking about you unexpected non-whitespace character after JSON data.
Get Started With Node: An Introduction To APIs, HTTP And ES6+ JavaScript
Get Started With Node: An Introduction To APIs, HTTP And ES6+ JavaScript
Jamie Corkhill
You’ve probably heard of Node.js as being an “asynchronous JavaScript runtime built on Chrome’s V8 JavaScript engine”, and that it “uses an event-driven, non-blocking I/O model that makes it lightweight and efficient”. But for some, that is not the greatest of explanations.
What is Node in the first place? What exactly does it mean for Node to be “asynchronous”, and how does that differ from “synchronous”? What is the meaning “event-driven” and “non-blocking” anyway, and how does Node fit into the bigger picture of applications, Internet networks, and servers?
We’ll attempt to answer all of these questions and more throughout this series as we take an in-depth look at the inner workings of Node, learn about the HyperText Transfer Protocol, APIs, and JSON, and build our very own Bookshelf API utilizing MongoDB, Express, Lodash, Mocha, and Handlebars.
What Is Node.js
Node is only an environment, or runtime, within which to run normal JavaScript (with minor differences) outside of the browser. We can use it to build desktop applications (with frameworks like Electron), write web or app servers, and more.
Blocking/Non-Blocking And Synchronous/Asynchronous
Suppose we are making a database call to retrieve properties about a user. That call is going to take time, and if the request is “blocking”, then that means it will block the execution of our program until the call is complete. In this case, we made a “synchronous” request since it ended up blocking the thread.
So, a synchronous operation blocks a process or thread until that operation is complete, leaving the thread in a “wait state”. An asynchronous operation, on the other hand, is non-blocking. It permits execution of the thread to proceed regardless of the time it takes for the operation to complete or the result it completes with, and no part of the thread falls into a wait state at any point.
Let’s look at another example of a synchronous call that blocks a thread. Suppose we are building an application that compares the results of two Weather APIs to find their percent difference in temperature. In a blocking manner, we make a call to Weather API One and wait for the result. Once we get a result, we call Weather API Two and wait for its result. Don’t worry at this point if you are not familiar with APIs. We’ll be covering them in an upcoming section. For now, just think of an API as the medium through which two computers may communicate with one another.
Time progression of synchronous blocking operations (Large preview)
Allow me to note, it’s important to recognize that not all synchronous calls are necessarily blocking. If a synchronous operation can manage to complete without blocking the thread or causing a wait state, it was non-blocking. Most of the time, synchronous calls will be blocking, and the time they take to complete will depend on a variety of factors, such as the speed of the API’s servers, the end user’s internet connection download speed, etc.
In the case of the image above, we had to wait quite a while to retrieve the first results from API One. Thereafter, we had to wait equally as long to get a response from API Two. While waiting for both responses, the user would notice our application hang — the UI would literally lock up — and that would be bad for User Experience.
In the case of a non-blocking call, we’d have something like this:
Time progression of asynchronous non-blocking operations (Large preview)
You can clearly see how much faster we concluded execution. Rather than wait on API One and then wait on API Two, we could wait for both of them to complete at the same time and achieve our results almost 50% faster. Notice, once we called API One and started waiting for its response, we also called API Two and began waiting for its response at the same time as One.
At this point, before moving into more concrete and tangible examples, it is important to mention that, for ease, the term “Synchronous” is generally shortened to “Sync”, and the term “Asynchronous” is generally shortened to “Async”. You will see this notation used in method/function names.
Callback Functions
You might be wondering, “if we can handle a call asynchronously, how do we know when that call is finished and we have a response?” Generally, we pass in as an argument to our async method a callback function, and that method will “call back” that function at a later time with a response. I’m using ES5 functions here, but we’ll update to ES6 standards later.
function asyncAddFunction(a, b, callback) {
callback(a + b); //This callback is the one passed in to the function call below.
}
asyncAddFunction(2, 4, function(sum) {
//Here we have the sum, 2 + 4 = 6.
});
Such a function is called a “Higher-Order Function” since it takes a function (our callback) as an argument. Alternatively, a callback function might take in an error object and a response object as arguments, and present them when the async function is complete. We’ll see this later with Express. When we called asyncAddFunction(...), you’ll notice we supplied a callback function for the callback parameter from the method definition. This function is an anonymous function (it does not have a name) and is written using the Expression Syntax. The method definition, on the other hand, is a function statement. It’s not anonymous because it actually has a name (that being “asyncAddFunction”).
Some may note confusion since, in the method definition, we do supply a name, that being “callback”. However, the anonymous function passed in as the third parameter to asyncAddFunction(...) does not know about the name, and so it remains anonymous. We also can’t execute that function at a later point by name, we’d have to go through the async calling function again to fire it.
As an example of a synchronous call, we can use the Node.js readFileSync(...) method. Again, we’ll be moving to ES6+ later.
var fs = require('fs');
var data = fs.readFileSync('/example.txt'); // The thread will be blocked here until complete.
If we were doing this asynchronously, we’d pass in a callback function which would fire when the async operation was complete.
var fs = require('fs');
var data = fs.readFile('/example.txt', function(err, data) { //Move on, this will fire when ready.
if(err) return console.log('Error: ', err);
console.log('Data: ', data); // Assume var data is defined above.
});
// Keep executing below, don’t wait on the data.
If you have never seen return used in that manner before, we are just saying to stop function execution so we don’t print the data object if the error object is defined. We could also have just wrapped the log statement in an else clause.
Like our asyncAddFunction(...), the code behind the fs.readFile(...) function would be something along the lines of:
function readFile(path, callback) {
// Behind the scenes code to read a file stream.
// The data variable is defined up here.
callback(undefined, data); //Or, callback(err, undefined);
}
Allow us to look at one last implementation of an async function call. This will help to solidify the idea of callback functions being fired at a later point in time, and it will help us to understand the execution of a typical Node.js program.
setTimeout(function {
// ...
}, 1000);
The setTimeout(...) method takes a callback function for the first parameter which will be fired after the number of milliseconds specified as the second argument has occurred.
Let’s look at a more complex example:
console.log('Initiated program.');
setTimeout(function {
console.log('3000 ms (3 sec) have passed.');
}, 3000);
setTimeout(function {
console.log('0 ms (0 sec) have passed.');
}, 0);
setTimeout(function {
console.log('1000 ms (1 sec) has passed.');
}, 1000);
console.log('Terminated program');
The output we receive is:
Initiated program.
Terminated program.
0 ms (0 sec) have passed.
1000 ms (1 sec) has passed.
3000 ms (3 sec) have passed.
You can see that the first log statement runs as expected. Instantaneously, the last log statement prints to the screen, for that happens before 0 seconds have surpassed after the second setTimeout(...). Immediately thereafter, the second, third, and first setTimeout(...) methods execute.
If Node.js was not non-blocking, we’d see the first log statement, wait 3 seconds to see the next, instantaneously see the third (the 0-second setTimeout(...), and then have to wait one more second to see the last two log statements. The non-blocking nature of Node makes all timers start counting down from the moment the program is executed, rather than the order in which they are typed. You may want to look into Node APIs, the Callstack, and the Event Loop for more information about how Node works under the hood.
It is important to note that just because you see a callback function does not necessarily mean there is an asynchronous call in the code. We called the asyncAddFunction(…) method above “async” because we are assuming the operation takes time to complete — such as making a call to a server. In reality, the process of adding two numbers is not async, and so that would actually be an example of using a callback function in a fashion that does not actually block the thread.
Promises Over Callbacks
Callbacks can quickly become messy in JavaScript, especially multiple nested callbacks. We are familiar with passing a callback as an argument to a function, but Promises allow us to tack, or attach, a callback to an object returned from a function. This would allow us to handle multiple async calls in a more elegant manner.
As an example, suppose we are making an API call, and our function, not so uniquely named ‘makeAPICall(...)’, takes a URL and a callback.
Our function, makeAPICall(...), would be defined as
function makeAPICall(path, callback) {
// Attempt to make API call to path argument.
// ...
callback(undefined, res); // Or, callback(err, undefined); depending upon the API’s response.
}
If we wanted to make another API call using the response from the first, we would have to nest both callbacks. Suppose I need to inject the userName property from the res1 object into the path of the second API call. We would have:
Note: The ES6+ method to inject the res1.userName property rather than string concatenation would be to use “Template Strings”. That way, rather than encapsulate our string in quotes (‘, or “), we would use backticks (\), located beneath the Escape key on your keyboard. Then, we would use the notation ${} to embed any JS expression inside the brackets. In the end, our earlier path would be: /newExample/${res.UserName}, wrapped in backticks.
It is clear to see that this method of nesting callbacks can quickly become quite inelegant, so-called the “JavaScript Pyramid of Doom”. Jumping in, if we were using promises rather than callbacks, we could refactor our code from the first example as such:
The first argument to the then() function is our success callback, and the second argument is our failure callback. Alternatively, we could lose the second argument to .then(), and call .catch() instead. Arguments to .then() are optional, and calling .catch() would be equivalent to .then(successCallback, null).
It is important to note that we can’t just tack a .then() call on to any function and expect it to work. The function we are calling has to actually return a promise, a promise that will fire the .then() when that async operation is complete. In this case, makeAPICall(...) will do it’s thing, firing either the then() block or the catch() block when completed.
To make makeAPICall(...) return a Promise, we assign a function to a variable, where that function is the Promise constructor. Promises can be either fulfilled or rejected, where fulfilled means that the action relating to the promise completed successfully, and rejected meaning the opposite. Once the promise is either fulfilled or rejected, we say it has settled, and while waiting for it to settle, perhaps during an async call, we say that the promise is pending.
The Promise constructor takes in one callback function as an argument, which receives two parameters — resolve and reject, which we will call at a later point in time to fire either the success callback in .then(), or the .then() failure callback, or .catch(), if provided.
Here is an example of what this looks like:
var examplePromise = new Promise(function(resolve, reject) {
// Do whatever we are going to do and then make the appropiate call below:
resolve('Happy!'); // — Everything worked.
reject('Sad!'); // — We noticed that something went wrong.
}):
Then, we can use:
examplePromise.then(/* Both callback functions in here */);
// Or, the success callback in .then() and the failure callback in .catch().
