Hello guys, recently i've update my website to php7.0, I'm runing some low minify CSS and JS. I encounter some css problems in Firefox & Internet Explorer with the all UI.
Any idea what causes this problem and how can be solve it please? With Chrome broswer works perfectly. Cheers, really appreciate ur help.
Surveys offer a wealth of extremely valuable information. For the web developing world, this can have huge implications. Have you ever wondered where the people in your field are working, what tools they’re using, and how long they’ve been in the business? What’s your competition and where should you be devoting your time?
Thanks to numerous web developer surveys, all of these questions can be answered. Let’s see what insight can be gleaned from these thousands of responses.
JavaScript has a huge range of libraries, and it can get overwhelming. Over 20k JS developers helped shine some light on the situation.
If you’re searching for a small, but potentially profitable niche to break into, Reason, ClojureScript, and Elm look like the best candidates for JavaScript flavors. Vue is also a steadily growing front-end framework worth looking at. There’s much more data for back-end frameworks, data layers, testing frameworks and more.
This survey hasn’t yet been released, but with 10k respondents, it’s sure to be enlightening. Keep an eye out or enter your email so you can know where this constantly-evolving language is going.
Stack Overflow is a gigantic hub of developer knowledge, so it’s the best place to run a long survey.
Almost 60% of developers are back-end, and near 50% full stack. 20% work in mobile, which explains the steadily growing market. Python has surpassed C# in popularity, so if you’re thinking of trying it, get on the bandwagon now.
Engineering managers, DevOps specialists, and data scientists/analysts have the highest salaries among developers – mobile and game devs the lowest.
5k front-end developers answered this toolkit survey, which was compared to one done in 2016.
A decent portion of CSS developers prefer using no pre-processor or framework at all, but popular tools include Sass, Bootstrap and Autoprefixer. Overall, CSS users seem to be moving towards cleaner code with usage and knowledge of methodologies, linting, and naming schemes increasing.
CSS and JavaScript experience often go together, especially with jQuery and React. If you’re a beginner, plan to learn both.
This 71k respondent survey is all about skills, and it’s really interesting. JavaScript surpassed Java with 73% knowing JS. React is growing fast, and by 2020 it might just dominate Angular. More employers want React too, so now’s the time to learn.
Internet of Things and Deep Learning are considered realistic technologies to pursue. And beginners, note that nearly 10% of developers have wiped a database or shut down a production server, so take this as a warning to double-check your code.
Where’s the developer ecosystem going? The data says everyone wants to learn Go, Python, and Kotlin, while JavaScript, Java, and HTML/CSS are already well-known.
In the absence of local or private database hosting, Amazon Web Services is the most popular candidate. And open source devs remain a minority, though it’s steadily gaining traction.
Node.js is very popular, and this user survey garnered nearly 2k responses. Back-end and full stack developers are the ones who use it, and they use it frequently in over half of development. These projects tend to be web apps.
A vast majority of Node developers also use databases, front-end libraries, and Node frameworks, with Express being the most popular. Over half use load balancing and containers.
One more interesting fact: Node users tend to know over three languages. Python is by far the top contender.
Ionic Framework’s huge community shared its insights in this 10k survey. Angular is the most popular framework among Ionic users, but React and Vue compatibility is in the works.
Consumer-focused apps made up the majority of projects, and 32% of Ionic devs work on a startup team. Nearly 30% are self-employed with the other big chunk working in a small company of 1-10.
Progressive Web Apps were the favored project, with 61% saying they had built one or plan to this year. They’re easy to manage, efficiently cross-platform, and get more user engagement.
Powerful Information
It’s a good idea to follow the changing online world, and what your fellow developers are up to. Knowing what the popular frameworks and libraries are can get you an edge on the competition. We hope this collection of surveys offered some insight into the modern development trends, and maybe gave you some direction towards what to pursue next!
Over the past decade, the world has seen the emergence of powerful JavaScript-based web apps while new frameworks evolved. These frameworks challenged issues that had long been associated with crippling website performance. Interactive UI elements, seamless speed, and impressive styling components have started co-existing within a website without compromising the speed too heavily. CSS and HTML are now injected into JS instead of the other way around because JS is simply more efficient. While the use of these JavaScript frameworks has boosted performance, it has taken a toll on testers.
Testing and debugging has become more and more complex. Puppeteer has been introduced as a node library used to enable Chrome browser testing.
CSS Houdini may be the most exciting development in CSS. Houdini is comprised of a number of separate APIs, each shipping to browsers separately, and some that have already shipped (here's the browser support). The Paint API is one of them. I’m very excited about it and recently started to think about how I can use it in my work.
One way I’ve been able to do that is to use it as a way to avoid reinventing the wheel. We’ll go over that in this post while comparing it with methods we currently use in JavaScript and CSS. (I won’t dig into how to write CSS Houdini because there are great articles like this, this and this.)
Houdini brings modularity and configurations to CSS
The way CSS Houdini works brings two advantages: modularity and configurability. Both are common ways to make our lives as developers easier. We see these concepts often in the JavaScript world, but less-so with CSS world… until now.
Here’s a table the workflows we have for some use cases, comparing traditional CSS with using Houdini. I also added JavaScript for further comparison. You can see CSS Houdini allows us to use CSS more productively, similar to how the JavaScript world had evolved into components.
Traditional CSS
CSS Houdini
JavaScript
When we need a commonly used snippets
Write it from scratch or copy-paste from somewhere.
Import a worklet for it.
Import a JS library.
Customize the snippet for the use case
Manually tweak the value in CSS.
Edit custom properties that the worklet exposes.
Edit configs that the library provides.
Sharing code
Share code for the raw styles, with comments on how to tweak each piece.
Share the worklet (in the future, to a package management service) and document custom properties.
Share the library to a package management service (like npm) and document how to use and configure it.
Modularity
With Houdini, you can import a worklet and start to use it with one line of code.
This means there’s no need to implement commonly used styles every time. You can have a collection of your own worklets which can be used on any of your projects, or even shared with each other.
If you're looking for modularity for HTML and JavaScript in additional to styles, then web components is the solution.
It’s very similar to what we already have in the JavaScript world. Most people won’t re-implement commonly used functions, like throttling or deep-copying objects. We simply import libraries, like Lodash.
I can imagine we could have CSS Houdini package management services if the popularity of CSS Houdini takes off, and anyone could import worklets for interesting waterfall layouts, background patterns, complex animation, etc.
Configurability
Houdini works well with CSS variables, which largely empowers itself. With CSS variables, a Houdini worklet can be configured by the user.
In the snippet, --direction and --size are CSS variables, and they’re used in the triangle worklet (defined by the author of the triangle worklet). The user can change the property to update how it displays, even dynamically updating CSS variables in JavaScript.
If we compare it to what we already have in JavaScript again, JavaScript libraries usually have options that can be passed along. For example, we can pass values for speed, direction, size and so on to a carousel library to make it perform the way we want. Offering these APIs at the element level in CSS is very useful.
A Houdini workflow makes my development process much more efficient
Let’s see a complete example of how this whole thing can work together to make development easier. We’ll use a tooltip design pattern as an example. I find myself using this pattern often in different websites, yet somehow re-implement for each new project.
Let’s briefly walk through my old experience:
OK, I need a tooltip.
It’s a box, with a triangle on one side. I’ll use a pseudo-element to draw the triangle.
I can use the transparent border trick to draw the triangle.
At this time, I most likely dig up my past projects to copy the code. Let me think… this one needs to point up, which side is transparent?
Oh, the design requires a border for the tooltip. I have to use another pseudo-element and fake a border for the pointing triangle.
What? They decide to change the direction of the triangle?! OK, OK. I will tweak all the values of both triangles...
It’s not rocket science. The whole process may only take five minutes. But let’s see how it can be better with Houdini.
I built a simple worklet to draw a tooltip, with many options to change its looks. You can download it on GitHub.
Here’s a demo! Go ahead and play around with variables!
CSS Houdini opens a door to modularized, configurable styles sharing. I look forward to seeing developers using and sharing CSS Houdini worklets. I’m trying to add more useful examples of Houdini usage. Ping me if you have ideas, or want to contribute to this repo.
This article is part of a series in which I attempt to use the web under various constraints, representing a given demographic of user. I hope to raise the profile of difficulties faced by real people, which are avoidable if we design and develop in a way that is sympathetic to their needs.
But as much as we developers hope for it to go away, it just. Won’t. Die. IE8 continues to show up in browser stats, especially outside of the bubble of the Western world.
Browser stats have to be taken with a pinch of salt, but current estimates for IE8 usage worldwide are around 0.3% to 0.4% of the desktop market share. The lower end of the estimate comes from w3counter:
From a peak of almost 30% at the end of 2010, W3Counter now believes IE8 accounts for 0.3% of global usage. (Large preview)
The higher estimate comes from StatCounter (the same data feed used by the “Can I use” usage table). It estimates global IE8 desktop browser proportion to be around 0.37%.
Worldwide usage of IE8 is at 0.37% according to StatCounter. (Large preview)
I suspected we might see higher IE8 usage in certain geographical regions, so drilled into the data by continent.
IE8 Usage By Region
Here is the per-continent IE8 desktop proportion (data from February 2018 — January 2019):
1.
Oceania
0.09%
2.
Europe
0.25%
3.
South America
0.30%
4.
North America
0.35%
5.
Africa
0.48%
6.
Asia
0.50%
Someone in Asia is five times more likely to be using IE8 than someone in Oceania.
I looked more closely into the Asian stats, noting the proportion of IE8 usage for each country. There’s a very clear top six countries for IE8 usage, after which the figures drop down to be comparable with the world average:
1.
Iran
3.99%
2.
China
1.99%
3.
North Korea
1.38%
4.
Turkmenistan
1.31%
5.
Afghanistan
1.27%
6.
Cambodia
1.05%
7.
Yemen
0.63%
8.
Taiwan
0.62%
9.
Pakistan
0.57%
10.
Bangladesh
0.54%
This data is summarized in the map below:
Iran, Turkmenistan and Afghanistan in the Middle East, and China, North Korea & Cambodia in the Far East stand out for their IE8 usage. (Large preview)
Incredibly, IE8 makes up around 4% of desktop users in Iran — forty times the proportion of IE8 users in Oceania.
Next, I looked at the country stats for Africa, as it had around the same overall IE8 usage as Asia. There was a clear winner (Eritrea), followed by a number of countries above or around the 1% usage mark:
1.
Eritrea
3.24%
2.
Botswana
1.37%
3.
Sudan & South Sudan
1.33%
4.
Niger
1.29%
5.
Mozambique
1.19%
6.
Mauritania
1.18%
7.
Guinea
1.12%
8.
Democratic Republic of the Congo
1.07%
9.
Zambia
0.94%
This is summarized in the map below:
Eritrea stands out for its IE8 usage (3.24%). A number of other countries also have >1% usage. (Large preview)
Whereas the countries in Asia that have higher-than-normal IE8 usage are roughly batched together geographically, there doesn’t appear to be a pattern in Africa. The only pattern I can see — unless it’s a coincidence — is that a number of the world’s largest IE8 using countries famously censor internet access, and therefore probably don’t encourage or allow updating to more secure browsers.
If your site is aimed at a purely Western audience, you’re unlikely to care much about IE8. If, however, you have a burgeoning Asian or African market — and particularly if you care about users in China, Iran or Eritrea — you might very well care about your website’s IE8 experience. Yes — even in 2019!
Who’s Still Using IE?
So, who are these people? Do they really walk among us?!
Whoever they are, you can bet they’re not using an old browser just to annoy you. Nobody deliberately chooses a worse browsing experience.
Someone might be using an old browser due to the following reasons:
Lack of awareness
They simply aren’t aware that they’re using outdated technology.
Lack of education
They don’t know the upgrade options and alternative browsers open to them.
Lack of planning
Dismissing upgrade prompts because they’re busy, but not having the foresight to upgrade during quieter periods.
Aversion to change
The last time they upgraded their software, they had to learn a new UI. “If it ain’t broke, don’t fix it.”
Aversion to risk
The last time they upgraded, their machine slowed to a crawl, or they lost their favorite feature.
Software limitation
Their OS is too old to let them upgrade, or their admin privileges may be locked down.
Hardware limitation
Newer browsers are generally more demanding of your hard disk space, memory and CPU.
I booted up my IE8 VM, clicked on the Internet Explorer program in anticipation, and this is what I saw:
The first thing I saw was a 404. Great. (Large preview)
Hmm, okay. Looks like the default web page pulled up by IE8 no longer exists. Well, that figures. Microsoft has officially stopped supporting IE8 so why should it make sure the IE8 landing page still works?
I decided to switch to the most widely used site in the world.
Google
The Google homepage renders fine in IE8. (Large preview)
It’s a simple site, therefore difficult to get wrong — but to be fair, it’s looking great! I tried searching for something:
Those who have read my previous articles may notice a recurring theme here. (Large preview)
For reference, here is how the search results look in a modern browser with JavaScript enabled:
Cleaner layout, extra images and meta information, Netflix/Twitter integration. (Large preview)
So, it looks like IE8 gets the no-JS version of Google search. I don’t think this was necessarily a deliberate design decision — it could just be that the JavaScript errored out:
The page tried and failed to run JavaScript. (Large preview)
Still, the end result is fine by me — I got my search results, which is all I wanted.
I clicked through to watch a YouTube video.
YouTube
Funky logo, no images for related videos, and unsurprisingly, no video. (Large preview)
There’s quite a lot broken about this page. All to do with little quirks in IE.
The logo, for instance, is zoomed in and cropped. This is down to IE8 not supporting SVG, and what we’re actually seeing is the fallback option provided by YouTube. They’ve applied a background-image CSS property so that in the event of no SVG support, you’ll get an attempt at displaying the logo. Only they seem to have not set the background-size properly, so it’s a little too far zoomed in.
YouTube set a background-img on the logo span, which pulls in a sprite. (Large preview)
For reference, here is the same page in Chrome (see how Chrome renders an SVG instead):
And what about that Autoplay toggle? It’s rendered like a weird looking checkbox:
Looks like IE8 defaults to a checkbox under the hood. (Large preview)
This appears to be down to use of a custom element (a paper-toggle-button, which is a Material Design element), which IE doesn’t understand:
paper-toggle-button is a custom element. (The screenshot is from Chrome DevTools, alongside how the Autoplay toggle SHOULD render.) (Large preview)
I’m not surprised this hasn’t rendered properly; IE8 doesn’t even cope with the basic semantic markup we use these days. Try using an <aside> or <main> and it will basically render them as divs, but ignoring any styling you apply to them.