Notice, however, that examplePromise can’t take any arguments. That kind of defeats the purpose, so we can return a promise instead.
function makeAPICall(path) {
return new Promise(function(resolve, reject) {
// Make our async API call here.
if (/* All is good */) return resolve(res); //res is the response, would be defined above.
else return reject(err); //err is error, would be defined above.
});
}
Promises really shine to improve the structure, and subsequently, elegance, of our code with the concept of “Promise Chaining”. This would allow us to return a new Promise inside a .then() clause, so we could attach a second .then() thereafter, which would fire the appropriate callback from the second promise.
Refactoring our multi API URL call above with Promises, we get:
makeAPICall('/example').then(function(res) { // First response callback. Fires on success to '/example' call.
return makeAPICall(`/newExample/${res.UserName}`); // Returning new call allows for Promise Chaining.
}, function(err) { // First failure callback. Fires if there is a failure calling with '/example'.
console.log('Error:', err);
}).then(function(res) { // Second response callback. Fires on success to returned '/newExample/...' call.
console.log(res);
}, function(err) { // Second failure callback. Fire if there is a failure calling with '/newExample/...'
console.log('Error:', err);
});
Notice that we first call makeAPICall('/example'). That returns a promise, and so we attach a .then(). Inside that then(), we return a new call to makeAPICall(...), which, in and of itself, as seen earlier, returns a promise, permitting us chain on a new .then() after the first.
Like above, we can restructure this for readability, and remove the failure callbacks for a generic catch() all clause. Then, we can follow the DRY Principle (Don’t Repeat Yourself), and only have to implement error handling once.
makeAPICall('/example')
.then(function(res) { // Like earlier, fires with success and response from '/example'.
return makeAPICall(`/newExample/${res.UserName}`); // Returning here lets us chain on a new .then().
})
.then(function(res) { // Like earlier, fires with success and response from '/newExample'.
console.log(res);
})
.catch(function(err) { // Generic catch all method. Fires if there is an err with either earlier call.
console.log('Error: ', err);
});
Note that the success and failure callbacks in .then() only fire for the status of the individual Promise that .then() corresponds to. The catch block, however, will catch any errors that fire in any of the .then()s.
ES6 Const vs. Let
Throughout all of our examples, we have been employing ES5 functions and the old var keyword. While millions of lines of code still run today employing those ES5 methods, it is useful to update to current ES6+ standards, and we’ll refactor some of our code above. Let’s start with const and let.
You might be used to declaring a variable with the var keyword:
var pi = 3.14;
With ES6+ standards, we could make that either
let pi = 3.14;
or
const pi = 3.14;
where const means “constant” — a value that cannot be reassigned to later. (Except for object properties — we’ll cover that soon. Also, variables declared const are not immutable, only the reference to the variable is.)
In old JavaScript, block scopes, such as those in if, while, {}. for, etc. did not affect var in any way, and this is quite different to more statically typed languages like Java or C++. That is, the scope of var is the entire enclosing function — and that could be global (if placed outside a function), or local (if placed within a function). To demonstrate this, see the following example:
function myFunction() {
var num = 5;
console.log(num); // 5
console.log('--');
for(var i = 0; i < 10; i++)
{
var num = i;
console.log(num); //num becomes 0 — 9
}
console.log('--');
console.log(num); // 9
console.log(i); // 10
}
myFunction();
Output:
5
---
0
1 2 3 ... 7 8 9
---
9
10
The important thing to notice here is that defining a new var num inside the for scope directly affected the var num outside and above the for. This is because var’s scope is always that of the enclosing function, and not a block.
Again, by default, var i inside for() defaults to myFunction’s scope, and so we can access i outside the loop and get 10.
In terms of assigning values to variables, let is equivalent to var, it’s just that let has block scoping, and so the anomalies that occurred with var above will not happen.
function myFunction() {
let num = 5;
console.log(num); // 5
for(let i = 0; i < 10; i++)
{
let num = i;
console.log('--');
console.log(num); // num becomes 0 — 9
}
console.log('--');
console.log(num); // 5
console.log(i); // undefined, ReferenceError
}
Looking at the const keyword, you can see that we attain an error if we try to reassign to it:
const c = 299792458; // Fact: The constant "c" is the speed of light in a vacuum in meters per second.
c = 10; // TypeError: Assignment to constant variable.
Things become interesting when we assign a const variable to an object:
const myObject = {
name: 'Jane Doe'
};
// This is illegal: TypeError: Assignment to constant variable.
myObject = {
name: 'John Doe'
};
// This is legal. console.log(myObject.name) -> John Doe
myObject.name = 'John Doe';
As you can see, only the reference in memory to the object assigned to a const object is immutable, not the value its self.
ES6 Arrow Functions
You might be used to creating a function like this:
function printHelloWorld() {
console.log('Hello, World!');
}
Suppose we have a simple function that returns the square of a number:
const squareNumber = (x) => {
return x * x;
}
squareNumber(5); // We can call an arrow function like an ES5 functions. Returns 25.
You can see that, just like with ES5 functions, we can take in arguments with parentheses, we can use normal return statements, and we can call the function just like any other.
It’s important to note that, while parentheses are required if our function takes no arguments (like with printHelloWorld() above), we can drop the parentheses if it only takes one, so our earlier squareNumber() method definition can be rewritten as:
const squareNumber = x => { // Notice we have dropped the parentheses for we only take in one argument.
return x * x;
}
Whether you choose to encapsulate a single argument in parentheses or not is a matter of personal taste, and you will likely see developers use both methods.
Finally, if we only want to implicitly return one expression, as with squareNumber(...) above, we can put the return statement in line with the method signature:
const squareNumber = x => x * x;
That is,
const test = (a, b, c) => expression
is the same as
const test = (a, b, c) => { return expression }
Note, when using the above shorthand to implicitly return an object, things become obscure. What stops JavaScript from believing the brackets within which we are required to encapsulate our object is not our function body? To get around this, we wrap the object’s brackets in parentheses. This explicitly lets JavaScript know that we are indeed returning an object, and we are not just defining a body.
const test = () => ({ pi: 3.14 }); // Spaces between brackets are a formality to make the code look cleaner.
To help solidify the concept of ES6 functions, we’ll refactor some of our earlier code allowing us to compare the differences between both notations.
asyncAddFunction(...), from above, could be refactored from:
function asyncAddFunction(a, b, callback){
callback(a + b);
}
const aysncAddFunction = (a, b, callback) => callback(a + b); // This will return callback(a + b).
When calling the function, we could pass an arrow function in for the callback:
asyncAddFunction(10, 12, sum => { // No parentheses because we only take one argument.
console.log(sum);
}
It is clear to see how this method improves code readability. To show you just one case, we can take our old ES5 Promise based example above, and refactor it to use arrow functions.
Now, there are some caveats with arrow functions. For one, they do not bind a this keyword. Suppose I have the following object:
const Person = {
name: 'John Doe',
greeting: () => {
console.log(`Hi. My name is ${this.name}.`);
}
}
You might expect a call to Person.greeting() will return “Hi. My name is John Doe.” Instead, we get: “Hi. My name is undefined.” That is because arrow functions do not have a this, and so attempting to use this inside an arrow function defaults to the this of the enclosing scope, and the enclosing scope of the Person object is window, in the browser, or module.exports in Node.
To prove this, if we use the same object again, but set the name property of the global this to something like ‘Jane Doe’, then this.name in the arrow function returns ‘Jane Doe’, because the global this is within the enclosing scope, or is the parent of the Person object.
this.name = 'Jane Doe';
const Person = {
name: 'John Doe',
greeting: () => {
console.log(`Hi. My name is ${this.name}.`);
}
}
Person.greeting(); // Hi. My name is Jane Doe
This is known as ‘Lexical Scoping’, and we can get around it by using the so-called ‘Short Syntax’, which is where we lose the colon and the arrow as to refactor our object as such:
const Person = {
name: 'John Doe',
greeting() {
console.log(`Hi. My name is ${this.name}.`);
}
}
Person.greeting() //Hi. My name is John Doe.
ES6 Classes
While JavaScript never supported classes, you could always emulate them with objects like the above. EcmaScript 6 provides support for classes using the class and new keywords:
class Person {
constructor(name) {
this.name = name;
}
greeting() {
console.log(`Hi. My name is ${this.name}.`);
}
}
const person = new Person(‘John’);
person.greeting(); // Hi. My name is John.
The constructor function gets called automatically when using the new keyword, into which we can pass arguments to initially set up the object. This should be familiar to any reader who has experience with more statically typed object-oriented programming languages like Java, C++, and C#.
Without going into too much detail about OOP concepts, another such paradigm is “inheritance”, which is to allow one class to inherit from another. A class called Car, for example, will be very general — containing such methods as “stop”, “start”, etc., as all cars need. A sub-set of the class called SportsCar, then, might inherit fundamental operations from Car and override anything it needs custom. We could denote such a class as follows:
class Car {
constructor(licensePlateNumber) {
this.licensePlateNumber = licensePlateNumber;
}
start() {}
stop() {}
getLicensePlate() {
return this.licensePlateNumber;
}
// …
}
class SportsCar extends Car {
constructor(engineRevCount, licensePlateNumber) {
super(licensePlateNumber); // Pass licensePlateNumber up to the parent class.
this.engineRevCount = engineRevCount;
}
start() {
super.start();
}
stop() {
super.stop();
}
getLicensePlate() {
return super.getLicensePlate();
}
getEngineRevCount() {
return this.engineRevCount;
}
}
You can clearly see that the super keyword allows us to access properties and methods from the parent, or super, class.
JavaScript Events
An Event is an action that occurs to which you have the ability to respond. Suppose you are building a login form for your application. When the user presses the “submit” button, you can react to that event via an “event handler” in your code — typically a function. When this function is defined as the event handler, we say we are “registering an event handler”. The event handler for the submit button click will likely check the formatting of the input provided by the user, sanitize it to prevent such attacks as SQL Injections or Cross Site Scripting (please be aware that no code on the client-side can ever be considered safe. Always sanitize data on the server — never trust anything from the browser), and then check to see if that username and password combination exits within a database to authenticate a user and serve them a token.
Since this is an article about Node, we’ll focus on the Node Event Model.
We can use the events module from Node to emit and react to specific events. Any object that emits an event is an instance of the EventEmitter class.
We can emit an event by calling the emit() method and we listen for that event via the on() method, both of which are exposed through the EventEmitter class.
const EventEmitter = require('events');
const myEmitter = new EventEmitter();
With myEmitter now an instance of the EventEmitter class, we can access emit() and on():
const EventEmitter = require('events');
const myEmitter = new EventEmitter();
myEmitter.on('someEvent', () => {
console.log('The "someEvent" event was fired (emitted)');
});
myEmitter.emit('someEvent'); // This will call the callback function above.
The second parameter to myEmitter.on() is the callback function that will fire when the event is emitted — this is the event handler. The first parameter is the name of the event, which can be anything we like, although the camelCase naming convention is recommended.
Additionally, the event handler can take any number of arguments, which are passed down when the event is emitted:
const EventEmitter = require('events');
const myEmitter = new EventEmitter();
myEmitter.on('someEvent', (data) => {
console.log(`The "someEvent" event was fired (emitted) with data: ${data}`);
});
myEmitter.emit('someEvent', 'This is the data payload');
By using inheritance, we can expose the emit() and on() methods from ‘EventEmitter’ to any class. This is done by creating a Node.js class, and using the extends reserved keyword to inherit the properties available on EventEmitter:
const EventEmitter = require('events');
class MyEmitter extends EventEmitter {
// This is my class. I can emit events from a MyEmitter object.
}
Suppose we are building a vehicle collision notification program that receives data from gyroscopes, accelerometers, and pressure gauges on the car’s hull. When a vehicle collides with an object, those external sensors will detect the crash, executing the collide(...) function and passing to it the aggregated sensor data as a nice JavaScript Object. This function will emit a collision event, notifying the vendor of the crash.
This is a convoluted example for we could just put the code within the event handler inside the collide function of the class, but it demonstrates how the Node Event Model functions nonetheless. Note that some tutorials will show the util.inherits() method of permitting an object to emit events. That has been deprecated in favor of ES6 Classes and extends.
The Node Package Manager
When programming with Node and JavaScript, it’ll be quite common to hear about npm. Npm is a package manager which does just that — permits the downloading of third-party packages that solve common problems in JavaScript. Other solutions, such as Yarn, Npx, Grunt, and Bower exist as well, but in this section, we’ll focus only on npm and how you can install dependencies for your application through a simple Command Line Interface (CLI) using it.
Let’s start simple, with just npm. Visit the NpmJS homepage to view all of the packages available from NPM. When you start a new project that will depend on NPM Packages, you’ll have to run npm init through the terminal in your project’s root directory. You will be asked a series of questions which will be used to create a package.json file. This file stores all of your dependencies — modules that your application depends on to function, scripts — pre-defined terminal commands to run tests, build the project, start the development server, etc., and more.
To install a package, simply run npm install [package-name] --save. The save flag will ensure the package and its version is logged in the package.json file. Since npm version 5, dependencies are saved by default, so --save may be omitted. You will also notice a new node_modules folder, containing the code for that package you just installed. This can also be shortened to just npm i [package-name]. As a helpful note, the node_modules folder should never be included in a GitHub repository due to its size. Whenever you clone a repo from GitHub (or any other version management system), be sure to run the command npm install to go out and fetch all the packages defined in the package.json file, creating the node_modules directory automatically. You can also install a package at a specific version: npm i [package-name]@1.10.1 --save, for example.
Removing a package is similar to installing one: npm remove [package-name].
You can also install a package globally. This package will be available across all projects, not just the one your working on. You do this with the -g flag after npm i [package-name]. This is commonly used for CLIs, such as Google Firebase and Heroku. Despite the ease this method presents, it is generally considered bad practice to install packages globally, for they are not saved in the package.json file, and if another developer attempts to use your project, they won’t attain all the required dependencies from npm install.
APIs & JSON
APIs are a very common paradigm in programming, and even if you are just starting out in your career as a developer, APIs and their usage, especially in web and mobile development, will likely come up more often than not.
An API is an Application Programming Interface, and it is basically a method by which two decoupled systems may communicate with each other. In more technical terms, an API permits a system or computer program (usually a server) to receive requests and send appropriate responses (to a client, also known as a host).
Suppose you are building a weather application. You need a way to geocode a user’s address into a latitude and longitude, and then a way to attain the current or forecasted weather at that particular location.
As a developer, you want to focus on building your app and monetizing it, not putting the infrastructure in place to geocode addresses or placing weather stations in every city.
Luckily for you, companies like Google and OpenWeatherMap have already put that infrastructure in place, you just need a way to talk to it — that is where the API comes in. While, as of now, we have developed a very abstract and ambiguous definition of the API, bear with me. We’ll be getting to tangible examples soon.
Now, it costs money for companies to develop, maintain, and secure that aforementioned infrastructure, and so it is common for corporations to sell you access to their API. This is done with that is known as an API key, a unique alphanumeric identifier associating you, the developer, with the API. Every time you ask the API to send you data, you pass along your API key. The server can then authenticate you and keep track of how many API calls you are making, and you will be charged appropriately. The API key also permits Rate-Limiting or API Call Throttling (a method of throttling the number of API calls in a certain timeframe as to not overwhelm the server, preventing DOS attacks — Denial of Service). Most companies, however, will provide a free quota, giving you, as an example, 25,000 free API calls a day before charging you.
Up to this point, we have established that an API is a method by which two computer programs can communicate with each other. If a server is storing data, such as a website, and your browser makes a request to download the code for that site, that was the API in action.
Let us look at a more tangible example, and then we’ll look at a more real-world, technical one. Suppose you are eating out at a restaurant for dinner. You are equivalent to the client, sitting at the table, and the chef in the back is equivalent to the server.
Since you will never directly talk to the chef, there is no way for him/her to receive your request (for what order you would like to make) or for him/her to provide you with your meal once you order it. We need someone in the middle. In this case, it’s the waiter, analogous to the API. The API provides a medium with which you (the client) may talk to the server (the chef), as well as a set of rules for how that communication should be made (the menu — one meal is allowed two sides, etc.)
Now, how do you actually talk to the API (the waiter)? You might speak English, but the chef might speak Spanish. Is the waiter expected to know both languages to translate? What if a third person comes in who only speaks Mandarin? What then? Well, all clients and servers have to agree to speak a common language, and in computer programming, that language is JSON, pronounced JAY-sun, and it stands for JavaScript Object Notation.
At this point, we don’t quite know what JSON looks like. It’s not a computer programming language, it’s just, well, a language, like English or Spanish, that everyone (everyone being computers) understands on a guaranteed basis. It’s guaranteed because it’s a standard, notably RFC 8259, the JavaScript Object Notation (JSON) Data Interchange Format by the Internet Engineering Task Force (IETF).
Even without formal knowledge of what JSON actually is and what it looks like (we’ll see in an upcoming article in this series), we can go ahead introduce a technical example operating on the Internet today that employs APIs and JSON. APIs and JSON are not just something you can choose to use, it’s not equivalent to one out of a thousand JavaScript frameworks you can pick to do the same thing. It is THE standard for data exchange on the web.
Suppose you are building a travel website that compares prices for aircraft, rental car, and hotel ticket prices. Let us walk through, step-by-step, on a high level, how we would build such an application. Of course, we need our User Interface, the front-end, but that is out of scope for this article.
We want to provide our users with the lowest price booking method. Well, that means we need to somehow attain all possible booking prices, and then compare all of the elements in that set (perhaps we store them in an array) to find the smallest element (known as the infimum in mathematics.)
How will we get this data? Well, suppose all of the booking sites have a database full of prices. Those sites will provide an API, which exposes the data in those databases for use by you. You will call each API for each site to attain all possible booking prices, store them in your own array, find the lowest or minimum element of that array, and then provide the price and booking link to your user. We’ll ask the API to query its database for the price in JSON, and it will respond with said price in JSON to us. We can then use, or parse, that accordingly. We have to parse it because APIs will return JSON as a string, not the actual JavaScript data type of JSON. This might not make sense now, and that’s okay. We’ll be covering it more in a future article.
Also, note that just because something is called an API does not necessarily mean it operates on the web and sends and receives JSON. The Java API, for example, is just the list of classes, packages, and interfaces that are part of the Java Development Kit (JDK), providing programming functionality to the programmer.
Okay. We know we can talk to a program running on a server by way of an Application Programming Interface, and we know that the common language with which we do this is known as JSON. But in the web development and networking world, everything has a protocol. What do we actually do to make an API call, and what does that look like code-wise? That’s where HTTP Requests enter the picture, the HyperText Transfer Protocol, defining how messages are formatted and transmitted across the Internet. Once we have an understanding of HTTP (and HTTP verbs, you’ll see that in the next section), we can look into actual JavaScript frameworks and methods (like fetch()) offered by the JavaScript API (similar to the Java API), that actually allow us to make API calls.
HTTP And HTTP Requests
HTTP is the HyperText Transfer Protocol. It is the underlying protocol that determines how messages are formatted as they are transmitted and received across the web. Let’s think about what happens when, for example, you attempt to load the home page of Smashing Magazine in your web browser.
You type the website URL (Uniform Resource Locator) in the URL bar, where the DNS server (Domain Name Server, out of scope for this article) resolves the URL into the appropriate IP Address. The browser makes a request, called a GET Request, to the Web Server to, well, GET the underlying HTML behind the site. The Web Server will respond with a message such as “OK”, and then will go ahead and send the HTML down to the browser where it will be parsed and rendered accordingly.
There are a few things to note here. First, the GET Request, and then the “OK” response. Suppose you have a specific database, and you want to write an API to expose that database to your users. Suppose the database contains books the user wants to read (as it will in a future article in this series). Then there are four fundamental operations your user may want to perform on this database, that is, Create a record, Read a record, Update a record, or Delete a record, known collectively as CRUD operations.
Let’s look at the Read operation for a moment. Without incorrectly assimilating or conflating the notion of a web server and a database, that Read operation is very similar to your web browser attempting to get the site from the server, just as to read a record is to get the record from the database.
This is known as an HTTP Request. You are making a request to some server somewhere to get some data, and, as such, the request is appropriately named “GET”, capitalization being a standard way to denote such requests.
What about the Create portion of CRUD? Well, when talking about HTTP Requests, that is known as a POST request. Just as you might post a message on a social media platform, you might also post a new record to a database.
CRUD’s Update allows us to use either a PUT or PATCH Request in order to update a resource. HTTP’s PUT will either create a new record or will update/replace the old one.