To enable HTML5 markup, you have to explicitly tell the browser these elements exist. They can then be styled as normal:
That is wrapped in an IE conditional, by the way. <!--[if lt IE 9]> is a HTML comment to most browsers — and therefore gets skipped — but in IE it is a conditional which only passes “if less than IE 9”, where it executes/renders the DOM nodes within it.
So, the video page was a fail. Visiting YouTube.com directly didn’t fare much better:
At least I had a visible error message this time! (Large preview)
Undeterred, I ignored the warning and tried searching for a video within YouTube’s search bar.
IE8 traffic is clearly suspicious enough that YouTube didn’t trust that I’m a real user, and decided not to process my search request!
Signing Up To Gmail
If I’m going to spend the day on IE8, I’m going to need an email address. So I go about trying to set up a new one.
First of all, I tried Gmail.
The text isn’t going to pass color contrast standards! (Large preview)
There’s something a bit off about the image and text here. I think it’s down to the fact that IE8 doesn’t support media queries — so it’s trying to show me a mobile image on desktop.
One way you can get around this is to use Sass to generate two stylesheets; one for modern browsers, and one for legacy IE. You can get IE-friendly, mobile-first CSS (see tutorial by Jake Archibald) by using a mixin for your media queries. The mixin “flattens” your legacy IE CSS to treat IE as though it’s always a specific predefined width (e.g. 65em), giving only the relevant CSS for that width. In this case, I’d have seen the correct background-image for my assumed screen size and had a better experience.
Anyway, it didn’t stop me clicking ‘Create an Account’. There were a few differences between how it looked in IE8 and a modern browser:
IE8 is missing the tight layout, and there’s an overlap of text, but otherwise still works. (Large preview)
Whilst promising at first sight, the form was quite buggy to fill in. The ‘label’ doesn’t get out of the way when you start filling in the fields, so your input text is obfuscated:
The labels overlapped the text I was writing. (Large preview)
The markup for this label is actually a <div>, and some clever JS moves the text out of the way when the input is focussed. The JS doesn’t succeed on IE8, so the text stays stubbornly in place.
The ‘label’ is a div which is overlaid on form input using CSS. (Large preview)
After filling in all my details, I hit “Next”, and waited. Nothing happened.
Then I noticed the little yellow warning symbol at the bottom left of my IE window. I clicked it and saw that it was complaining about a JS error:
I got reasonably far, but then the Next button didn’t work. (Large preview)
I gave up on Gmail and turned to MSN.
Signing Up To Hotmail
I was beginning to worry that email might be off-limits for a ten-year-old browser. But when I went to Hotmail, the signup form looked OK — so far so good:
The signup page looked fine. Guessed we’d have more luck with a Microsoft product! (Large preview)
Then I noticed a CAPTCHA. I thought, “There’s no way I’ll get through this…”
I could see and complete the CAPTCHA. (Large preview)
To my surprise, the CAPTCHA worked!
The only quirky thing on the form was some slightly buggy label positioning, but the signup was otherwise seamless:
The label positions were a bit off, but I guessed my last name followed by my surname would be fine. (Large preview)
Does that screenshot look OK to you? Can you spot the deliberate mistake?
The leftmost input should have been my first name, not my surname. When I came back and checked this page later, I clicked on the “First name” label and it applied focus to the leftmost input, which is how I could have checked I was filling in the correct box in the first place. This shows the importance of accessible markup — even without CSS and visual association, I could determine exactly which input box applied to which label (albeit the second time around!).
Anyhow, I was able to complete the sign-up process and was redirected to the MSN homepage, which rendered great.
If any site is going to work in IE8, it will be the Microsoft homepage. (Large preview)
I could even read articles and forget that I was using IE8:
The article works fine. No dodgy sidebars or borked images. (Large preview)
With my email registered, I was ready to go and check out the rest of the Internet!
Facebook
I visited the Facebook site and was immediately redirected to the mobile site:
“You are using a browser that is not supported by Facebook, so we have redirected you to a simpler version to give you the best experience.” (Large preview)
This is a clever fallback tactic, as Facebook need to support a large global audience on low-end mobile devices, so need to provide a basic version of Facebook anyway. Why not offer that same baseline of experience to older desktop browsers?
I tried signing up and was able to make an account. Great! But when I logged into that account, I was treated with suspicion — just like when I searched for things on YouTube — and was faced with a CAPTCHA.
Only this time, it wasn’t so easy.
“Please enter the code below”. Yeah, right. (Large preview)
I tried requesting new codes and refreshing the page several times, but the CAPTCHA image never loaded, so I was effectively locked out of my account.
Oh well. Let’s try some more social media.
Twitter
I visited the Twitter site and had exactly the same mobile redirect experience.
Twitter treats IE8 as a mobile browser, like Facebook does. (Large preview)
But I couldn’t even get as far as registering an account this time:
Your browser is no longer supported. To sign up, please update it. You can still log in to your existing user accounts. (Large preview)
Oddly, Twitter is happy for you to log in, but not for you to register in the first place. I’m not sure why — perhaps it has a similar CAPTCHA scenario on its sign-up pages which won’t work on older browsers. Either way, I’m not going to be able to make a new account.
I felt awkward about logging in with my existing Twitter account. Call me paranoid, but vulnerabilities like the CFR Watering Hole Attack of 2013 — where the mere act of visiting a specific URL in IE8 would install malware to your machine — had me nervous that I might compromise my account.
But, in the interests of education, I persevered (with a temporary new password):
Successfully logged in. I can see tweets! (Large preview)
I could also tweet, albeit using the very basic <textarea>:
You only miss them when they’re gone. (Large preview)
In conclusion, Twitter is basically fine in IE8 — as long as you have an account already!
I’m done with social media for the day. Let’s go check out some news.
BBC News
The BBC appears to be loading a mixture of HTTPS and HTTP assets. (Large preview)
The news homepage looks very basic and clunky but basically works — albeit with mixed content security warnings.
Take a look at the logo. As we’ve already seen on YouTube, IE8 doesn’t support SVG, so we require a PNG fallback.
The BBC uses the <image> fallback technique to render a PNG on IE:
IE8 finds the base64 image inside the SVG and renders it. (Large preview)
…and to ignore the PNG when SVG is available:
The image part is ignored and the svg is rendered nicely. (Large preview)
This technique exploits the fact that older browsers used to obey both <image> and <img> tags, and so will ignore the unknown <svg> tag and render the fallback, whereas modern browsers ignore rendering <image> when inside an SVG. Chris Coyier explains the technique in more detail.
I tried viewing an article:
This site is optimised for modern browsers, and does not fully support your browser. (Large preview)
It’s readable. I can see the headline, the navigation, the featured image. But the rest of the article images are missing:
This is to be expected, and is due to the BBC lazy-loading images. IE8 not being a ‘supported browser’ means it does not get the JavaScript that enables lazy-loading, thus the images never load at all.
Out of interest, I thought I’d see what happens if I try to access the BBC iPlayer:
And that got me wondering about another streaming service.
Netflix
I was half expecting an empty white page when I loaded up Netflix in IE8. I was pleasantly surprised when I actually saw a decent landing page:
“Join free for a month” call to action, over a composite image of popular titles. (Large preview)
I compared this with the modern Chrome version:
“Watch free for 30 days” call to action, over a composite image of popular titles. (Large preview)
There’s a slightly different call to action (button text) — probably down to multivariate testing rather than what browser I’m on.
What’s different about the render is the centralized text and the semi-transparent black overlay.
The lack of centralized text is because of Netflix’s use of Flexbox for aligning items:
Netflix uses the Flexbox property justify-content: center to align its text. (Large preview)
A text-align: center on this class would probably fix the centering for IE8 (and indeed all old browsers). For maximum browser support, you can follow a CSS fallbacks approach with old ‘safe’ CSS, and then tighten up layouts with more modern CSS for browsers that support it.
The lack of background is due to use of rgba(), which is not supported in IE8 and below.
A background of rgba(0,0,0,.5) is meaningless to older browsers. (Large preview)
Traditionally it’s good to provide CSS fallbacks like so, which show a black background for old browsers but show semi-transparent background for modern browsers:
This is a very IE specific fix, however, basically every other browser supports rgba. Moreover, in this case, you’d lose the fancy Netflix tiles altogether, so it would be better to have no background filter at all! The surefire way of ensuring cross-browser support would be to bake the filter into the background image itself. Simple but effective.
Anyway, so far, so good — IE8 actually rendered the homepage pretty well! Am I actually going to be watching Breaking Bad on IE8 today?
My already tentative optimism was immediately shot down when I viewed the sign-in page:
Can you guess which side is IE8 and which is Chrome? (Large preview)
Still, I was able to sign in, and saw a pared-back dashboard (no fancy auto-expanding trailers):
Each programme had a simple hover state with play icon and title. (Large preview)
I clicked on a programme with vague anticipation, but of course, only saw a black screen.
Amazon
Ok, social media and video are out. All that’s left is to go shopping.
I checked out Amazon, and was blown away — it’s almost indistinguishable from the experience you’d get inside a modern browser:
The Amazon homepage looks almost as good on IE8 as it does on any other browser. (Large preview)
I’ve been drawn in by a good homepage before. So let’s click on a product page and see if this is just a fluke.
The product page also looks fantastic (and makes me hungry). (Large preview)
No! The product page looked good too!
Amazon wasn’t the only site that surprised me in its backwards compatibility. Wikipedia looked great, as did the Gov.UK government website. It’s not easy to have a site that doesn’t look like an utter car crash in IE8. Most of my experiences were decidedly less polished…!
It is difficult to read or navigate sky.com on IE8. (Large preview)
But a deprecated warning notice or funky layout wasn’t the worst thing I saw today.
Utterly Broken Sites
Some sites were so broken that I couldn’t even connect to them!
I wondered if it might be a temporary VM network issue, but it happened every time I refreshed the page, even when coming back to the same site later in the day.
This happened on a few different sites throughout the day, and I eventually concluded that this never affected sites on HTTP — only on HTTPS (but not all HTTPS sites). So, what was the problem?
Using Wireshark to analyze the network traffic, I tried connecting to GitHub again. We can see that the connection failed to establish because of a fatal error, “Description: Protocol Version.”
Default advanced settings for IE8: TLS 1.0 is checked, TLS 1.1 and 1.2 are unchecked. (Large preview)
I checked the boxes for TLS 1.1 and TLS 1.2, reloaded the page and — voilà! — I was able to view GitHub!
It doesn’t look pretty, but at least I can now see it! (Large preview)
Many thanks to my extremely talented friend Aidan Fewster for helping me debug that issue.
I’m all for backwards compatibility, but this presents an interesting dilemma. According to the PCI Security Standards Council, TLS 1.0 is insecure and should no longer be used. But by forcing TLS 1.1 or higher, some users will invariably be locked out (and not all are likely to be tech-savvy enough to enable TLS 1.2 in their advanced settings).
By allowing older, insecure standards and enabling users to continue to connect to our sites, we’re not helping them — we’re hurting them, by not giving them a reason to move to safer technologies. So how far should you go in supporting older browsers?
But “supporting older browsers” is very different to “hacking it for IE”. I don’t advocate the latter, but we should pragmatically try to do the former. The mantra I try to live by as a web developer is this:
“Optimize for the majority, make an effort for the minority, and never sacrifice security.”
I’m going to move away from the world of IE8 now and talk about general, sustainable solutions for legacy browser support.
There are two broad strategies for supporting older browsers, both beginning with P:
Polyfilling
Strive for feature parity for all by filling in the missing browser functionality.
Progressive Enhancement
Start from a core experience, then use feature detection to layer on functionality.
These strategies are not mutually exclusive from one another; they can be used in tandem. There are a number of implementation decisions to make in either approach, each with their own nuances, which I’ll cover in more detail below.
Polyfilling
For some websites or web pages, JavaScript is very important for functionality and you simply want to deliver working JavaScript to as many browsers as possible.
There are a number of ways to do this, but first, a history lesson.
A Brief History Of ECMAScript
ECMAScript is a standard, and JavaScript is an implementation of that standard. That means that ES5 is “ECMAScript version 5”, and ES6 is “ECMAScript version 6”. Confusingly, ES2015 is the same as ES6.
ES6 was the popularized name of that version prior to its release, but ES2015 is the official name, and subsequent ECMAScript versions are all associated with their release year.
At time of writing, the latest standard is ES2018 (ES9). Most modern browsers support at least ES2015. Almost every browser supports ES5.
Technically IE8 isn’t ES5. It isn’t even ES4 (which doesn’t exist — the project was abandoned). IE8 uses the Microsoft implementation of ECMAScript 3, called JScript. IE8 does have some ES5 support but was released a few months before ES5 standards were published, and so has a mismatch of support.
Transpiling vs Polyfilling
You can write ES5 JavaScript and it will run in almost every ancient browser:
var foo = function () {
return 'this is ES5!';
};
You can also continue to write all of your JavaScript like that — to enable backwards compatibility forever. But you’d be missing out on new features and syntactic sugar that has become available in the evolving versions of JavaScript, allowing you to write things like:
const foo = () => {
return 'this is ES6!';
};
Try running that JavaScript in an older browser and it will error. We need to transpile the code into an earlier version of JavaScript that the browser will understand (i.e. convert our ES6 code into ES5, using automated tooling).
Now let’s say our code uses a standard ES5 method, such as Array.indexOf. Most browsers have a native implementation of this and will work fine, but IE8 will break. Remember IE8 was released a few months before ES5 standards were published, and so has a mismatch of support? One example of that is the indexOf function, which has been implemented for String but not for Array.
If we try to run the Array.indexOf method in IE8, it will fail. But if we’re already writing in ES5, what else can we do?
We can polyfill the behavior of the missing method. Developers traditionally polyfill each feature that they need by copying and pasting code, or by pulling in external third-party polyfill libraries. Many JavaScript features have good polyfill implementations on their respective Mozilla MDN page, but it’s worth pointing out that there are multiple ways you can polyfill the same feature.
For example, to ensure you can use the Array.indexOf method in IE8, you would copy and paste a polyfill like this:
if (!Array.prototype.indexOf) {
Array.prototype.indexOf = (function (Object, max, min) {
// big chunk of code that replicates the behaviour in JavaScript goes here!
// for full implementation, visit:
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/indexof#Polyfill
})(Object, Math.max, Math.min);
}
So long as you call the polyfill before you pull in any of your own JS, and provided you don’t use any ES5 JavaScript feature other than Array.indexOf, your page would work in IE8.
Polyfills vary in size and effectiveness and sometimes have dependencies on external libraries such as jQuery.
You may also hear of “shims” rather than “polyfills”. Don’t get too hung up on the naming — people use the two terms interchangeably. But technically speaking, a shim is code that intercepts an API call and provides a layer of abstraction. A polyfill is a type of shim, in the browser. It specifically uses JavaScript to retrofit new HTML/CSS/JS features in older browsers.
Summary of the “manually importing polyfills” strategy:
✅ Complete control over choice of polyfills;
✅ Suitable for basic websites;
⚠️ Without additional tooling, you’re forced to write in native ES5 JavaScript;
⚠️ Difficult to micromanage all of your polyfills;
⚠️ Out of the box, all your users will get the polyfills, whether they need them or not.
Babel Polyfill
I’ve talked about transpiling ES6 code down to ES5. You do this using a transpiler, the most popular of which is Babel.
Babel is configurable via a .babelrc file in the root of your project. In it, you point to various Babel plugins and presets. There’s typically one for each syntax transform and browser polyfill you’ll need.
Micromanaging these and keeping them in sync with your browser support list can be a pain, so the standard setup nowadays is to delegate that micromanagement to the @babel/preset-env module. With this setup, you simply give Babel a list of browser versions you want to support, and it does the hard work for you:
The useBuiltIns configuration option of @babel/preset-env is where the magic happens, in combination with an import "@babel/polyfill" (another module) in the entry point of your application.
When omitted, useBuiltIns does nothing. The entirety of @babel/polyfill is included with your app, which is pretty heavy.
When set to "entry", it converts the @babel/polyfill import into multiple, smaller imports, importing the minimum polyfills required to polyfill the targeted browsers you’ve listed in your .babelrc (in this example, Chrome 58 and IE 11).
Using Babel, you can transpile and polyfill your JavaScript prior to deploying to production, and target support in a specific minimum baseline of browsers. NB, another popular tool is TypeScript, which has its own transpiler that transpiles to ES3, in theory supporting IE8 out of the box.
Summary of using @babel/preset-env for polyfilling:
✅ Delegate micromanagement of polyfills to a tool;
✅ Automated tool helps prevent inclusion of polyfills you don’t need;
✅ Scales to larger, complex sites;
⚠️ Out of the box, all your users will get the polyfills, whether they need them or not;
⚠️ Difficult to keep sight of exactly what’s being pulled into your application bundle.
Lazy Loading Polyfills With Webpack And Dynamic Imports
It is possible to leverage the new import() proposal to feature-detect and dynamically download polyfills prior to initializing your application. It looks something like this in practice:
✅ Doesn’t bloat modern browsers with unnecessary polyfills;
⚠️ Requires manually managing each polyfill.
polyfill.io
polyfill.io is polyfilling as a service, built by the Financial Times. It works by your page making a single script request to polyfill.io, optionally listing the specific features you need to polyfill. Their server then analyzes the user agent string and populates the script accordingly. This saves you from having to manually provide your own polyfill solutions.
Here is the JavaScript that polyfill.io returns for a request made from IE8:
Lots of JS code to polyfill standard ES5 methods in IE8. (Large preview)
Here’s the same polyfill.io request, but where the request came from modern Chrome:
All that’s required from your site is a single script call.
Summary:
✅ Ease of inclusion into your web app;
✅ Delegates responsibility of polyfill knowledge to a third party;
⚠️ On the flipside, you’re now reliant on a third-party service;
⚠️ Makes a blocking <script> call, even for modern browsers that don’t need any polyfills.
Progressive Enhancement
Polyfilling is an incredibly useful technique for supporting older browsers, but can be a bloat to web pages and is limited in scope.
The progressive enhancement technique, on the other hand, is a great way of guaranteeing a basic experience for all browsers, whilst retaining full functionality for your users on modern browsers. It should be achievable on most sites.
The principle is this: start from a baseline of HTML (and styling, optional), and “progressively enhance” the page with JavaScript functionality. The benefit is that if the browser is a legacy one, or if the JavaScript is broken at any point in its delivery, your site should still be functional.
The term “progressive enhancement” is often used interchangeably with “unobtrusive JavaScript“. They do mean essentially the same thing, but the latter takes it a little further in that you shouldn’t litter your HTML with lots of attributes, IDs and classes that are only used by your JavaScript.
Cut-The-Mustard
The BBC technique of “cutting the mustard” (CTM) is a tried and tested implementation of progressive enhancement. The principle is that you write a solid baseline experience of HTML, and before downloading any enhancing JavaScript, you check for a minimum level of support. The original implementation checked for the presence of standard HTML5 features:
if ('querySelector' in document
&& 'localStorage' in window
&& 'addEventListener' in window) {
// Enhance for HTML5 browsers
}
As new features come out and older browsers become increasingly antiquated, our cuts the mustard baseline will change. For instance, new JavaScript syntax such as ES6 arrow functions would mean this inline CTM check fails to even parse in legacy browsers — not even safely executing and failing the CTM check — so may have unexpected side-effects such as breaking other third-party JavaScript (e.g. Google Analytics).
To avoid even attempting to parse untranspiled, modern JS, we can apply this “modern take” on the CTM technique, taken from @snugug’s blog, in which we take advantage of the fact that older browsers don’t understand the type="module" declaration and will safely skip over it. In contrast, modern browsers will ignore <script nomodule> declarations.
<script type="module" src="./mustard.js"></script>
<script nomodule src="./no-mustard.js"></script>
<!-- Can be done inline too -->
<script type="module">
import mustard from './mustard.js';
</script>
<script nomodule type="text/javascript">
console.log('No Mustard!');
</script>
However, just as the world of JavaScript is evolving, so is the world of CSS. Now that we have Grid, Flexbox, CSS variables and the like (each with a varying efficacy of fallback), there’s no telling what combination of CSS support an old browser might have that might lead to a mishmash of “modern” and “legacy” styling, the result of which looks broken. Therefore, sites are increasingly choosing to CTM their styling, so now HTML is the core baseline, and both CSS and JS are treated as enhancements.
The JavaScript-based CTM techniques we’ve seen so far have a couple of downsides if you use the presence of JavaScript to apply CSS in any way:
Inline JavaScript is blocking. Browsers must download, parse and execute your JavaScript before you get any styling. Therefore, users may see a flash of unstyled text.
<head>
<!-- CSS-based cuts-the-mustard -->
<!-- IMPORTANT: the JS depends on having this rule somewhere in the CSS: `body { clear: both }` -->
<link rel="stylesheet" href="mq-test.css"
media="only screen and (min-resolution: 0.1dpcm),
only screen and (-webkit-min-device-pixel-ratio:0)
and (min-color-index:0)">
</head>
<body>
<!-- content here... -->
<script>
(function () { // wrap in an IIFE to prevent global scope pollution
function isSupported () {
var val = '';
if (window.getComputedStyle) {
val = window.getComputedStyle(document.body, null).getPropertyValue('clear');
} else if (document.body.currentStyle) {
val = document.body.currentStyle.clear;
}
if (val === 'both') { // references the `body { clear: both; }` in the CSS
return true;
}
return false;
}
if (isSupported()) {
// Load or run JavaScript for supported browsers here.
}
})();
</script>
</body>
This approach is quite brittle — accidentally overriding the clear property on your body selector would ‘break’ your site — but it does offer the best performance. This particular implementation uses media queries that are only supported in at least IE 9, iOS 7 and Android 4.4, which is quite a sensible modern baseline.
“Cuts the mustard”, in all its various guises, accomplishes two main principles:
Widespread user support;
Efficiently applied dev effort.
It’s simply not possible for sites to accommodate every single browser / operating system / network connection / user configuration combination. Techniques such as cuts-the-mustard help to rationalize browsers into C-grade and A-grade browsers, according to the Graded Browser Support model by Yahoo!.
Cuts-The-Mustard: An Anti-Pattern?
There is an argument that applying a global, binary decision of “core” vs “advanced” is not the best possible experience for our users. It provides sanity to an otherwise daunting technical problem, but what if a browser supports 90% of the features in your global CTM test, and this specific page doesn’t even make use of the 10% of the features it fails on? In this case, the user would get the core experience, since the CTM check would have failed. But we could have given them the full experience.
And what about cases where the given page does make use of a feature the browser doesn’t support? Well, in the move towards componentization, we could have a feature-specific fallback (or error boundary), rather than a page-level fallback.
We do this every day in our web development. Think of pulling in a web font; different browsers have different levels of font support. What do we do? We provide a few font file variations and let the browser decide which to download:
We have a similar fallback with HTML5 video. Modern browsers will choose which video format they want to use, whereas legacy browsers that don’t understand what a <video> element is will simply render the fallback text:
<video width="400" controls>
<source src="mov_bbb.mp4" type="video/mp4">
<source src="mov_bbb.ogg" type="video/ogg">
Your browser does not support HTML5 video.
</video>
The nesting approach we saw earlier used by the BBC for PNG fallbacks for SVG is the basis for the <picture> responsive image element. Modern browsers will render the best fitting image based on the media attribute supplied, whereas legacy browsers that don’t understand what a <picture> element is will render the <img> fallback.
The HTML spec has carefully evolved over the years to provide a basic fallback mechanism for all browsers, whilst allowing features and optimisations for the modern browsers that understand them.
We could apply a similar principle to our JavaScript code. Imagine a Feature like so, where the foo method contains some complex JS:
class Feature {
browserSupported() {
return ('querySelector' in document); // internal cuts-the-mustard goes here
}
foo() {
// etc
}
}
export default new Feature();
Before calling foo, we check if the Feature is supported in this browser by calling its browserSupported method. If it’s not supported, we don’t even attempt to call the code that would otherwise have errored our page.
import Feature from './feature';
if (Feature.browserSupported()) {
Feature.foo();
}
This technique means we can avoid pulling in polyfills and just go with what’s natively supported by each individual browser, gracefully degrading individual features if unsupported.
Note that in the example above, I’m assuming the code gets transpiled to ES5 so that the syntax is understood by all browsers, but I’m not assuming that any of the code is polyfilled. If we wanted to avoid transpiling the code, we could apply the same principle but using the type="module" take on cuts-the-mustard, but it comes with the caveat that it already has a minimum ES6 browser requirement, so is only likely to start being a good solution in a couple of years:
<script type="module">
import Feature from './feature.js';
if (Feature.browserSupported()) {
Feature.foo();
}
</script>
We’ve covered HTML, and we’ve covered JavaScript. We can apply localized fallbacks in CSS too; there’s a @supports keyword in CSS, which allows you to conditionally apply CSS based on the presence or absence of support for a CSS feature. However, it is ironically caveated with the fact that it is not universally supported. It just needs careful application; there’s a great Mozilla blog post on how to use feature queries in CSS.
In an ideal world, we shouldn’t need a global cuts-the-mustard check. Instead, each individual HTML, JS or CSS feature should be self-contained and have its own error boundaries. In a world of web components, shadow DOM and custom elements, I expect we’ll see more of a shift to this sort of approach. But it does make it much more difficult to predict and to test your site as a whole, and there may be unintended side-effects if, say, the styling of one component affects the layout of another.
Two Main Backwards Compatibility Strategies
A summary of polyfilling as a strategy:
✅ Can deliver client-side JS functionality to most users.
✅ Can be easier to code when delegating the problem of backwards-compatibility to a polyfill.
⚠️ Depending on implementation, could be detrimental to performance for users who don’t need polyfills.
⚠️ Depending on complexity of application and age of browser, may require lots of polyfills, and therefore run very poorly. We risk shipping megabytes of polyfills to the very browsers least prepared to accept it.
A summary of progressive enhancement as a strategy:
✅ Traditional CTM makes it easy to segment your code, and to manually test.
✅ Guaranteed baseline of experience for all users.
⚠️ Might unnecessarily deliver the core experience to users who could handle the advanced experience.
⚠️ Not well suited to sites that require client-side JS for functionality.
⚠️ Sometimes difficult to balance a robust progressive enhancement strategy with a performant first render. There’s a risk of over-prioritizing the ‘core’ experience to the detriment of the 90% of your users who get the ‘full’ experience (e.g. providing small images for noJS and then replacing with high-res images on lazy-load means we’ve wasted a lot of download capacity on assets that are never even viewed).
Conclusion
IE8 was once a cutting edge browser. (No, seriously.) The same could be said for Chrome and Firefox today.
If today’s websites are totally unusable in IE8, the websites in ten years time’ are likely to be about as unusable in today’s modern browsers — despite being built upon the open technologies of HTML, CSS, and JavaScript.
Stop and think about that for a moment. Isn’t it a bit scary? (That said, if you can’t abandon browsers after ten years and after the company who built it has deprecated it, when can you?)
IE8 is today’s scapegoat. Tomorrow it’ll be IE9, next year it’ll be Safari, a year later it might be Chrome. You can swap IE8 out for ‘old browser of choice’. The point is, there will always be some divide between what browsers developers build for, and what browsers people are using. We should stop scoffing at that and start investing in robust, inclusive engineering solutions. The side effects of these strategies tend to pay dividends in terms of accessibility, performance and network resilience, so there’s a bigger picture at play here.
We tend not to think about screen reader numbers. We simply take it for granted that it’s morally right to do our best to support users who have no other way of consuming our content, through no fault of our own. The same principle applies to people using older browsers.
We’ve covered some high-level strategies for building robust sites that should continue to work, to some degree, across a broad spectrum of legacy and modern browsers.
Once again, a disclaimer: don’t hack things for IE. That would be missing the point. But be mindful that all sorts of people use all sorts of browsers for all sorts of reasons, and that there are some solid engineering approaches we can take to make the web accessible for everyone.
Optimize for the majority, make an effort for the minority, and never sacrifice security.
I’ve been playing around a lot with the Shape Detection API in Chrome and I really like the potential it has. For example, a very simple QRCode detector I wrote a long time ago has a JS polyfill but uses new BarcodeDetector() API if it is available.
One of the biggest blunders a JS developer can do make while writing code is declaring unnecessary global variables. Global variables are extremely helpful for programmers, but if they are not used carefully, they can rob the speed and efficiency of any browser.
Short Note
There are mainly two types of variables that are used in JS: local and global. Local variables are defined and used within a function, whereas global variables are defined for the function window. In short, until the code doesn’t terminate, global variables will be present, lurking in the background.
I gave a quick talk on JS a while ago on hoisting in JS and while discussing how hoisting applies to variable declarations, we imminently reached ES6’s let and const. We thus began talking about the difference between var, let and const, and how const is not really a constant or immutable.
What Is const?
Constants are block-scoped, much like variables defined using the let statement. The value of a constant cannot change through reassignment, and it can’t be redeclared. - MDN
React is a JS library that is used to build user interfaces. It is mostly used in making single-page and mobile applications.
Webhook is a very friendly and helpful way to get notified when something happens. In a web application, when something happens or an event occurs a message is posted via URL. Sometimes, you only need data when something happens, otherwise, you don't require any data. In conventional ways, a web application keeps fetching data from the database rather than waiting for any event that overwhelms the server by compromising more resources. Webhooks gives relaxation to the server and notifies when some event happens.