Let’s look at this a bit more in detail, and then we’ll get to PATCH.
An API generally works by making HTTP requests to specific routes in a URL. Suppose we are making an API to talk to a DB containing a user’s booklist. Then we might be able to view those books at the URL .../books. A POST requests to .../books will create a new book with whatever properties you define (think id, title, ISBN, author, publishing data, etc.) at the .../books route. It doesn’t matter what the underlying data structure is that stores all the books at .../books right now. We just care that the API exposes that endpoint (accessed through the route) to manipulate data. The prior sentence was key: A POST request creates a new book at the ...books/ route. The difference between PUT and POST, then, is that PUT will create a new book (as with POST) if no such book exists, or, it will replace an existing book if the book already exists within that aforementioned data structure.
Suppose each book has the following properties: id, title, ISBN, author, hasRead (boolean).
Then to add a new book, as seen earlier, we would make a POST request to .../books. If we wanted to completely update or replace a book, we would make a PUT request to .../books/id where id is the ID of the book we want to replace.
While PUT completely replaces an existing book, PATCH updates something having to do with a specific book, perhaps modifying the hasRead boolean property we defined above — so we’d make a PATCH request to …/books/id sending along the new data.
It can be difficult to see the meaning of this right now, for thus far, we’ve established everything in theory but haven’t seen any tangible code that actually makes an HTTP request. We shall, however, get to that soon, covering GET in this article, ad the rest in a future article.
There is one last fundamental CRUD operation and it’s called Delete. As you would expect, the name of such an HTTP Request is “DELETE”, and it works much the same as PATCH, requiring the book’s ID be provided in a route.
We have learned thus far, then, that routes are specific URLs to which you make an HTTP Request, and that endpoints are functions the API provides, doing something to the data it exposes. That is, the endpoint is a programming language function located on the other end of the route, and it performs whatever HTTP Request you specified. We also learned that there exist such terms as POST, GET, PUT, PATCH, DELETE, and more (known as HTTP verbs) that actually specify what requests you are making to the API. Like JSON, these HTTP Request Methods are Internet standards as defined by the Internet Engineering Task Force (IETF), most notably, RFC 7231, Section Four: Request Methods, and RFC 5789, Section Two: Patch Method, where RFC is an acronym for Request for Comments.
So, we might make a GET request to the URL .../books/id where the ID passed in is known as a parameter. We could make a POST, PUT, or PATCH request to .../books to create a resource or to .../books/id to modify/replace/update a resource. And we can also make a DELETE request to .../books/id to delete a specific book.
A full list of HTTP Request Methods can be found here.
It is also important to note that after making an HTTP Request, we’ll receive a response. The specific response is determined by how we build the API, but you should always receive a status code. Earlier, we said that when your web browser requests the HTML from the web server, it’ll respond with “OK”. That is known as an HTTP Status Code, more specifically, HTTP 200 OK. The status code just specifies how the operation or action specified in the endpoint (remember, that’s our function that does all the work) completed. HTTP Status Codes are sent back by the server, and there are probably many you are familiar with, such as 404 Not Found (the resource or file could not be found, this would be like making a GET request to .../books/id where no such ID exists.)
A complete list of HTTP Status Codes can be found here.
MongoDB
MongoDB is a non-relational, NoSQL database similar to the Firebase Real-time Database. You will talk to the database via a Node package such as the MongoDB Native Driver or Mongoose.
In MongoDB, data is stored in JSON, which is quite different from relational databases such as MySQL, PostgreSQL, or SQLite. Both are called databases, with SQL Tables called Collections, SQL Table Rows called Documents, and SQL Table Columns called Fields.
We will use the MongoDB Database in an upcoming article in this series when we create our very first Bookshelf API. The fundamental CRUD Operations listed above can be performed on a MongoDB Database.
It’s recommended that you read through the MongoDB Docs to learn how to create a live database on an Atlas Cluster and make CRUD Operations to it with the MongoDB Native Driver. In the next article of this series, we will learn how to set up a local database and a cloud production database.
Building A Command Line Node Application
When building out an application, you will see many authors dump their entire code base at the beginning of the article, and then attempt to explain each line thereafter. In this text, I’ll take a different approach. I’ll explain my code line-by-line, building the app as we go. I won’t worry about modularity or performance, I won’t split the codebase into separate files, and I won’t follow the DRY Principle or attempt to make the code reusable. When just learning, it is useful to make things as simple as possible, and so that is the approach I will take here.
Let us be clear about what we are building. We won’t be concerned with user input, and so we won’t make use of packages like Yargs. We also won’t be building our own API. That will come in a later article in this series when we make use of the Express Web Application Framework. I take this approach as to not conflate Node.js with the power of Express and APIs since most tutorials do. Rather, I’ll provide one method (of many) by which to call and receive data from an external API which utilizes a third-party JavaScript library. The API we’ll be calling is a Weather API, which we’ll access from Node and dump its output to the terminal, perhaps with some formatting, known as “pretty-printing”. I’ll cover the entire process, including how to set up the API and attain API Key, the steps of which provide the correct results as of January 2019.
We’ll be using the OpenWeatherMap API for this project, so to get started, navigate to the OpenWeatherMap sign-up page and create an account with the form. Once logged in, find the API Keys menu item on the dashboard page (located over here). If you just created an account, you’ll have to pick a name for your API Key and hit “Generate”. It could take at least 2 hours for your new API Key to be functional and associated with your account.
Before we start building out the application, we’ll visit the API Documentation to learn how to format our API Key. In this project, we’ll be specifying a zip code and a country code to attain the weather information at that location.
From the docs, we can see that the method by which we do this is to provide the following URL:
For now, copy that URL into a new tab in your web browser, replacing the {YOUR_API_KEY} placeholder with the API Key you obtained earlier when you registered for an account.
The text you can see is actually JSON — the agreed upon language of the web as discussed earlier.
To inspect this further, hit Ctrl + Shift + I in Google Chrome to open the Chrome Developer tools, and then navigate to the Network tab. At present, there should be no data here.
The empty Google Chrome Developer Tools(Large preview)
To actually monitor network data, reload the page, and watch the tab be populated with useful information. Click the first link as depicted in the image below.
The populated Google Chrome Developer Tools (Large preview)
Once you click on that link, we can actually view HTTP specific information, such as the headers. Headers are sent in the response from the API (you can also, in some cases, send your own headers to the API, or you can even create your own custom headers (often prefixed with x-) to send back when building your own API), and just contain extra information that either the client or server may need.
In this case, you can see that we made an HTTP GET Request to the API, and it responded with an HTTP Status 200 OK. You can also see that the data sent back was in JSON, as listed under the “Response Headers” section.
Headers in the response from the API (Large preview)
If you hit the preview tab, you can actually view the JSON as a JavaScript Object. The text version you can see in your browser is a string, for JSON is always transmitted and received across the web as a string. That’s why we have to parse the JSON in our code, to get it into a more readable format — in this case (and in pretty much every case) — a JavaScript Object.
You can also use the Google Chrome Extension “JSON View” to do this automatically.
To start building out our application, I’ll open a terminal and make a new root directory and then cd into it. Once inside, I’ll create a new app.js file, run npm init to generate a package.json file with the default settings, and then open Visual Studio Code.
Thereafter, I’ll download Axios, verify it has been added to my package.json file, and note that the node_modules folder has been created successfully.
In the browser, you can see that we made a GET Request by hand by manually typing the proper URL into the URL Bar. Axios is what will allow me to do that inside of Node.
Starting now, all of the following code will be located inside of the app.js file, each snippet placed one after the other.
The first thing I’ll do is require the Axios package we installed earlier with
const axios = require('axios');
We now have access to Axios, and can make relevant HTTP Requests, via the axios constant.
Generally, our API calls will be dynamic — in this case, we might want to inject different zip codes and country codes into our URL. So, I’ll be creating constant variables for each part of the URL, and then put them together with ES6 Template Strings. First, we have the part of our URL that will never change as well as our API Key:
I’ll also assign our zip code and country code. Since we are not expecting user input and are rather hard coding the data, I’ll make these constant as well, although, in many cases, it will be more useful to use let.
All that is left to do is to actually use axios to make a GET Request to that URL. For that, we’ll use the get(url) method provided by axios.
axios.get(ENTIRE_API_URL)
axios.get(...) actually returns a Promise, and the success callback function will take in a response argument which will allow us to access the response from the API — the same thing you saw in the browser. I’ll also add a .catch() clause to catch any errors.
If we now run this code with node app.js in the terminal, you will be able to see the full response we get back. However, suppose you just want to see the temperature for that zip code — then most of that data in the response is not useful to you. Axios actually returns the response from the API in the data object, which is a property of the response. That means the response from the server is actually located at response.data, so let’s print that instead in the callback function: console.log(response.data).
Now, we said that web servers always deal with JSON as a string, and that is true. You might notice, however, that response.data is already an object (evident by running console.log(typeof response.data)) — we didn’t have to parse it with JSON.parse(). That is because Axios already takes care of this for us behind the scenes.
The output in the terminal from running console.log(response.data) can be formatted — “pretty-printed” — by running console.log(JSON.stringify(response.data, undefined, 2)). JSON.stringify() converts a JSON object into a string, and take in the object, a filter, and the number of characters by which to indent by when printing. You can see the response this provides:
Now, it is clear to see that the temperature we are looking for is located on the main property of the response.data object, so we can access it by calling response.data.main.temp. Let’s look at out application’s code up to now:
The temperature we get back is actually in Kelvin, which is a temperature scale generally used in Physics, Chemistry, and Thermodynamics due to the fact that it provides an “absolute zero” point, which is the temperature at which all thermal motion of all inner particles cease. We just need to convert this to Fahrenheit or Celcius with the formulas below:
F = K * 9/5 — 459.67C = K — 273.15
Let’s update our success callback to print the new data with this conversion. We’ll also add in a proper sentence for the purposes of User Experience:
axios.get(ENTIRE_API_URL)
.then(response => {
// Getting the current temperature and the city from the response object.
const kelvinTemperature = response.data.main.temp;
const cityName = response.data.name;
const countryName = response.data.sys.country;
// Making K to F and K to C conversions.
const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67;
const celciusTemperature = kelvinTemperature — 273.15;
// Building the final message.
const message = (
`Right now, in \
${cityName}, ${countryName} the current temperature is \
${fahrenheitTemperature.toFixed(2)} deg F or \
${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ')
);
console.log(message);
})
.catch(error => console.log('Error', error));
The parentheses around the message variable are not required, they just look nice — similar to when working with JSX in React. The backslashes stop the template string from formatting a new line, and the replace() String prototype method gets rid of white space using Regular Expressions (RegEx). The toFixed() Number prototype methods rounds a float to a specific number of decimal places — in this case, two.