The classic flip-style clock was a staple for years and it’s just one more thing the digital era made obsolete – although not quite forgotten.
We can find a bunch of cool clock designs in PSD form, but it’s more difficult to find working flip-style clocks in code. So I went on a mission to find some awesome examples online.
This gallery features 9 totally free flipping clock designs with a variety of styles and coding techniques.
Whether you want to build something like this for practice or add a working clock onto your page, these snippets are sure to help.
So here’s a really interesting project that features a flipping countdown running in pure JS.
There is a bit of CSS for styling but the entire animation setup and the structure all runs on JavaScript. Even the HTML gets embedded through JavaScript.
But there’s also a lot to learn from this pen if you study the code carefully. You’ll find some great snippets to reuse and this makes a nice base for experimenting in JavaScript.
There aren’t enough adjectives in the world to describe the awesomeness of this timer app.
It’s built around the Pomodoro Technique and it runs natively right in your web browser. You basically set the timer and click “start”. From there, a flipping clock animation counts down until your first break.
You can even alter the total break time and the total work session time.
Plus, the UI design is phenomenal and it’s cleverly designed to across the board.
So maybe you don’t like basic JavaScript for your projects. Maybe you’re more of a jQuery person who prefers working with plugins. No problem.
Have a look at this jQuery script featuring a very basic countdown clock. I noticed the animation styles are incredibly smooth and easy on the eyes regardless of web browser.
Each flipping effect almost looks like a native 3D transform because the items that flip really feel like they’re moving. It takes some effort to get that just right.
If you want a clean, smooth clock effect for your homepage or landing page then definitely keep this snippet in mind.
Okay, so this example doesn’t exactly fit the mold of a “flipping” clock.
But I do think that this pen looks awesome and it captures the spirit of a flipping clock animation.
Developer Harsha Bhat created this effect using Haml, Sass and some clean vanilla JavaScript.
It’s funny how all the free web frameworks in the world still can’t touch plain JavaScript.
I liken this effect to a minimalist design technique that can work with clean, simple websites. Try it out if you’re working on a project that would mesh nicely with this style.
Moving away from JavaScript, you might be looking for a pure CSS3 alternative. In that case be sure to save this pen since it’s the best one I could find.
CSS3 has a long way to go in the animation department and I don’t think it’ll ever catch up to JavaScript.
But you can produce some really nice effects with pure CSS code if you know what you’re doing.
I really like this snippet as a starting point for a flipping clock. The animation doesn’t feel as 3D as you’d expect, but it does give the same illusion of natural motion – which is crucial for this kind of feature.
Most of the flipping clock designs you’ll find online feature black squares with lighter text. But this design is different.
Developer Ed Hicks created this lighter flipping clock as an alternate design running on CSS and JS code. It’s actually a fairly complex project, but the JS is simplified since it runs on top of jQuery.
Anyone looking to add a lighter styled clock on their site will surely enjoy digging around in this code snippet.
One thing I like about this Vue-powered clock is that all the digits are combined into single squares.
On most clocks you’ll find that the seconds and minutes all have their own blocks for each digit.
This clock looks a whole lot smoother in my opinion. Not to mention that it’s a great practice piece to study if you’re just starting to learn Vue.js.
You’ll notice that this list has a ton of variety in coding styles and many don’t even use frameworks. If you’d like to see more of what’s out there, you can find many other examples if you spend some time digging around CodePen.
It began, as many things do, with a silly conversation. In this case, I was talking with our Front End Technology Competency Director (aka "boss man") Mundi Morgado.
It went something like this…
Mundi Morgado I want you to build a visual screen reader.
Nathan Smith Who what now?
Mundi Morgado I want a CSS library that allows you to see the structure of a document. It shouldn't use class so that you're forced to focus on semantics. Also, make it theme-able.
Nathan Smith Sure, let me see what I can come up with.
Fast-forward a week, and we've got what we are now calling:
Trashy.css: The throwaway CSS library with no class
Why throwaway? Well, it's not really meant to be a fully fledged, production-ready style framework. Rather, it's like training wheels for document semantics, with some bumper lanes (think: bowling) to keep you on the right track.
It's part of our ongoing effort at TandemSeven to promote code literacy throughout our organization. As more of our UX designers are beginning to share responsibility for the accessibility and semantics of a project, it makes sense that we would build in such a way that allows UX and development to be more collaborative.
There are four main aspects to Trashy.
Trashy: "Basic"
First is the base trashy.css file, which applies a passably basic look and feel to the majority of common HTML elements. Check out this example of a basic page.
Trashy: "Boxes"
Second, there is trashy.boxes.css. This visually distinguishes otherwise invisible semantic elements, such as: header, main, nav, etc. That way, one can see where those elements are (or aren't) as a page is being authored. Here’s a page with semantic boxes outlined.
Trashy: "Theme"
Thirdly, theming is possible via trashy.theme.css. This is mostly just an example — inspired by PaperCSS) — of how to make UI look "hand drawn," to prevent observers from being too fixated on the look and feel, rather than the semantics of a document. Here’s the example theme in action.
Trashy: "Debug"
Lastly, there is a trashy.debug.css file that highlights and calls out invalid and/or problematic markup. Here’s a gnarly example of "everything" going wrong on a single HTML page. This was inspired by a11y.css, though it diverges in what is considered noteworthy.
For instance, we call out "div-itis" when multiple div:only-child have been nested within one another. We're also opinionated about type="checkbox" being contained inside of a <label>. This is for maximum click-ability within an otherwise dead whitespace gap, between a checkbox (or radio) and its textual label.
Any or all of these CSS files can be applied individually or in conjunction with one another. There is also a bookmarklet (labeled "GET TRASHY!") on the Trashy home page you can use to get results for any webpage.
The bookmarklet will remotely pull in:
sanitize.css
trashy.css
trashy.boxes.css
trashy.debug.css
Our "reset" - Sanitize.css
A quick word on Santitize.css: It was created by my coworker Jonathan Neal (author of Normalize.css), as a way to have a semi-opinionated CSS "reset." Meaning, it puts in a lot of defaults that we find ourselves writing as developers anyway, so it makes for a good starting point.
Technically speaking
Okay, so now that we’ve covered the "why," let’s dig into the "how."
Basically, it all revolves around using (abusing?) the ::before and ::after pseudo elements. For instance, to show the name of a block level tag, we’re using this CSS.
Semantic tags (using ::before)
Here is an abbreviated version of the trashy.boxes.css file, for succinctness. It causes the <section> tag to have a dashed border, and to have its tag named displayed the top left corner.
Likewise, here’s a snippet of code from the trashy.debug.css file that drives the markup warning messages. This particular example causes <script> tags to be displayed, which may be further optimized or need the developer’s attention: inline JavaScript and/or external src without async.
In the case of inline JS, we set the font-size and line-height to 0 because we’re making the element visible. We yank the text off the page via text-indent: -99999px just to make sure it doesn’t show up. We wouldn’t want that random JS code displayed alongside legit page content.
(Please don’t ever do this for "real" content. It’s just a hack, mkay?)
To get our error message to show up though, we have to set the font-size and line-height back to non-zero values, and remove our text-indent. Then, with a bit more absolute positioning, we ensure the message is visible. This lets us see, amidst the rest of the page content, whereabouts to check (via DOM inspector) for the <script> insertion point.
Note: Some scripts do need to be loaded synchronously. You wouldn’t want your "app" code to load before your "framework" code. Heck, some inline JS is probably fine too, especially if you’re doing some super speed optimization for the critical rendering path. These warnings are "dumb" in the sense that they match only via CSS selectors. Take ‘em with a grain of salt, your mileage may vary, etc.
JS bookmarklet
The aforementioned JS bookmarklet finds all <link rel="stylesheet"> and <style> tags in the page, and causes them to be ineffective. This allows us to add in our own CSS to take over, so that the only styles applied are those provided directly via Trashy.
The magic is accomplished by setting rel="stylesheet" to rel="". If an external stylesheet is not identified as such, even if it’s cached, the browser will not apply its styles to the page. Similarly, we destroy the contents of any inline <style> tags by setting the innerHTML to an empty string.
This leaves us with the tags themselves still intact, because we still want to validate that no <link> or <style> tags are present within <body>.
We also check that there aren’t too many <style> tags being used in the <head>. We allow for one, since it could be used for the critical rendering path. If there’s a build process to generate a page with consolidated inline styles, then it’s likely they’re being emitted through a single tag.
<a href="javascript:(
function (d) {
var f = Array.prototype.forEach;
var linkTags = d.querySelectorAll('[rel=\'stylesheet\']');
var styleTags = d.querySelectorAll('style');
f.call(linkTags, function (x) {
x.rel = '';
});
f.call(styleTags, function (x) {
x.innerHTML = '';
});
var newLink = d.createElement('link');
newLink.rel = 'stylesheet';
newLink.href =
'https://t7.github.io/trashy.css/css/bookmarklet.css';
d.head.appendChild(newLink);
}
)(document);">
GET TRASHY!
</a>
That pretty much covers it. It's a simple drop-in to help you visualize your document semantics and debug possibly problematic markup.
I have also found it to be super fun to use. A quick click of the bookmarklet on any given site usually yields lots of things that could be improved upon.
For instance, here's what CNN's site looks like with Trashy applied…
P.S. Call security!
If you try this with Twitter’s site, you might wonder why it doesn’t work. We were initially perplexed by this, too. It has to do with the site's Content Security Policy (CSP). This can be used to disallow CSS and/or JavaScript from being loaded externally, and can whitelist safe domains.
This can be set either at the server level, or by a <meta> tag in the <head>.
In the case of Twitter, it’s emitted from the server. Even if it were in the HTML, destroying it has no effect on the actual browser behavior. It’s locked in.
Okay, so...
Can’t you insert your own security meta tag and override it?
You’d think so. But, thankfully, no. Once a CSP been accepted by the browser for that page, it cannot be overridden. That’s probably a good thing, even though it ruins our fun.
I suppose that’d be like wishing for more wishes. It’s against the genie rules!
Ever spent an hour (or even a day) working on something just to throw the whole lot away and redo it in five minutes? That isn’t just a beginner’s code mistake; it is a real-world situation that you can easily find yourself in especially if the problem you’re trying to solve isn’t well understood to begin with.
This is why I’m such a big proponent of upfront design, user research, and creating often multiple prototypes — also known as the old adage of “You don’t know what you don’t know.” At the same time, it is very easy to look at something someone else has made, which may have taken them quite a lot of time, and think it is extremely easy because you have the benefit of hindsight by seeing a finished product.
This idea that simple is easy was summed up nicely by Jen Simmons while speaking about CSS Grid and Piet Mondrian’s paintings:
“I feel like these paintings, you know, if you look at them with the sense of like ‘Why’s that important? I could have done that.’ It's like, well yeah, you could paint that today because we’re so used to this kind of thinking, but would you have painted this when everything around you was Victorian — when everything around you was this other style?”
I feel this sums up the feeling I have about seeing websites and design systems that make complete sense; it’s almost as if the fact they make sense means they were easy to make. Of course, it is usually the opposite; writing the code is the simple bit, but it’s the thinking and process that goes into it that takes the most effort.
With that in mind, I’m going to explore building a text box, in an exaggeration of situations many of us often find ourselves in. Hopefully, by the end of this article, we can all feel more emphatic to how the journey from start to finish is rarely linear.
A Comprehensive Guide To User Testing
So you think you’ve designed something that’s perfect, but your test tells you otherwise. Let’s explore the importance of user testing. Read more →
Brief
We all know that careful planning and understanding of the user need is important to a successful project of any size. We also all know that all too often we feel to need to rush to quickly design and develop new features. That can often mean our common sense and best practices are forgotten as we slog away to quickly get onto the next task on the everlasting to-do list. Rinse and repeat.
Today our task is to build a text box. Simple enough, it needs to allow a user to type in some text. In fact, it is so simple that we leave the task to last because there is so much other important stuff to do. Then, just before we pack up to go home, we smirk and write:
<input type="text">
There we go!
Oh wait, we probably need to hook that up to send data to the backend when the form is submitted, like so:
<input type="text" name="our_textbox">
That’s better. Done. Time to go home.
How Do You Add A New Line?
The issue with using a simple text box is it is pretty useless if you want to type a lot of text. For a name or title it works fine, but quite often a user will type more text than you expect. Trust me when I say if you leave a textbox for long enough without strict validation, someone will paste the entire of War and Peace. In many cases, this can be prevented by having a maximum amount of characters.
In this situation though, we have found out that our laziness (or bad prioritization) of leaving it to the last minute meant we didn’t consider the real requirements. We just wanted to do another task on that everlasting to-do list and get home. This text box needs to be reusable; examples of its usage include as a content entry box, a Twitter-style note box, and a user feedback box. In all of those cases, the user is likely to type a lot of text, and a basic text box would just scroll sideways. Sometimes that may be okay, but generally, that’s an awful experience.
Thankfully for us, that simple mistake doesn’t take long to fix:
<textarea name="our_textbox"></textarea>
Now, let’s take a moment to consider that line. A <textarea>: as simple as it can get without removing the name. Isn’t it interesting, or is it just my pedantic mind that we need to use a completely different element to add a new line? It isn’t a type of input, or an attribute used to add multi-line to an input. Also, the <textarea> element is not self-closing but an input is? Strange.
This “moment to consider” sent me time traveling back to October 1993, trawling through the depths of the www-talk mailing list. There was clearly much discussion about the future of the web and what “HTML+” should contain. This was 1993 and they were discussing ideas such as <input type="range"> which wasn’t available until HTML5, and Jim Davis said:
“Well, it's far-fetched I suppose, but you might use HTML forms as part of a game playing interface.”
This really does show that the web wasn’t just intended to be about documents as is widely believed. Marc Andreessen suggested to have <input type="textarea"> instead of allowing new lines in the single-line text type, [saying]: (http://1997.webhistory.org/www.lists/www-talk.1993q4/0200.html)
“Makes the browser code cleaner — they have to be handled differently internally.”
That’s a fair reason to have <textarea> separate to text, but that’s still not what we ended up with. So why is <textarea> its own element?
I didn’t find any decision in the mailing list archives, but by the following month, the HTML+ Discussion Document had the <textarea> element and a note saying:
“In the initial design for forms, multi-line text fields were supported by the INPUT element with TYPE=TEXT. Unfortunately, this causes problems for fields with long text values as SGML limits the length of attributea literals. The HTML+ DTD allows for up to 1024 characters (the SGML default is only 240 characters!)”
Ah, so that’s why the text goes within the element and cannot be self-closing; they were not able to use an attribute for long text. In 1994, the <textarea> element was included, along with many others from HTML+ such as <option> in the HTML 2 spec.