With that, our final app.js looks as follows:
const axios = require('axios');
// API specific settings.
const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip=';
const API_KEY = 'Your API Key Here';
const LOCATION_ZIP_CODE = '90001';
const COUNTRY_CODE = 'us';
const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`;
axios.get(ENTIRE_API_URL)
.then(response => {
// Getting the current temperature and the city from the response object.
const kelvinTemperature = response.data.main.temp;
const cityName = response.data.name;
const countryName = response.data.sys.country;
// Making K to F and K to C conversions.
const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67;
const celciusTemperature = kelvinTemperature — 273.15;
// Building the final message.
const message = (
`Right now, in \
${cityName}, ${countryName} the current temperature is \
${fahrenheitTemperature.toFixed(2)} deg F or \
${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ')
);
console.log(message);
})
.catch(error => console.log('Error', error));
Conclusion
We have learned a lot about how Node works in this article, from the differences between synchronous and asynchronous requests, to callback functions, to new ES6 features, events, package managers, APIs, JSON, and the HyperText Transfer Protocol, Non-Relational Databases, and we even built our own command line application utilizing most of that new found knowledge.
In future articles in this series, we’ll take an in-depth look at the Call Stack, the Event Loop, and Node APIs, we’ll talk about Cross-Origin Resource Sharing (CORS), and we’ll build a Full Stack Bookshelf API utilizing databases, endpoints, user authentication, tokens, server-side template rendering, and more.
From here, start building your own Node applications, read the Node documentation, go out and find interesting APIs or Node Modules and implement them yourself. The world is your oyster and you have at your fingertips access to the largest network of knowledge on the planet — the Internet. Use it to your advantage.
With the Super Bowl now over, surely your attention has now switched to how to view large amounts of unformatted JSON in an effective way.
Ok, maybe your attention hasn't been directed that way, but, ask yourself how many times as a web developer have you had to view a raw dump of an entire JSON document? I mean the kind that is tens of thousands of kilobytes large (or more!); most likely for debugging or tracking a setting down.
This blog is the first installation in a series of security-centered articles that are intended to help Django developers secure their deployments. In this piece, I wish to talk about the security setup required for the secure use of JSON Web Token, an authorization mechanism used while transferring information in REST Frameworks such as Django REST-APIs
With business needs demanding more from web applications, product teams have moved towards light-weight application development for scalability and efficiency. This usually includes building applications that use RESTful web services, which use an Application Programming Interface (API) to interact with other applications and web services. One such popular web framework that supports such an architecture is the Django web framework.
As a follow up to my previous webcast on the subject of Relational to NoSQL database, I discussed that we are in the third phase of the NoSQL adoption, the “Broad Replatforming” of Enterprise Application. I want to provide an example in this article on how an application can leverage JSON data model and Couchbase N1QL (a SQL++ Implementation) to address the complex data visibility rule of a CRM Application.
Overview
One critical aspect in a CRM application, but one that is often overlooked, is the activity management process. To manage the customer relationship, and to do so effectively, the application needs to keep track of all the activities directly or indirectly associated to the task of relationship management. A CRM activity captures all the interactions that a business has with its customers throughout the entire relationship. It is also used to record different activities that are in the CRM system, some of which may not be directly associated to the accounts, such as the lead generation process, quota management, and order fulfillment. It is also used by the Marketing campaign and Services to track all the support activities.
Understanding API-Based Platforms: A Guide For Product Managers
Understanding API-Based Platforms: A Guide For Product Managers
Michał Sędzielewski
To build a digital product today is to integrate the myriad of various back-office systems with customer touchpoints and devices. The cost of engaging a software team to connect them in a single working solution might sky-rocket.
This is why modern product managers, when choosing vendors, often put integration capabilities in the first place which may come down to choosing systems exposing API. What’s the API and how to test it without engaging your tech team? Read on.
Embrace The Data: Why We Need APIs At All
Customer data change how the business operates. If properly collected and shifted around, they can help companies shoot up customer acquisition and retention rates, leading eventually to a burst in income.
But data crunching is a tedious job. That’s why business tapped into computer science. In the 1990s, the databases which automated the most time-consuming data tasks became massively popular across marketing departments. This led to a massive shift in how marketing strategies were conceived — that shift was called the data-driven approach.
Databases had a major con, though. To make them something of value, a company needed to hire software engineers. They were the heroes who knew how to turn huge piles of data into working insights. They were also the guards protecting data integrity and thus making sure the system was future-proof.
But software engineers cost a lot, and their communication interface required effort.
When the number of data collection channels spanned over several departments and even external companies, databases and their operators became a bottleneck. Businesses needed to find an automated way of accessing data stores.
This is how the idea of API-first systems originated.
What The API Actually Is Without The Tech Lingo
API-first systems, today commonly shortened as API (Application Programmable Interface), are the applications which ensure that other systems can access their data in a unified and secure way.
Without a computer science grade, Application Programmable Interface doesn’t really ring a bell. Let’s have a look at a more tangible explanation.
One of the best analogies I’ve found in the web so far has been written by Taija:
“If you go to a restaurant as a customer, you are not allowed to enter the kitchen. You need to know what is available. For that, you have the menu. After looking at the menu, you make an order to a waiter, who passes it to the kitchen and who will then deliver what you have asked for. The waiter can only deliver what the kitchen can provide.
Best API analogy I've seen: take a restaurant. The menu is the API, your order is the API call, the food from the kitchen is the response.
How does that relate to an API? The waiter is the API. You are someone who is asking for service. In other words, you are an API customer or consumer. The menu is the documentation which explains what you can ask for from the API. The kitchen is, for example, a server; a database that holds only a certain type of data — whatever the buyer has bought for the restaurant as ingredients and what the chef has decided they will offer and what the cooks know how to prepare.”
So again:
Kitchen
The database, no customers allowed to protect data integrity.
Waiter
The API, a middleman that knows how to serve data from the database without disrupting its functioning.
Customer
An external system that wants to get their data
Menu
The data format reference the external systems have to use to perform their operation.
Order
An actual single API call.
With the current state of technology, it still takes a software developer to “make an order.” But it’s way faster (read: cheaper) because the menu, like McDonald’s, is more or less standardized across the world.
So now, we’re going to wear a software developer’s shoes and try to call an exemplary API. Don’t worry; we’re not going to go beyond school computer science classes.
How Your Weather App Gets The Data: API Basics
We’re going to find out how your weather app knows the current temperature. In this way, we’ll get the basics of how to communicate with systems over the internet.
What we need:
A weather database
A browser
A dash of willpower
That’s it! Today’s technology makes it easy to test the API without the need for big developer tools.
Of course, that’s different when you want to create a full-blown integration. When push comes to shove, you need to know more advanced tools and programming languages, but for testing/proof of concepts, this setup is enough.
So, let’s try to get the current temperature index for your city — or, in the parlance of coders — let’s invoke the first API call. After all, it boils down to sending some text to a server and receiving a message in exchange.
The Anatomy Of An API Request
In this article, we’ll be using the https://openweathermap.org API. Visit the site and try checking weather conditions in several locations. Hopefully, you’re feeling better than me in Katowice today:
As you might have guessed, the website is calling the API to get the data. Developers implemented it in a way that every time you press search, behind the scenes the application knocks the API’s door and says “give me <city> temperature.”
Let’s put on a hacker hat and see the API calls this website is calling with your browser. You can use Developer Tools in your Browser to see what’s happening behind the scenes:
In Chrome, go to Menu → More tools → Developer Tools;
Switch to Network tab;
Try checking temperature in different cities in the widget above;
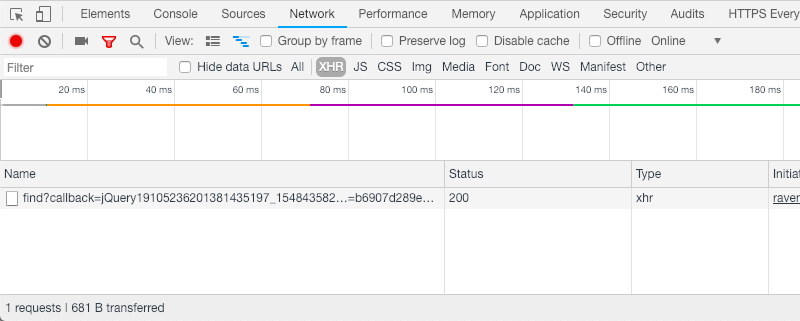
In the list on the bottom, you’ll notice links which have been called:
Requests monitor in Chrome Developer Tools (Large preview)
If you copy the link, you can see it includes the location name and a couple of other parameters.
The reply from the API is a data structure with information about the current weather conditions — you should easily decrypt most of the parameters. This format of data is called JSON. This is an important notation because most of modern APIs use it. This pile of idents and brackets serves one purpose — it’s easier for an application to parse a well-structured message than a randomly placed text.
A word of explanation of what we’ve just done here.
The web application behind the Open Weather Map website takes the data from the API and displays it on the website.
Every time you type the city name and press search, the website connects to a server with a specific link which includes the name of the city as a parameter.
The same sentence in the tech jargon: the application behind the website sends a request to an API endpoint providing the name of the city as an argument.
Then, the API replies (sends an API response) with a text message formatted as JSON.
To create an API request you need to put together its address. Yeah, the address is a good analogy. To ship something you need to provide the courier with:
City,
Street and number,
Sometimes some extra information on how to get to your office.
And, to connect to the API, by analogy, you need:
https://openweathermap.org/ (link)
The city or root-endpoint — a starting point, an internet address of a server you want to connect to, in our case.
data/2.5/find (link)
The street number or the path — determines the resource you want to get from an API.
?callback=jQuery19103887954878001505_1542285819413&q=Katowice&type=like&sort=population&cnt=30&appid=b6907d289e10d714a6e88b30761fae22&_=1542285819418 (link)
The extra info or the query parameters — let the API server know what we want to get in particular and what structure and order the data should have.