Okay, that’s enough. I could easily explore the archives further but back to the task.
Styling A <textarea>
So we’ve got a default <textarea>. If you rarely use them or haven’t seen the browser defaults in a long time, then you may be surprised. A <textarea> (made almost purely for multi-line text) looks very similar to a normal text input except most browser defaults style the border darker, the box slightly larger, and there are lines in the bottom right. Those lines are the resize handle; they aren’t actually part of the spec so browsers all handle (pun absolutely intended) it in their own way. That generally means that the resize handle cannot be restyled, though you can disable resizing by setting resize: none to the <textarea>. It is possible to create a custom handle or use browser specific pseudo elements such as ::-webkit-resizer.
It’s important to understand the defaults, especially because of the resizing ability. It’s a very unique behavior; the user is able to drag to change the size of the element by default. If you don’t override the minimum and maximum sizes then the size could be as small as 9px × 9px (when I checked Chrome) or as large as they have patience to drag it. That’s something that could cause mayhem with the rest of the site’s layout if it’s not considered. Imagine a grid where <textarea> is in one column and a blue box is in another; the size of the blue box is purely decided by the size of the <textarea>.
Other than that, we can approach styling a <textarea> much the same as any other input. Want to change the grey around the edge into thick green dashes? Sure here you go: border: 5px dashed green;. Want to restyle the focus in which a lot of browsers have a slightly blurred box shadow? Change the outline — responsibly though, you know, that’s important for accessibility. You can even add a background image to your <textarea> if that interests you (I can think of a few ideas that would have been popular when skeuomorphic design was more celebrated).
Scope Creep
We’ve all experienced scope creep in our work, whether it is a client that doesn’t think the final version matches their idea or you just try to squeeze in a tiny tweak and end up taking forever to finish it. So I ( enjoying creating the persona of an exaggerated project manager telling us what we need to build) have decided that our <textarea> just is not good enough. Yes, it is now multi-line, and that’s great, and yes it even ‘pops’ a bit more with its new styling. Yet, it just doesn’t fit the very vague user need that I’ve pretty much just thought of now after we thought we were almost done.
What happens if the user puts in thousands of words? Or drags the resize handle so far it breaks the layout? It needs to be reusable, as we have already mentioned, but in some of the situations (such as a ‘Twittereqsue’ note taking box), we will need a limit. So the next task is to add a character limit. The user needs to be able to see how many characters they have left.
In the same way we started with <input> instead of <textarea>, it is very easy to think that adding the maxlength attribute would solve our issue. That is one way to limit the amount of characters the user types, it uses the browser’s built-in validation, but it is not able to display how many characters are left.
We started with the HTML, then added the CSS, now it is time for some JavaScript. As we’ve seen, charging along like a bull in a china shop without stopping to consider the right approaches can really slow us down in the long run. Especially in situations where there is a large refactor required to change it. So let’s think about this counter; it needs to update as the user types, so we need to trigger an event when the user types. It then needs to check if the amount of text is already at the maximum length.
So which event handler should we choose?
change
Intuitively, it may make sense to choose the change event. It works on <textarea> and does what it says on the tin. Except, it only triggers when the element loses focus so it wouldn’t update while typing.
keypress
The keypress event is triggered when typing any character, which is a good start. But it does not trigger when characters are deleted, so the counter wouldn’t update after pressing backspace. It also doesn’t trigger after a copy/paste.
keyup
This one gets quite close, it is triggered whenever a key has been pressed (including the backspace button). So it does trigger when deleting characters, but still not after a copy/paste.
input
This is the one we want. This triggers whenever a character is added, deleted or pasted.
This is another good example of how using our intuition just isn’t enough sometimes. There are so many quirks (especially in JavaScript!) that are all important to consider before getting started. So the code to add a counter that updates needs to update a counter (which we’ve done with a span that has a class called counter) by adding an input event handler to the <textarea>. The maximum amount of characters is set in a variable called maxLength and added to the HTML, so if the value is changed it is changed in only one place.
var textEl = document.querySelector('textarea')
var counterEl = document.querySelector('.counter')
var maxLength = 200
textEl.setAttribute('maxlength', maxLength)
textEl.addEventListener('input', (val) => {
var count = textEl.value.length
counterEl.innerHTML = ${count}/${maxLength}
})
Browser Compatibility And Progressive Enhancement
Progressive enhancement is a mindset in which we understand that we have no control over what the user exactly sees on their screen, and instead, we try to guide the browser. Responsive Web Design is a good example, where we build a website that adjusts to suit the content on the particular size viewport without manually setting what each size would look like. It means that on the one hand, we strongly care that a website works across all browsers and devices, but on the other hand, we don’t care that they look exactly the same.
Currently, we are missing a trick. We haven’t set a sensible default for the counter. The default is currently “0/200” if 200 were the maximum length; this kind of makes sense but has two downsides. The first, it doesn’t really make sense at first glance. You need to start typing before it is obvious the 0 updates as you type. The other downside is that the 0 updates as you type, meaning if the JavaScript event doesn’t trigger properly (maybe the script did not download correctly or uses JavaScript that an old browser doesn’t support such as the double arrow in the code above) then it won’t do anything. A better way would be to think carefully beforehand. How would we go about making it useful when it is both working and when it isn’t?
In this case, we could make the default text be “200 character limit.” This would mean that without any JavaScript at all, the user would always see the character limit but it just wouldn’t feedback about how close they are to the limit. However, when the JavaScript is working, it would update as they type and could say “200 characters remaining” instead. It is a very subtle change but means that although two users could get different experiences, neither are getting an experience that feels broken.
Another default that we could set is the maxlength on the element itself rather than afterwards with JavaScript. Without doing this, the baseline version (the one without JS) would be able to type past the limit.
User Testing
It’s all very well testing on various browsers and thinking about the various permutations of how devices could serve the website in a different way, but are users able to use it?
Generally speaking, no. I’m consistently shocked by user testing; people never use a site how you expect them to. This means that user testing is crucial.
It’s quite hard to simulate a user test session in an article, so for the purposes of this article, I’m going to just focus on one point that I’ve seen users struggle with on various projects.
The user is happily writing away, gets to 0 characters remaining, and then gets stuck. They forget what they were writing, or they don’t notice that it had stopped typing.
This happens because there is nothing telling the user that something has changed; if they are typing away without paying much attention, then they can hit the maximum length without noticing. This is a frustrating experience.
One way to solve this issue is to allow overtyping, so the maximum length still counts for it to be valid when submitted but it allows the user to type as much as they want and then edit it before submission. This is a good solution as it gives the control back to the user.
Okay, so how do we implement overtyping? Instead of jumping into the code, let’s step through in theory. maxlength doesn’t allow overtyping, it just stops allowing input once it hits the limit. So we need to remove maxlength and write a JS equivalent. We can use the input event handler as we did before, as we know that works on paste, etc. So in that event, the handler would check if the user has typed more than the limit, and if so, the counter text could change to say “10 characters too many.” The baseline version (without the JS) would no longer have a limit at all, so a useful middle ground could be to add the maxlength to the element in the HTML and remove the attribute using JavaScript.
That way, the user would see that they are over the limit without being cut off while typing. There would still need to be validation to make sure it isn’t submitted, but that is worth the extra small bit of work to make the user experience far better.
This gets us to quite a solid position: the user is now able to use any device and get a decent experience. If they type too much it is not going to cut them off; instead, it will just allow it and encourage them to edit it down.
There’s a variety of ways this could be designed differently, so let’s look at how Twitter handles it:
Twitter has been iterating its main tweet <textarea> since they started the company. The current version uses a lot of techniques that we could consider using.
As you type on Twitter, there is a circle that completes once you get to the character limit of 280. Interestingly, it doesn’t say how many characters are available until you are 20 characters away from the limit. At that point, the incomplete circle turns orange. Once you have 0 characters remaining, it turns red. After the 0 characters, the countdown goes negative; it doesn’t appear to have a limit on how far you can overtype (I tried as far as 4,000 characters remaining) but the tweet button is disabled while overtyping.
So this works the same way as our <textarea> does, with the main difference being the characters represented by a circle that updates and shows the number of characters remaining after 260 characters. We could implement this by removing the text and replacing it with an SVG circle.
The other thing that Twitter does is add a red background behind the overtyped text. This makes it completely obvious that the user is going to need to edit or remove some of the text to publish the tweet. It is a really nice part of the design. So how would we implement that? We would start again from the beginning.
You remember the part where we realized that a basic input text box would not give us multiline? And that a maxlength attribute would not give us the ability to overtype? This is one of those cases. As far as I know, there is nothing in CSS that gives us the ability to style parts of the text inside a <textarea>. This is the point where some people would suggest web components, as what we would need is a pretend <textarea>. We would need some kind of element — probably a div — with contenteditable on it and in JS we would need to wrap the overtyped text in a span that is styled with CSS.
What would the baseline non-JS version look like then? Well, it wouldn’t work at all because while contenteditable will work without JS, we would have no way to actually do anything with it. So we would need to have a <textarea> by default and remove that if JS is available. We would also need to do a lot of accessibility testing because while we can trust a <textarea> to be accessible relying on browser features is a much safer bet than building your own components. How does Twitter handle it? You may have seen it; if you are on a train and your JavaScript doesn’t load while going into a tunnel then you get chucked into a decade-old legacy version of Twitter where there is no character limit at all.
What happens then if you tweet over the character limit? Twitter reloads the page with an error message saying “Your Tweet was over the character limit. You’ll have to be more clever.” No, Twitter. You need to be more clever.
Retro
The only way to conclude this dramatization is a retrospective. What went well? What did we learn? What would we do differently next time or what would we change completely?
We started very simple with a basic textbox; in some ways, this is good because it can be all too easy to overcomplicate things from the beginning and an MVP approach is good. However, as time went on, we realized how important it is to have some critical thinking and to consider what we are doing. We should have known a basic textbox wouldn’t be enough and that a way of setting a maximum length would be useful. It is even possible that if we have conducted or sat in on user research sessions in the past that we could have anticipated the need to allow overtyping. As for the browser compatibility and user experiences across devices, considering progressive enhancement from the beginning would have caught most of those potential issues.
So one change we could make is to be much more proactive about the thinking process instead of jumping straight into the task, thinking that the code is easy when actually the code is the least important part.
On a similar vein to that, we had the “scope creep” of maxlength, and while we could possibly have anticipated that, we would rather not have any scope creep at all. So everybody involved from the beginning would be very useful, as a diverse multidisciplinary approach to even small tasks like this can seriously reduce the time it takes to figure out and fix all the unexpected tweaks.
Back To The Real World
Okay, so I can get quite deep into this made-up project, but I think it demonstrates well how complicated the most seemingly simple tasks can be. Being user-focussed, having a progressive enhancement mindset, and thinking things through from the beginning can have a real impact on both the speed and quality of delivery. And I didn’t even mention testing!
I went into some detail about the history of the <textarea> and which event listeners to use, some of this can seem overkill, but I find it fascinating to gain a real understanding of the subtleties of the web, and it can often help demystify issues we will face in the future.


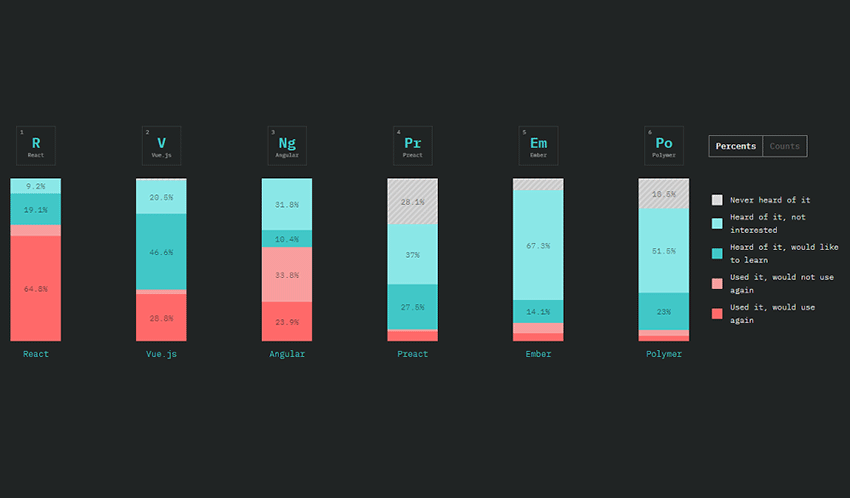

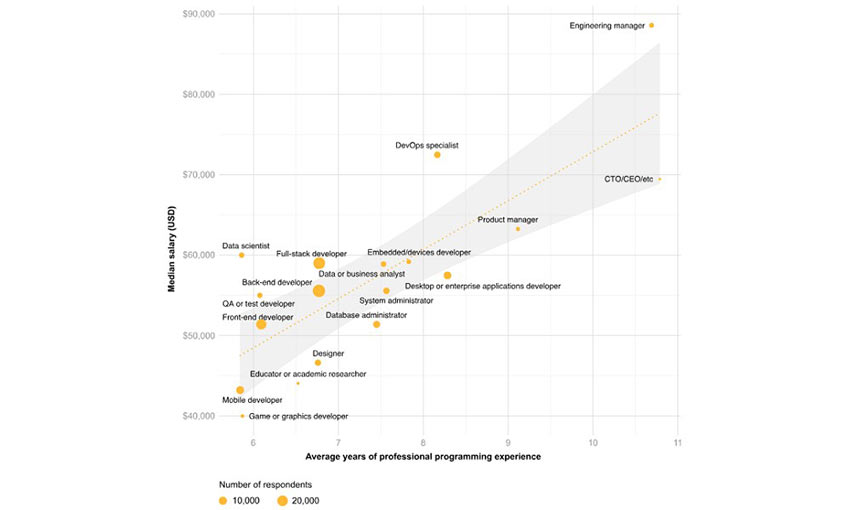
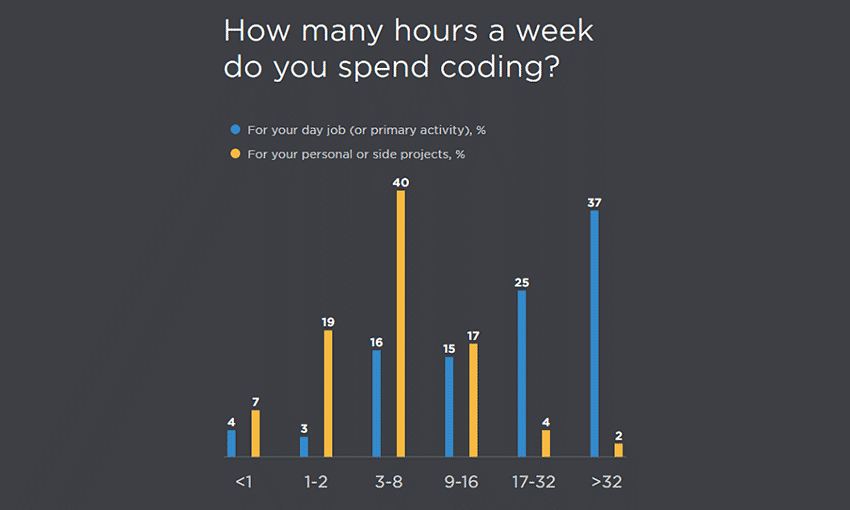
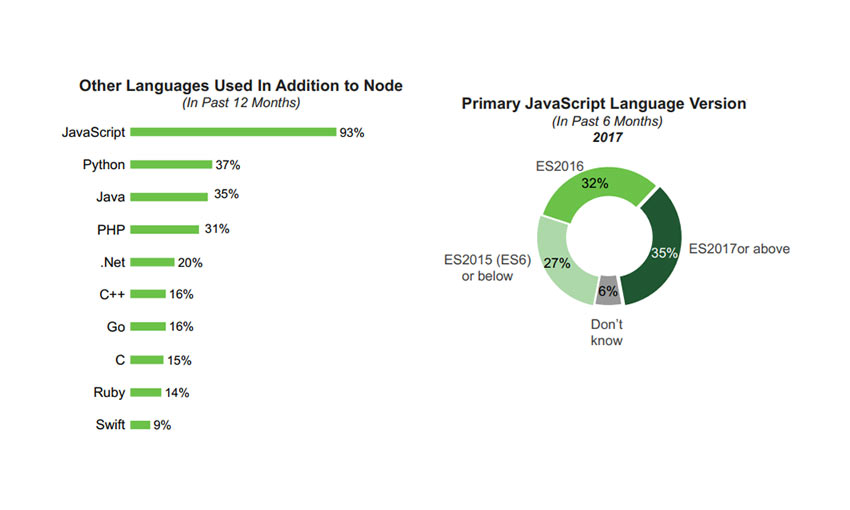
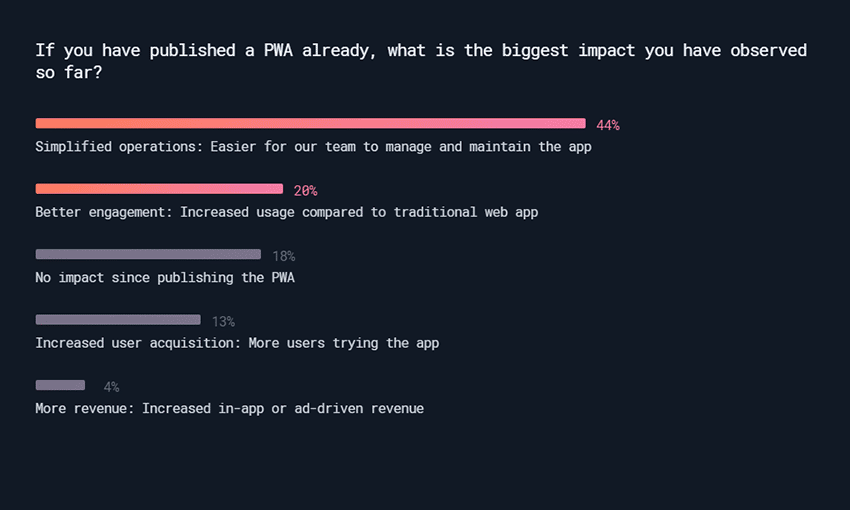

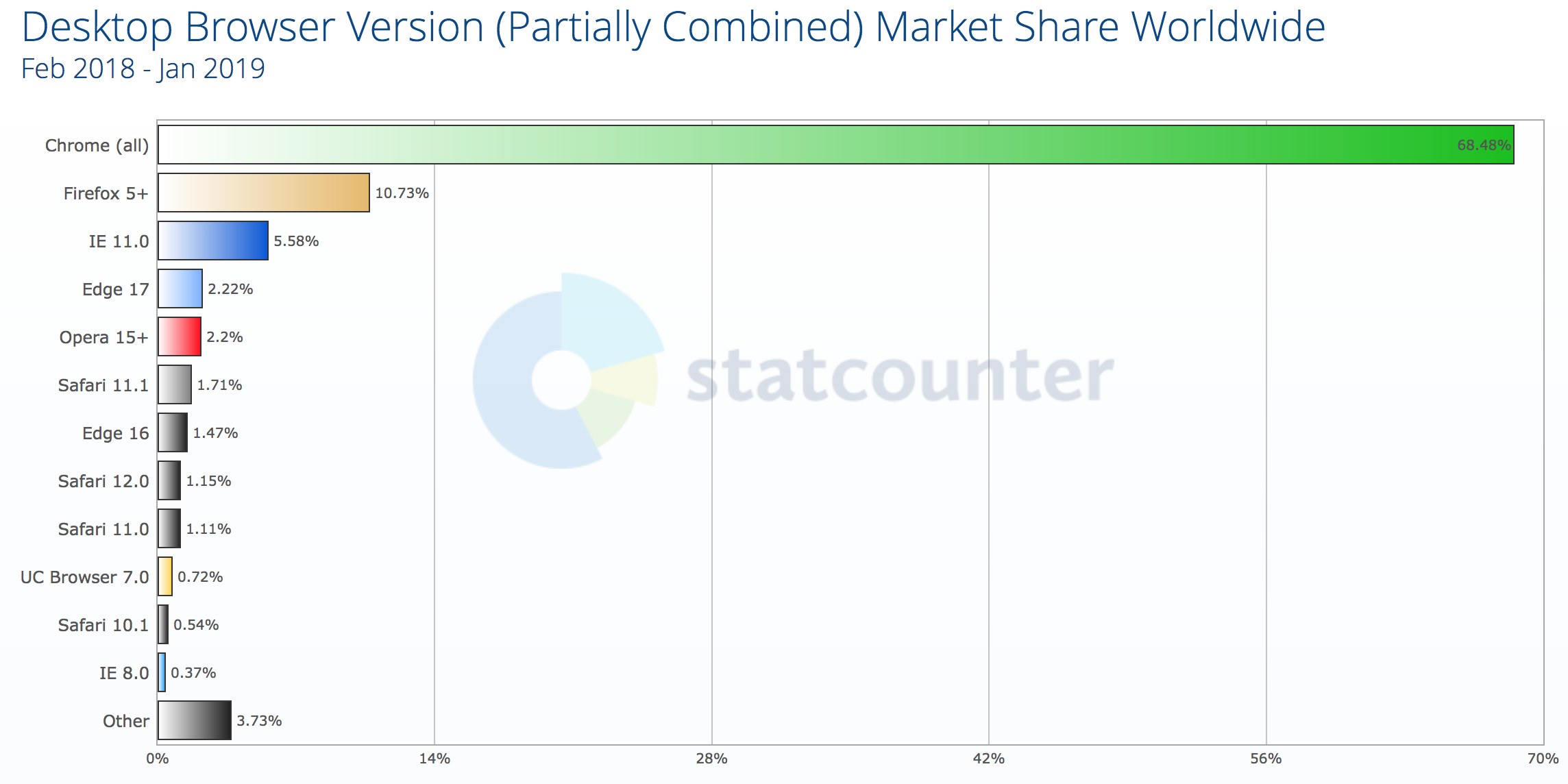