This is how APIs are designed. The root-endpoint usually stays the same for a single vendor, then you need to figure out what path and query parameters are available and what information the API development team put behind them.
Now let’s put the hacker hat a bit tighter. In our case, not all query parameters are necessary to get the weather data. Try removing different parameters after the question mark (?) and check how the Weather API replies.
For example, you can start by removing callback from the request link:
How do you know what’s mandatory and what’s optional? How do you know where to get the root-endpoint and path in the first place?
API Documentation: A Must-Read Before You Start
You always need to check the API documentation first to learn how to construct your request the right way.
In our case, the documentation https://openweathermap.org/current shows the available endpoints. It also explains all response data fields — so you can find what information the API will reply even before you even send a request.
A good API documentation offers quick start tutorials on how to create simple requests and moves on to more advanced stuff. Fortunately, the Open Weather API has one and we’re going to use it now.
Creating An API Call From Scratch
Let’s sum up our findings. We’ve already sent a request to the API. We’ve figured out the correct link by sniffing what OpenWeatherMap does behind the scenes. This approach is called reverse-engineering and it’s often hard or not possible at all.
Moreover, most of the times, API providers ban users from over-using this option. That’s why we should learn how to “call” the API by the rules (meaning — documentation).
One way to do this is to code it. But as we’re not coders (yet!), we’re going to use tools that make this easier. So much easier that even software developers have it under their toolbelt.
As promised, we won’t leave the browser. But we need to install an extension (Chrome only) — Postman. This simple plugin turns your browser into an API connector.
OK, now that we have a tool, let’s take a look into the documentation to see how we can get current weather conditions for a specific city name https://openweathermap.org/current#name.
The docs say we should use the following endpoint: api.openweathermap.org/data/2.5/weather?q={city name}
When we break it down we get the following elements:
Root-endpoint: api.openweathermap.org
Path: data/2.5/weather
Query parameter: q={city name} (this notion means that we should replace the braces with a specific city name)
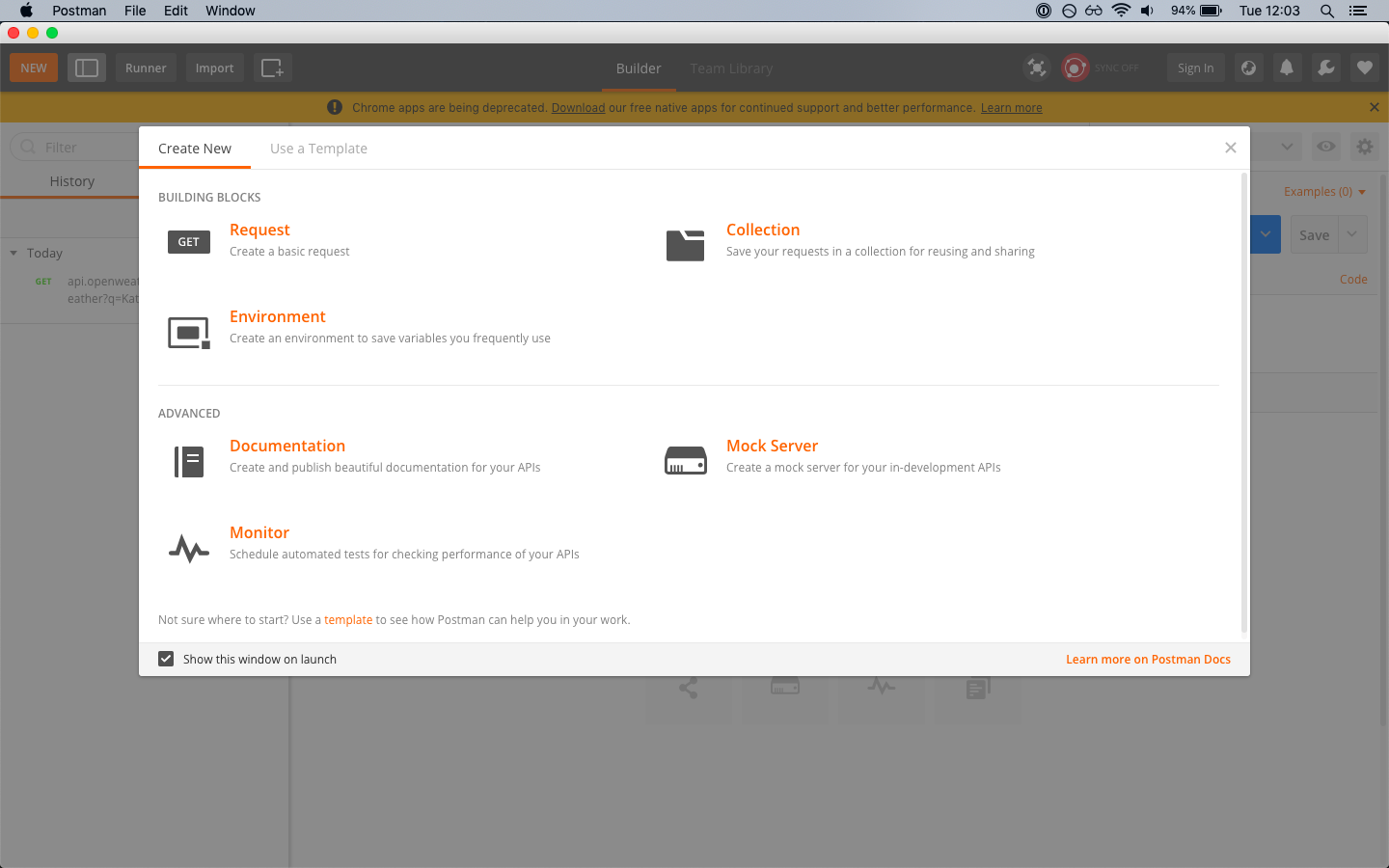
Let’s put it into Postman. The process boils down to three easy steps:
Click on ‘Request’ in the top menu.
Postman new request view (Large preview)
Name your request and provide the catalog name in the section at the bottom as well.
Postman request name view (Large preview)
Paste the API endpoint you want to call, click Send, and you should see the API response in the Response section:
Sending the first request with Postman (Large preview)
Congrats! You’ve just successfully called your fir… wait a second! Let’s pay attention to the API response:
It’s not a JSON filled with weather information we’ve seen before. What do the 401 and Invalid API key mean at all? Is our documentation wrong?
Authentication
You wouldn’t let anybody access your cocktail cabinet without your permission, would you? By the same token, API providers also want to control the users of their product to protect it from malicious activity. What’s malicious activity? For example, sending many API requests at the same time, which will “overheat” the server and cause downtime for other users.
How can you control the access? The same way as you guard your drinks! By using keys — API keys.
If you visit the How to start guide from Weather API documentation, you’ll notice how you can get your key. Sign up now and check your inbox.
So now the question is how to use the key? It’s easy, according to the docs, just copy and paste the key at the end of your endpoint URL (without braces).
api.openweathermap.org/data/2.5/weather?q=Katowice&appid={your API key}
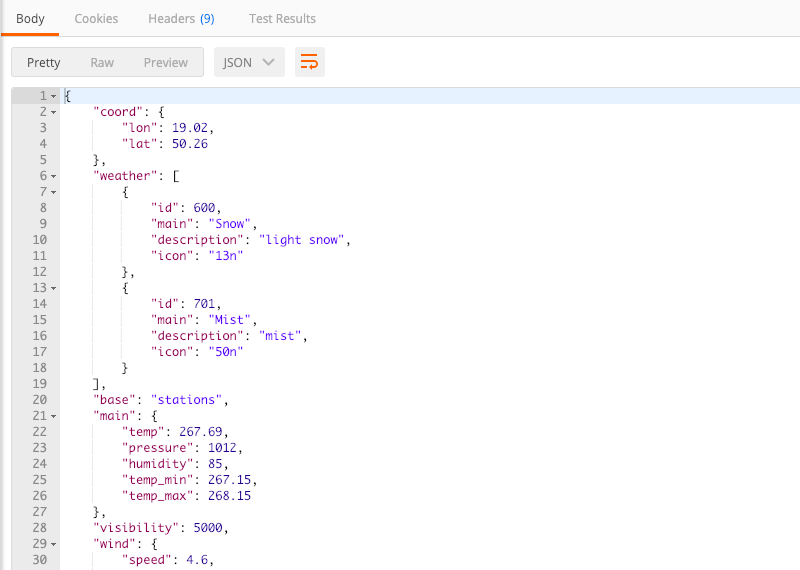
And click send again. Here you go, we can now see the API response! 🙌
Successful response from Open Weather Map API (Large preview)
But there’s much more you can get from the API using Postman. Ready to become a true API hacker?
API parameters: Getting Tailored Responses
Usually, API endpoints have some utility features you can use to adjust the API response, e.g. if you need a better data format or you want to get the data in a particular order. These options are often hidden behind some parameters you can find in the documentation.
Query parameters are just a structured text you add at the endpoint address with the following pattern:
A question mark (?) after the path,
Name of a parameter,
Equals (=) symbol,
Value of the parameter,
Ampersand (&) and others follow with points 2-4 (in this way you can add as many parameters as you want).
As mentioned, query params are described in API docs. The following excerpt from the weather API documentation shows you how to get the temperature in different units (imperial or metric):
OpenWeatherMap API documentation excerpt (Large preview)
Try sending these two options with Postman to see the difference in results. Remember to add your API key at the end of the endpoint address.
Note: Always take some time to study the documentation and find parameters which can save you or your development team some serious time.
API Request Options: How To Send Data To The API
So far, we’ve been getting information from the API. What if we want to add or modify information in the database behind the API? Request methods are the answer.
Let’s take a look at Postman once again. You might have noticed an upper-case GET label next to the API endpoint address. This represents one of four request methods. GET means we want to get something from the API (thanks captain) and it’s a default option. What are the other options?
Method Name
What it does with the API
GET
The API looks for the data you’ve requested and sends it back to you.
POST
The API creates a new entry in the database and tells you whether the creation is successful.
PUT
The API updates an entry in the database and tells you whether the update is successful.
DELETE
The API deletes an entry in the database and tells you whether the deletion is successful.
Still confusing? Let’s move to examples.