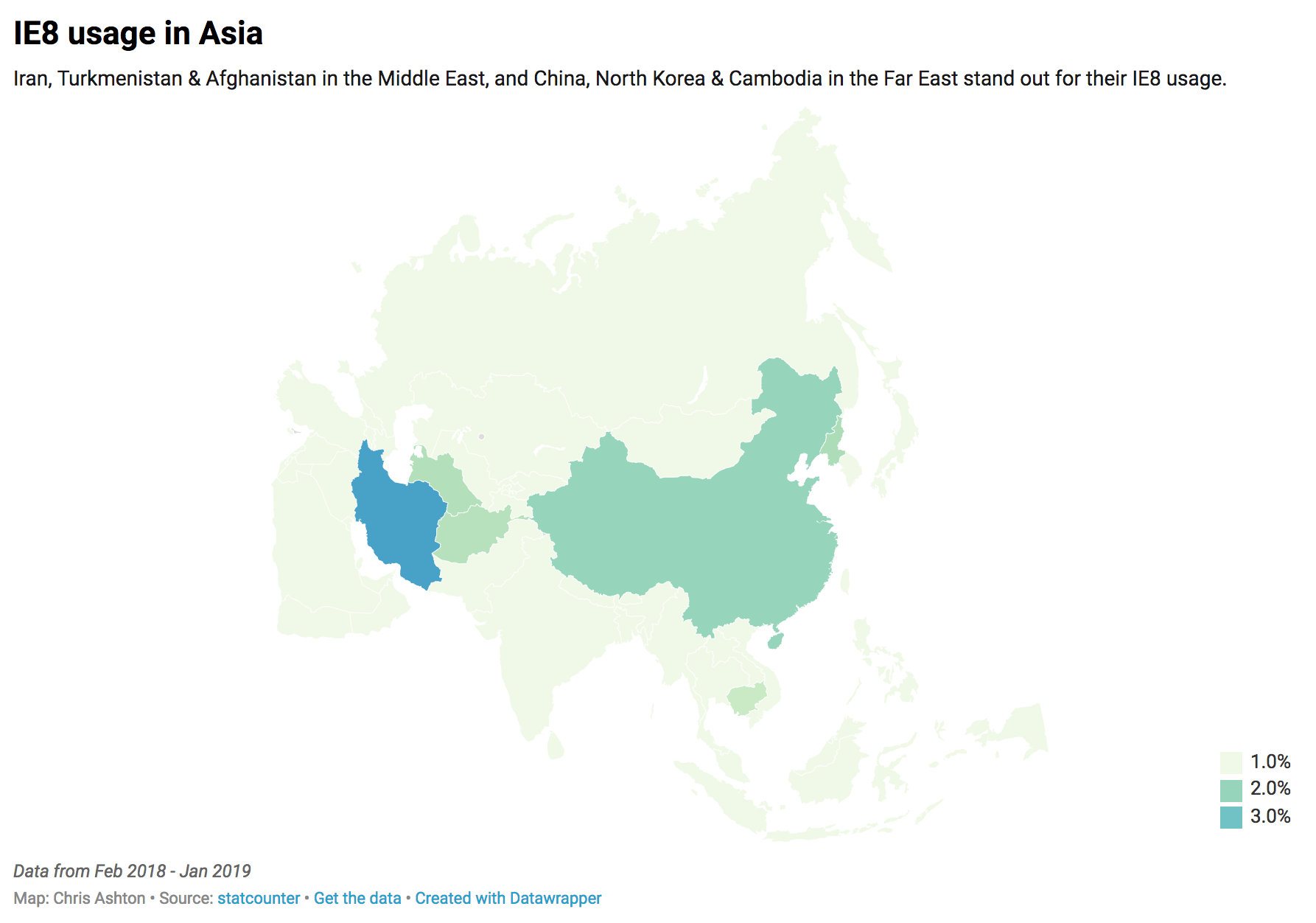
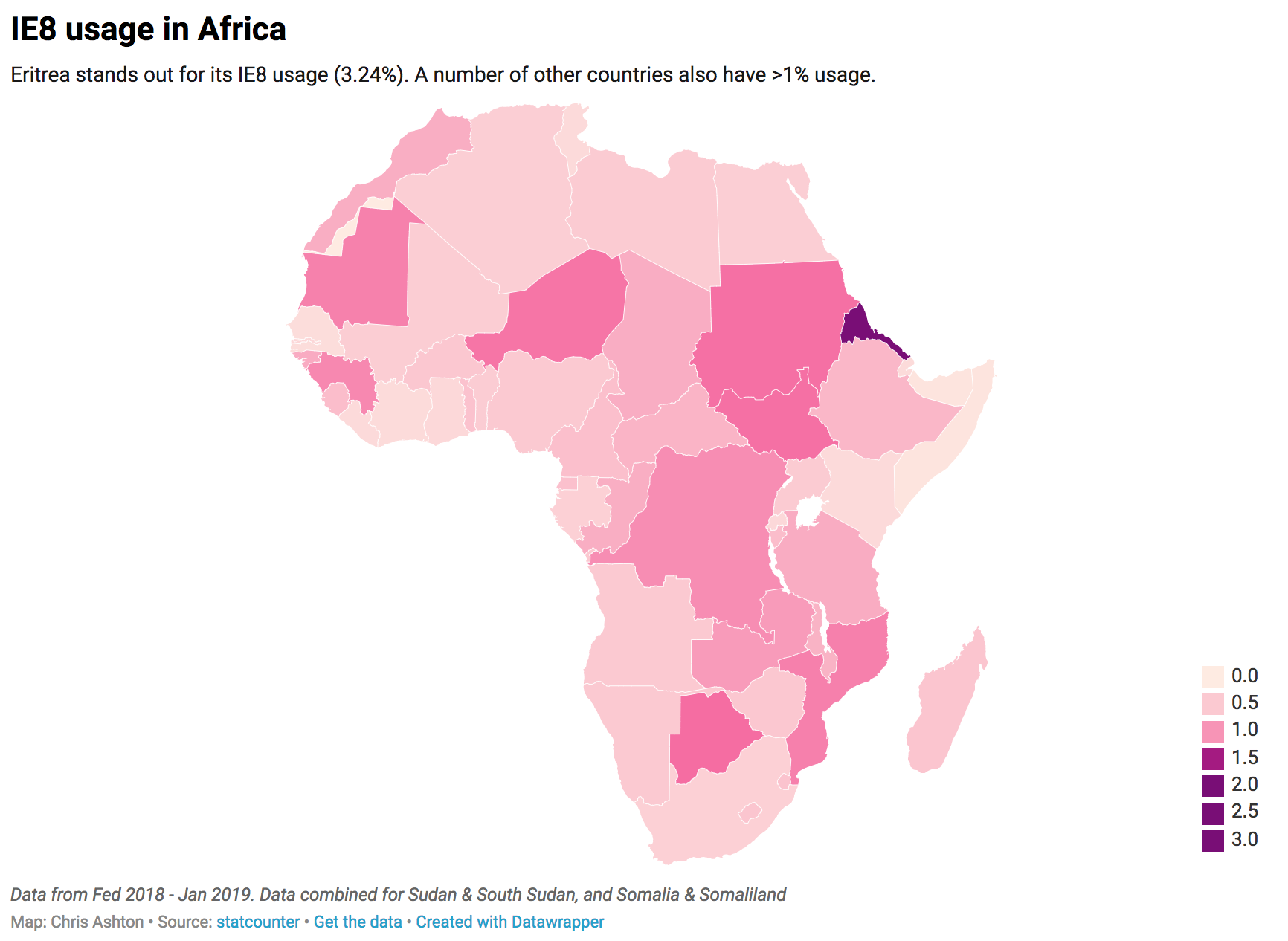
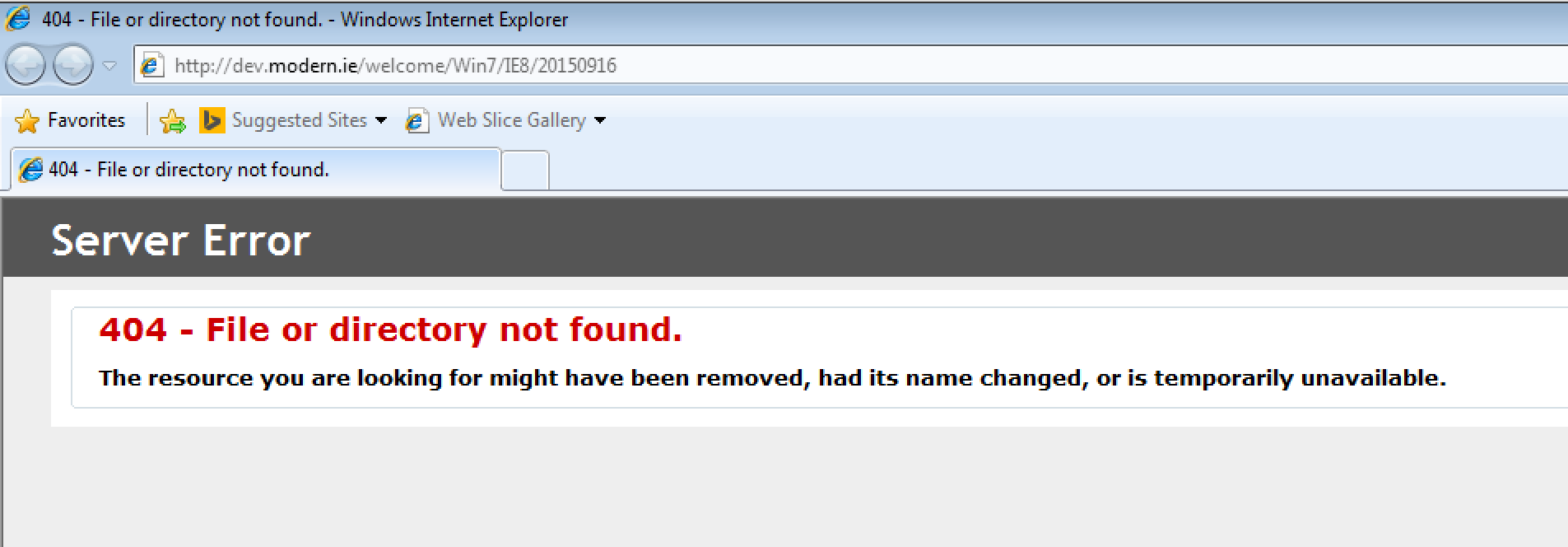



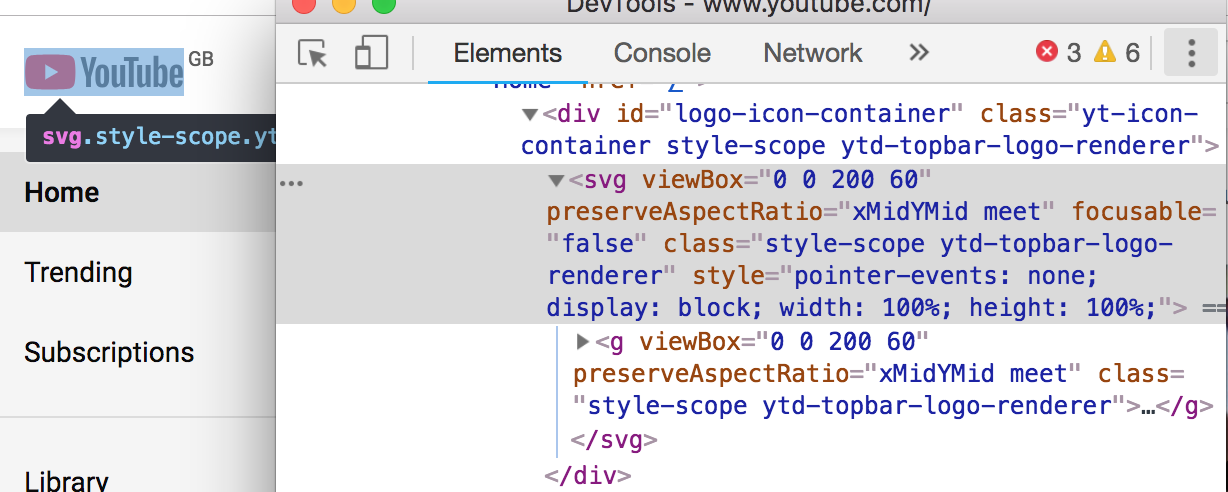








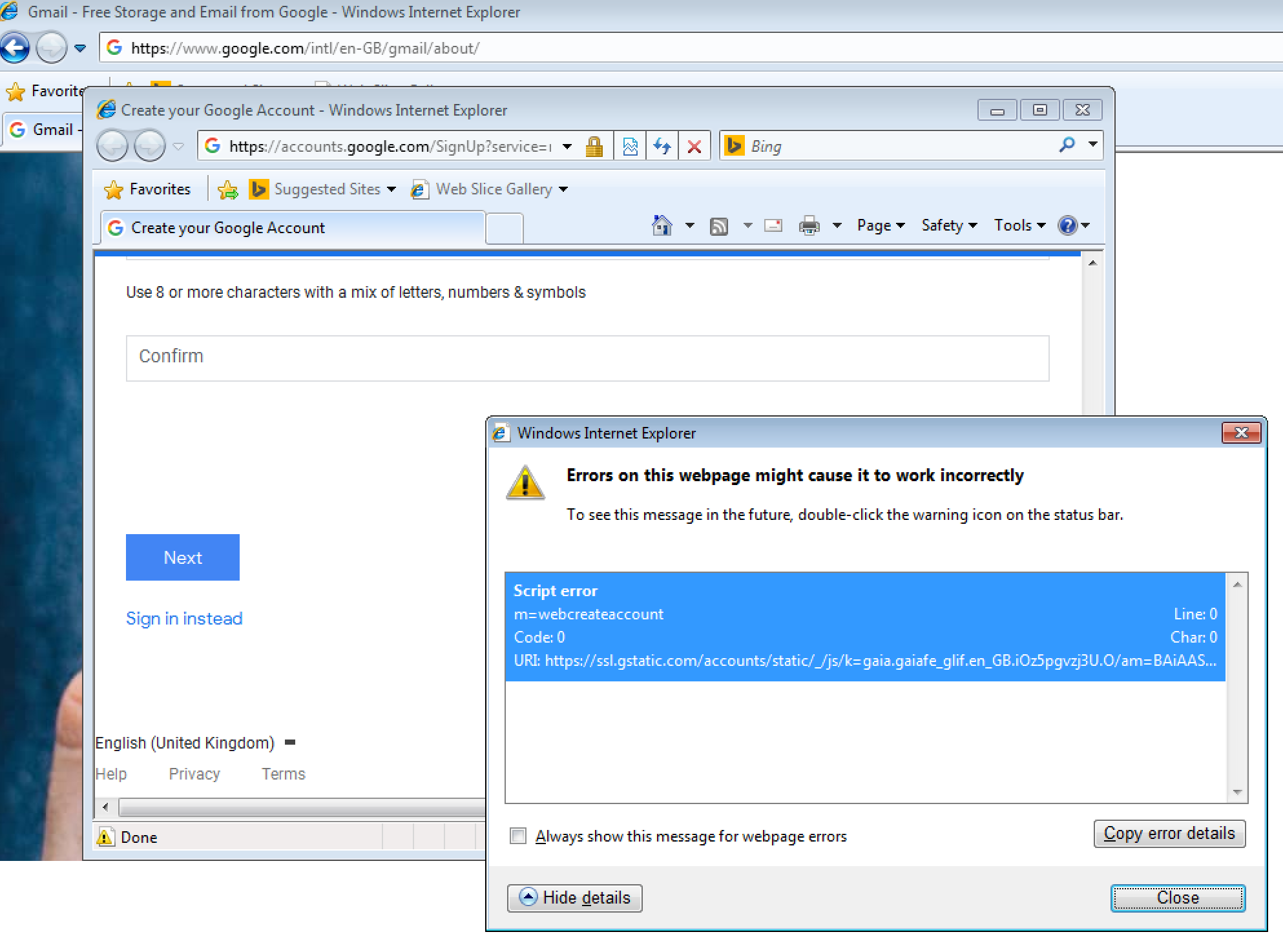
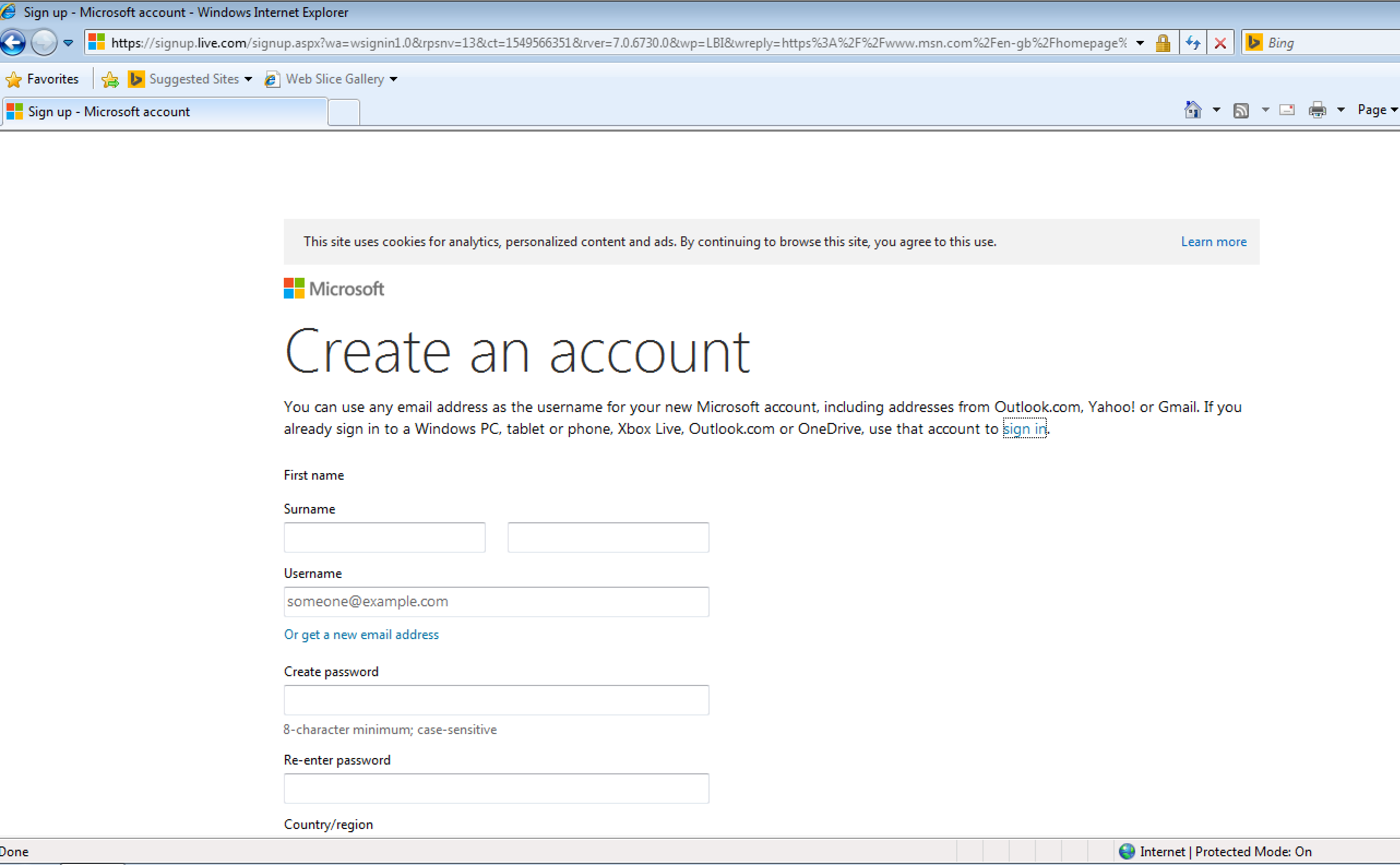
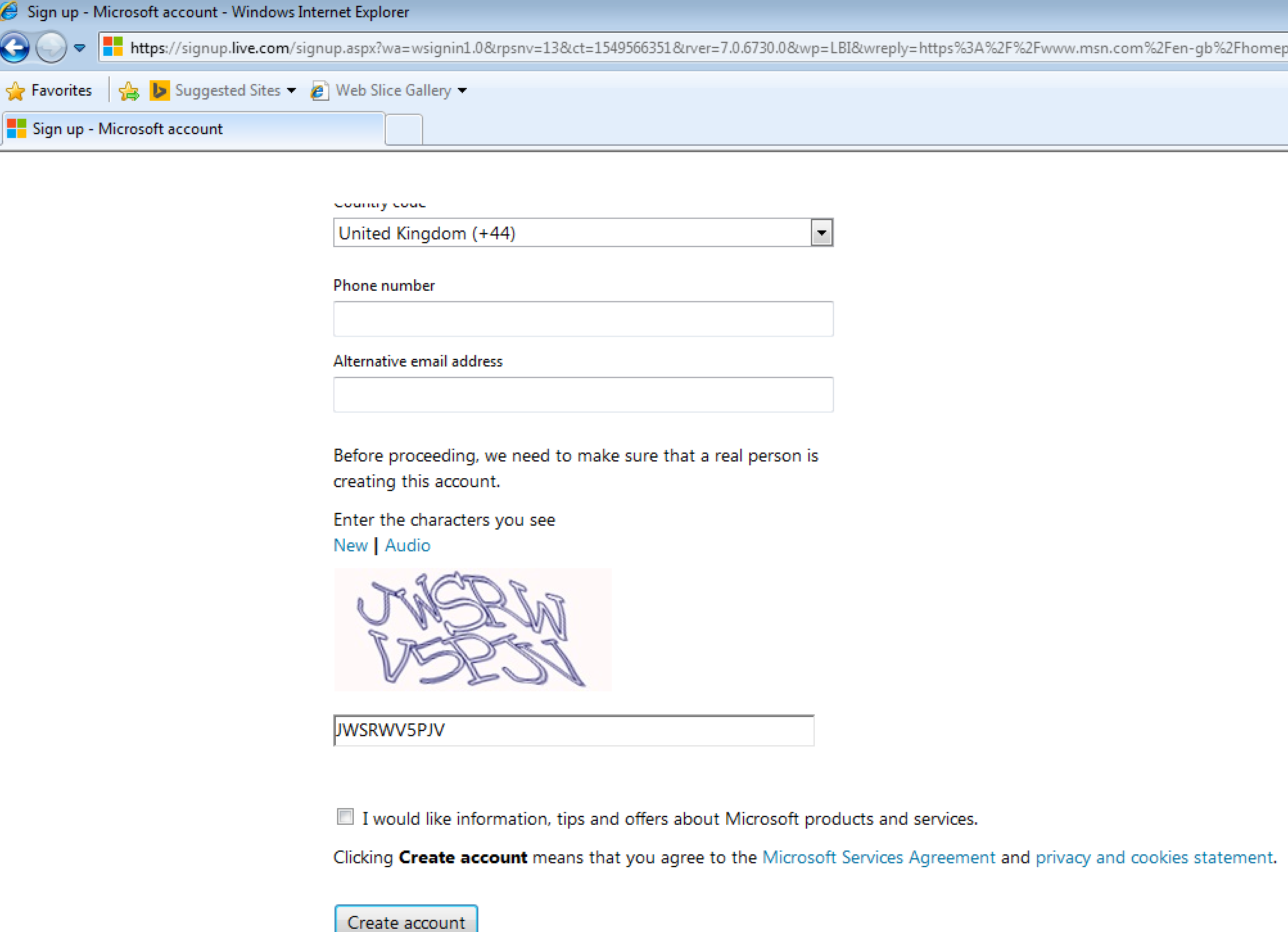


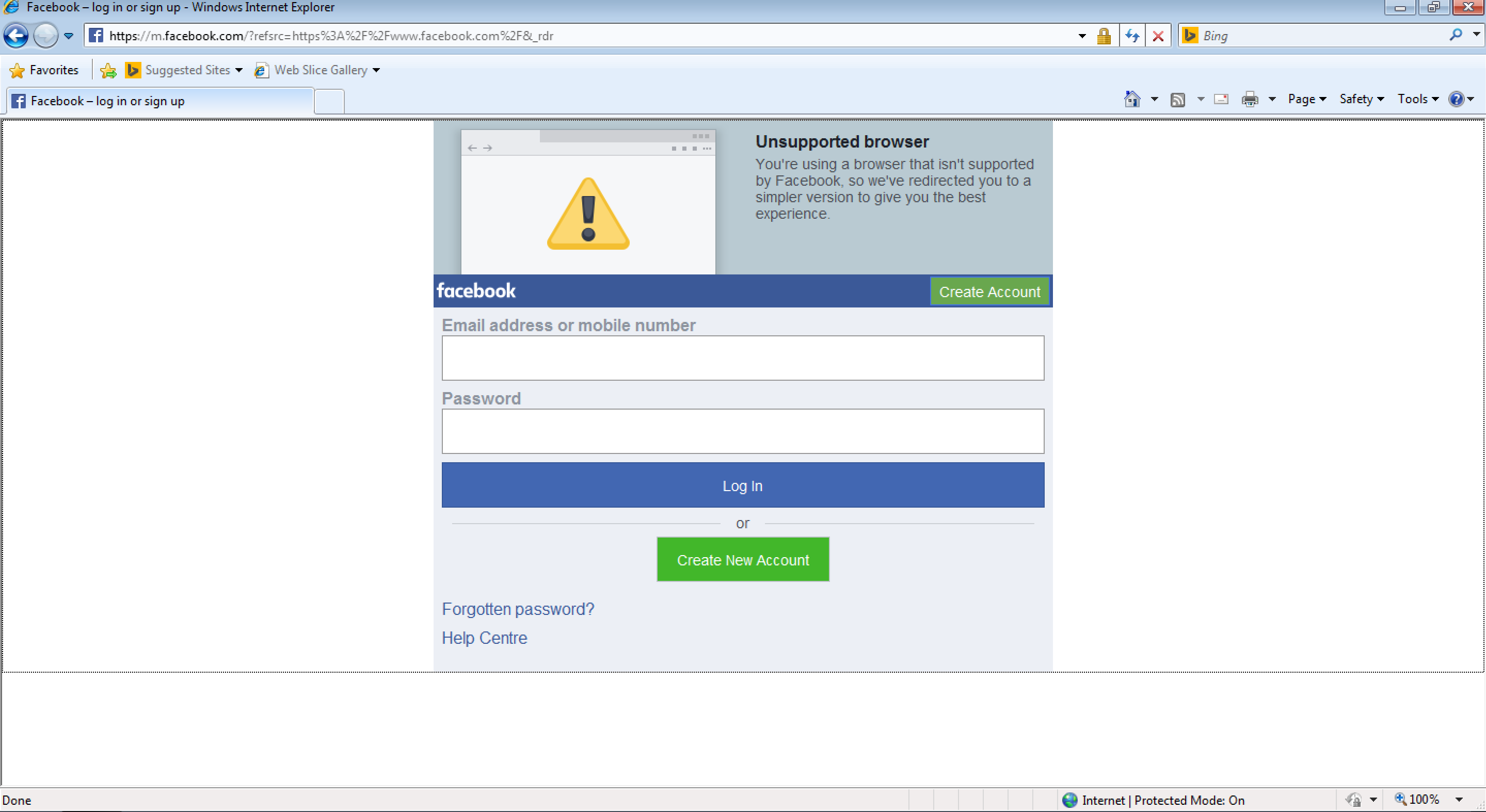
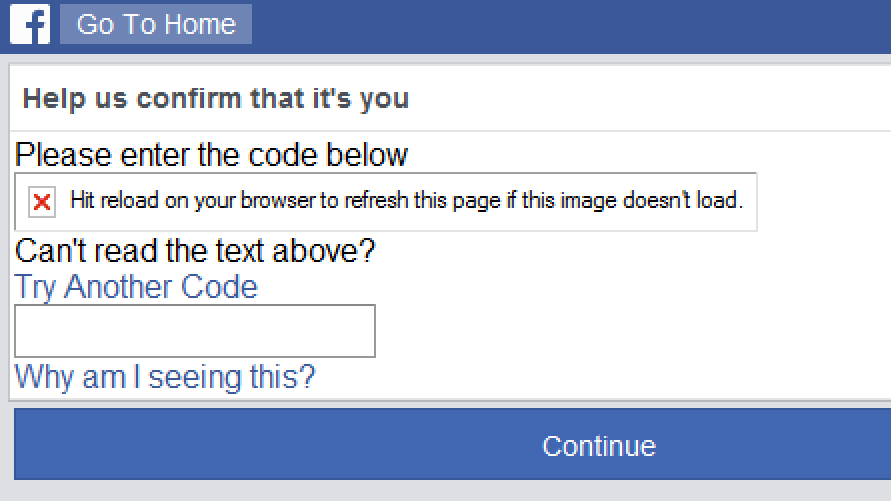












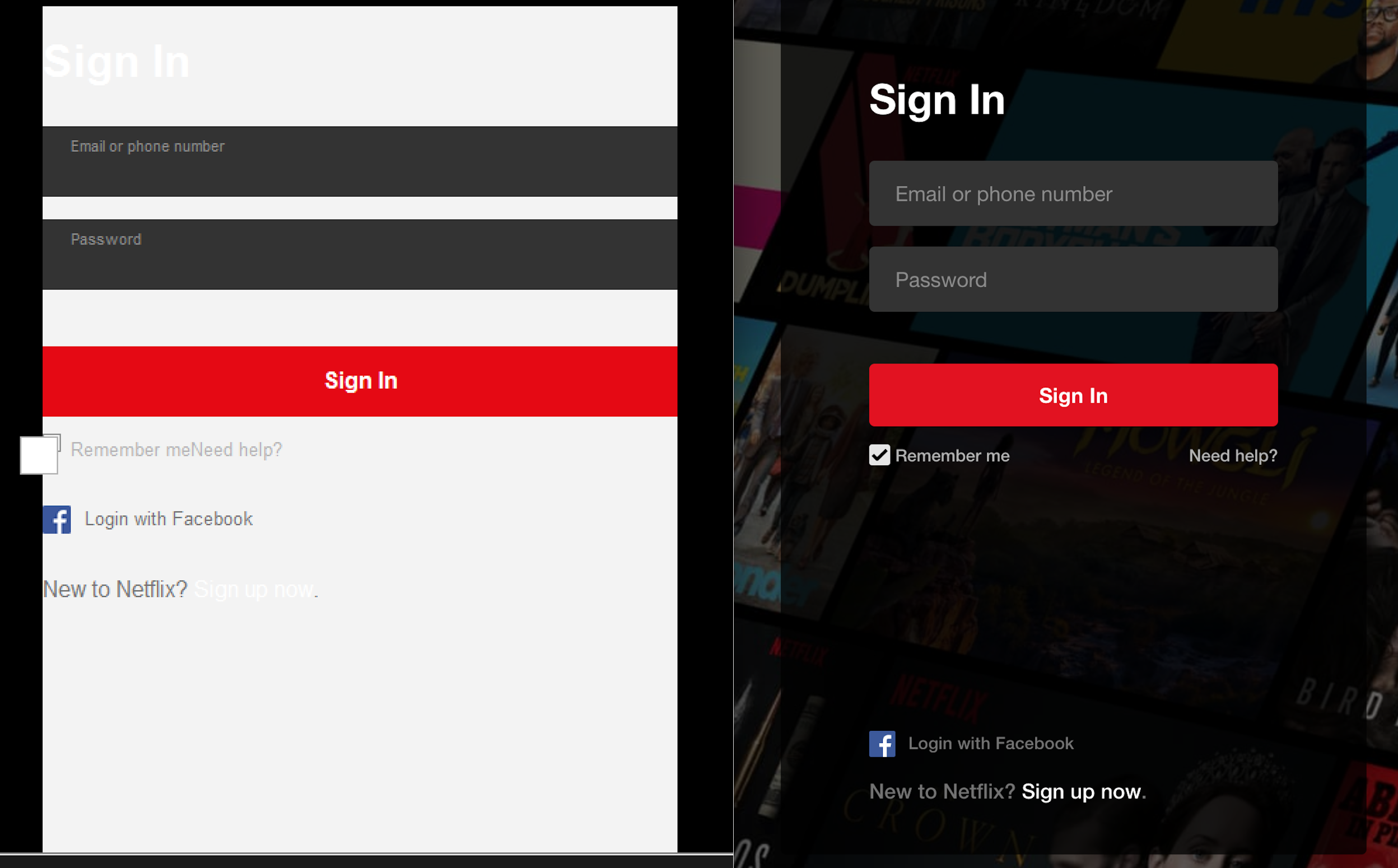




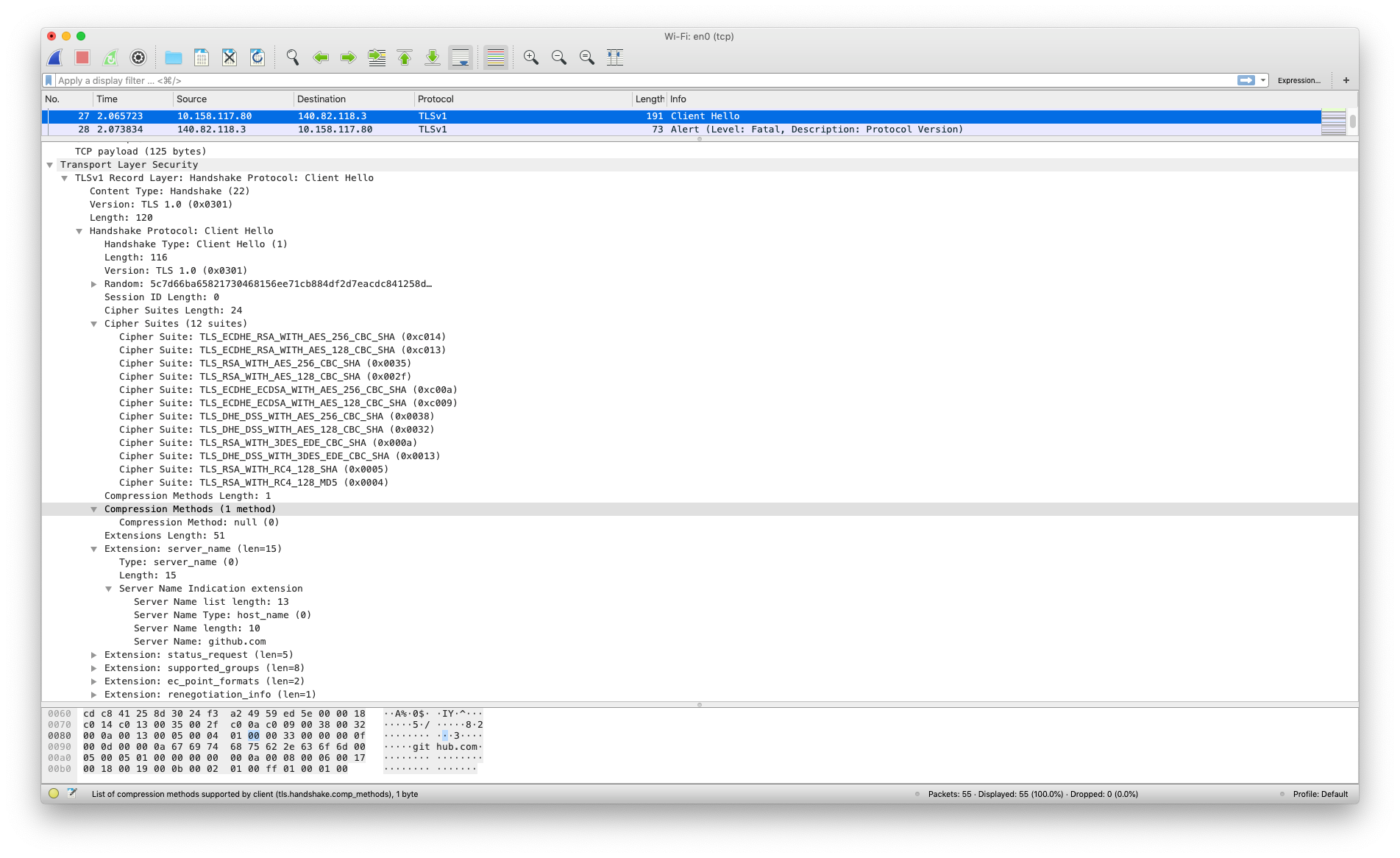