API POST: How To Create A Record In The API
We can’t create or update anything with Weather API (because it’s meant to be read-only), so we need to find a different one for testing purposes.
Let’s come up with some more business-oriented example. We’re going to simulate the following scenario:
If it’s rainy, create a “cheer up” discount coupon for your customers.
We’re going to use Voucherify which provides an API for creating and tracking promotions for any e-commerce system.
Disclaimer: I’m a co-founder of Voucherify. I’m happy to answer your questions about designing and implementing digital promotions, and about our API of course. 🖐
We already know how to get them from the previous example, so let’s focus on creating a voucher:
As we’ve said, we should always start with the documentation.
The quick start guide tells us to get our API key. Note: Instead of creating an account, you can use the test keys from the quick start guide — we’ll show you how in a minute.
Now, let’s find how to create a discount coupon. In Voucherify, this kind of promotion is represented as “voucher”.
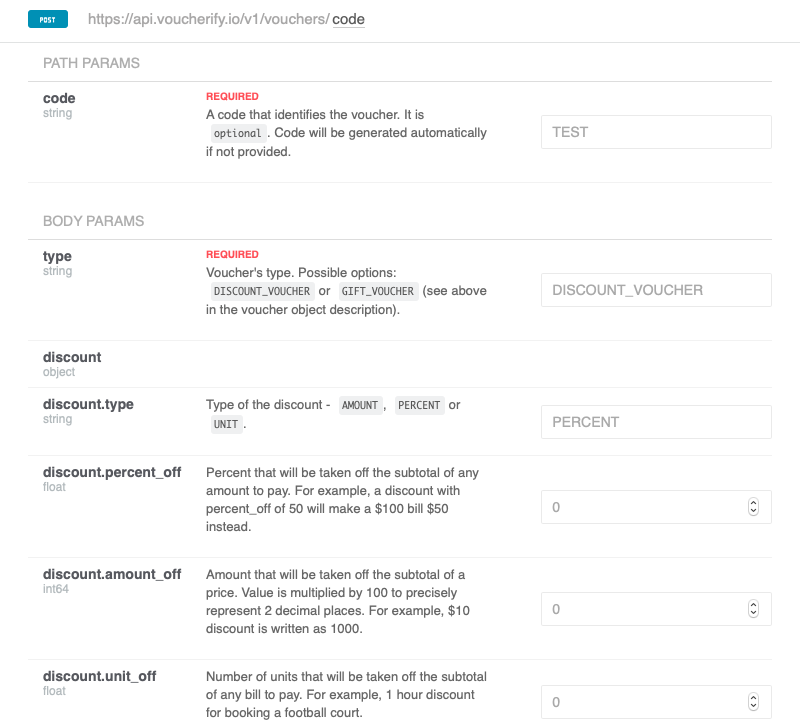
From the docs, you’ll learn that to create voucher, you need to call a POST method to /vouchers endpoint.
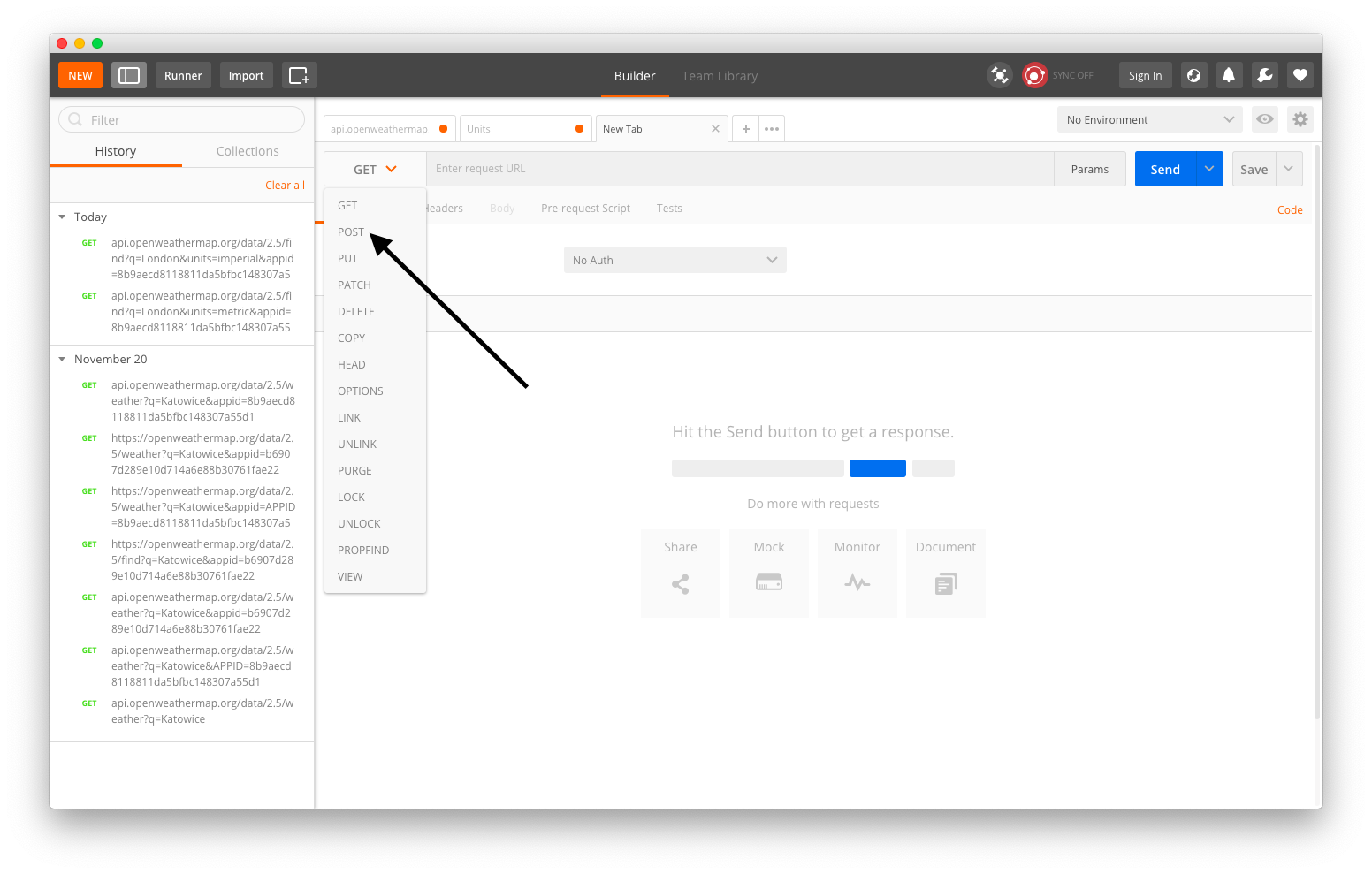
Create a new Request in Postman.
Change method to POST.
Postman - API methods selection (Large preview)
Oh snap, we’re not authorized to call this endpoint. As you might have guessed, we need to provide API keys.
Voucherify has a slightly different way of doing so. Instead of putting them as query params, you should put them to Headers. This is a common approach because it’s easier to implement and maintain keys this way rather than append them as query params.
Add the keys as in the picture and click Send. Notice that Voucherify requires two keys. Here the ones you can use for the purpose of this tutorial: X-App-Id: 8a824b12-0530-4ef4-9479-d9e9b9930176X-App-Token: 9e322bac-8297-49f7-94c8-07946724bcbc
Providing API keys in Postman (Large preview)
We get another error message, this time it says the payload cannot be empty.
Voucherify API returns error code 400 (Large preview)
What the heck is a payload? As in the case of GET we want to retrieve some information, with POST we need to send something and the message we send is called the payload and it’s usually a JSON file.
Now Voucherify API is complaining that we didn’t provide one, which means that it cannot create a voucher because we didn’t tell what kind of voucher it should create. So what now? Back to the docs!
Let’s find what kind of information this request needs to succeed. We can see a lot of options on the list.
Voucherify API documentation excerpt (Large preview)
One parameter (type) is required and another optional. Let’s say it’s going to be a 20% off discount, available for the first 100 customers, expiring today. Now we need to find parameters responsible for this discount features and put them together into a format understable to Voucherify API. As you can see in the examples above, the JSON notation you should use looks like this:
To set up the payload in Postman, paste the JSON message into Body tab. Select "raw" type and JSON from the list of available payload formats and confirm with Send.
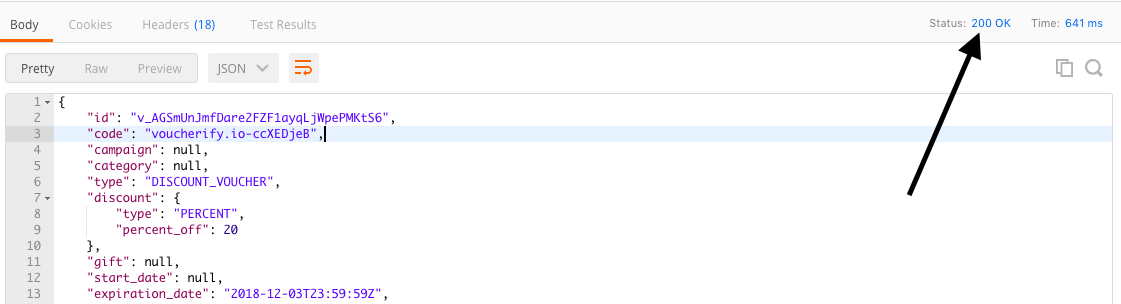
POST method in Postman (Large preview)
Voila! Voucherify has created our 20% off discount coupon successfully (as we’re working with a test account, all generated codes start with the "voucherify.io-" prefix). The marketing team can now share the code with customers and Voucherify will automatically validate it whenever they come to your shop to redeem it.
Voucherify returns 200 OK (Large preview)
But how do we know it is a successful request? First of all, we can see that Voucherify has sent us a message which, according to their docs, looks like a correct API response. Secondly, Postman displays the status 200 OK — which means our request is successful. Why 200 and what’s the status?
API Status Codes And Error Messages
Most of the APIs you’ll ever interact with will be HTTP-based. The HTTP is a protocol which standardizes communication between various client applications and servers on the Internet.
One of the key elements of HTTP is status codes. By understanding the status code you (or actually systems you implement) can immediately tell what’s happened to your request. Chances are you faced one of the most popular status codes when you typed the wrong link — 404
But there are many more and end-users usually don’t see them. They range from 100+ to 500+. In general, the numbers follow the following rules:
200+ means the request has succeeded;
300+ means the request is redirected to another URL;
400+ means an error that originates from the client application has occurred;
500+ means an error that originates from the server has occurred.
If you could go through the steps once again, you would see that Voucherify replied with 401 Unauthorized when we didn’t provide API keys. Or 400 Bad Request when there was no payload which is required for Create Voucher request. Finally, we received 200 as a token of a successful API call.
If you’re curious about HTTP status codes meaning, there’s no better place than HTTP Cats (or this article maybe). 🙃
The growing amount of data and the need for speed in building products pushed APIs to become the lingua franca of digital teams. To design systems based on API-first systems, make sure you understand the vendors’ offerings. This hands-on testing guide is a good starting point in doing so. It will help you explore the API capabilities even before you throw it to your teaching team, saving their energy — and yours as well.
When enabled, IAP requires users accessing a web application to log in using their Google account and ensure they have the appropriate role to access the resource. This can be used to provide secure access to web applications without the need for a VPN. This is part of what Google now calls BeyondCorp, which is an enterprise security model designed to enable employees to work from untrusted networks without a VPN. At Real Kinetic, we frequently bump into companies practicing Death-Star security, which is basically relying on a hard outer shell to protect a soft, gooey interior. It’s simple and easy to administer, but it’s also vulnerable. That’s why we always approach security from a perspective of defense in depth.
Spring Boot provides the Spring Boot actuator module for monitoring and managing your application when it is moved into production. Some of the production-ready features it provides are health monitoring of the application, auditing of the events, and gathering of metrics from the production environments.
For enabling the Spring Boot actuator, we need to add the following Spring Boot starter Maven dependency in pom.xml.
Couchbase Search service supports the creation of special purpose indexes for Full Text Search to provide extensive capabilities for natural language querying on JSON documents. Couchbase Full Text Search indexes support an extensive range of query types, like:
Match, Match Phrase, Doc ID, and Prefix queries
Conjunction, Disjunction, and Boolean field queries
Numeric Range and Date Range queries
Geospatial queries
Query String queries, which employ a special syntax to express the details of each query
To perform a full text search, a Full Text Search Index has to be created first upon a bucket on which the search has to be targeted. The search could be performed on the textual and other contents of documents within a specified bucket.
Did you know that the new WordPress block editor aka Gutenberg allows you to save your custom content blocks and export them to use on your other WordPress sites.
This little-known feature is extremely useful and can you save you a lot of time specially if you’re building websites for clients.
In this article, we’ll show you how to easily export your WordPress Gutenberg blocks and import them to use on other sites.
What a lot of users don’t know is that you can actually export these re-usable blocks to use on your other sites, client websites, and technically you can even sell them if you want to.
Let’s take a look at how to export Gutenberg blocks to use on other sites.
Exporting Your WordPress Gutenberg Blocks to Use on Other Sites
WordPress’ reusable blocks are not just restricted for the website they’re created on. You can easily export them to use on any other WordPress site.
First, you’ll need to open the block management page. You can navigate to that page by clicking the Manage All Reusable Blocks link inside the Reusable tab in your content editor.
Once you’re on the block management page, you can edit, delete, export, and import your WordPress Gutenberg blocks.
Step 1. Export Your Gutenberg Block
To export your Gutenberg block, you simply need to click the Export as JSON option below the block.
Next, your block will be downloaded to your computer as a JSON file. Now, you can upload this JSON to any other WordPress site and use the block.
Step 2. Import Your Gutenberg Block
You need to log into the other WordPress site and go to its block management screen. You’ll see an Import from JSON button at the top.
Go ahead and click on that button to import.
Next, you’ll see a file upload box. You need to click on the Choose File button and select the block JSON file you downloaded earlier.
After it’s uploaded, you’ll see an Import option. Simply click on that to proceed.
WordPress will now import your new reusable block and save it in the database. Once done, you can use it on your new WordPress site like you would any other block.
We hope this article helped you learn how to export your WordPress Gutenberg blocks to use on other sites. You may also want to see our list of the must have WordPress plugins for all websites.
If you liked this article, then please subscribe to our YouTube Channel for WordPress video tutorials. You can also find us on Twitter and Facebook.
I think many WordPress users probably underestimate the amount of data that is made available via the REST API. Just about everything is available to anyone or anything that asks for it: posts, pages, categories, tags, comments, taxonomies, media, users, settings, and more. For most of these types of data, public access is useful. For example, if you have a JSON-powered news reader, it can basically replicate your entire site structure virtually anywhere. But that easy access invites potential abuse. Just like with RSS feeds, RESTfully delivered JSON content is easily scraped and used for spam, phishing, plagiarism, adsense, and other foul things.
User Data = Public Domain?
Beyond content theft, plagiarism, and such, the REST API opens the door to another potential security slash privacy concern over user data. By default every WordPress site delivers a significant amount of user data to anyone or anything that asks for it. For any user (of any role) that is the author of at least one post, their personal information is openly available to literally everyone.
So exactly which user data are exposed via the REST API? As explained in the documentation, the /users endpoint delivers basically everything except for user email addresses and passwords. Everything else — ID, Name, Website, Description, URL, Metadata and more — all public domain thanks to REST API.
To give you a more concrete example of the data that is shared publicly via the REST API, consider the following URL:
https://digwp.com/wp-json/wp/v2/users/3
Here we are invoking the REST API by calling a specific user endpoint (i.e., user ID = 3). Requesting that URL in a browser, the following data are returned:
{
"id": 3,
"name": "Jeff Starr",
"url": "https:\/\/perishablepress.com",
"description": "Jeff Starr is a professional web developer and book author with over 15 years of experience...",
"link": "https:\/\/digwp.com\/author\/jeffstarr\/",
"slug": "jeffstarr",
"avatar_urls": {
"24":"https:\/\/secure.gravatar.com\/avatar\/...",
"48":"https:\/\/secure.gravatar.com\/avatar\/...",
"96":"https:\/\/secure.gravatar.com\/avatar\/..."
},
"meta": [],
"_links": {
"self": [{"href":"https:\/\/digwp.com\/wp-json\/wp\/v2\/users\/3"}],
"collection": [{"href":"https:\/\/digwp.com\/wp-json\/wp\/v2\/users"}]
}
},
This same information also is available at other endpoints, for example:
https://digwp.com/wp-json/wp/v2/users
There you will find the same amount of information provided for every qualified user. Note that you can try this on your own WordPress-powered site. Simply replace digwp.com with your own domain name, and remember to include the subdirectory path if WordPress is installed in a subdirectory.
What's the Risk?
So WP REST API and security. For everything except the user data, the main risks basically are the same as for RSS feeds. Scrapers and content thieves are savvy enough to steal your content regardless of format. If you make it easy for people to steal your content, they will. So whether they're grabbing the data via RSS or JSON format, content is content, and the REST API makes it easier than ever for anyone and anything to manipulate your site's content, categories, tags, meta, and much more. Is that acceptable? Totally your call.
Now for user data, we enter a whole new level of risk. With user data, the information is personal, so there is a potential privacy risk. Even worse, for every user, their "Name" by default is their "Display Name", which defaults to the registered Username unless otherwise specified. This means that your site's registered usernames are publicly available, so there is a potential security risk.
Privacy Risk
For the privacy risk, perhaps it is a non-issue for most WordPress sites. But for the percentage of sites that must abide by an official privacy policy or other company rules and regulations (GDPR, anyone?), publicly sharing information about every qualified user is gonna be a problem. Or maybe your site needs to keep all author information private for legal or political reasons (like at a news reporting or government site). In many such cases REST's default functionality may present serious privacy risk. As someone said somewhere on social media1:
A lot of institutions use WordPress for their staff or students or even patients/clients. They probably have no idea this is exposed and they also probably have some level of security policy that doesn't allow names to be listed publicly. I think it's a problem and should be opt-in.
Security Risk
For the security risk, the significance and extent of the issue is up for debate1,2,3. In general, bad actors require at least two things to gain access to your site4:
Username
Password
And thanks to the WP REST API, they now have half of what they need. So the REST API introduces a security vulnerability by making it easier for attackers to brute-force their way into your site5,6. Instead of having to guess the correct username AND password, now they just have to guess the password. Which unfortunately for many user accounts is just too ridiculously easy to do.
Another on-topic post from social media1:
Its one-half of the puzzle in acquiring unauthorized credentials. If you're trying to follow best practices, you don't expose sensitive data. If you've worked to remove all leakage of user names from your site, this just re-exposed all that data.
How to Secure the REST API
So at this point, you should have a pretty good understanding of how the WordPress REST API works and why it can be considered a privacy and/or security risk for probably a vast percentage of WordPress sites. Now you get to decide whether or not it is necessary to take action and secure your site against unsafe data exposure. Fortunately, there are a couple of easy ways to lock it down using a WordPress plugin. Here are a couple of free options:
Disable REST API — Disable REST completely for all non-logged users
Full disclosure, the first option listed here, Disable WP REST API, is one of my own plugins. It is designed to be super lightweight and effective. That in mind, either of these plugins is gonna do the job to protect against unwanted REST exposure. If you know of other/better techniques, share ’em in the comments.
WordPress Team On Point
The WordPress team is aware of this potential privacy/security risk and already has taken steps to lock it down. For example, before the WP 4.7.1 update, the REST API exposed sensitive data for ALL registered users, regardless of whether or not they are credited as Author for any post(s).
So thanks to improvements made in version 4.7.1, WordPress now displays user data ONLY for users (of any role) who are credited as author for registered post types. This important step helps to reduce user data exposure, and tells us that the WP team is actively working to keep WordPress as safe and secure as possible. Hopefully they will take further steps to eliminate unnecessary exposure of sensitive user information.
Closing Thoughts
As simple as it is to properly address the fundamental vulnerabilities inherent in the WP REST API, unfortunately most WordPress users will remain blissfully unaware and do nothing. This is why the REST API should disable the public view of most if not all user data.
Sensitive information should be exposed only to authenticated users. Disabling exposure of user data by default helps to protect the vast majority of WordPress users, and of course developers always will be savvy enough to enable the user data endpoints if/when needed. It's a win win! :)
Footnotes
Here are some related materials and resources FYI: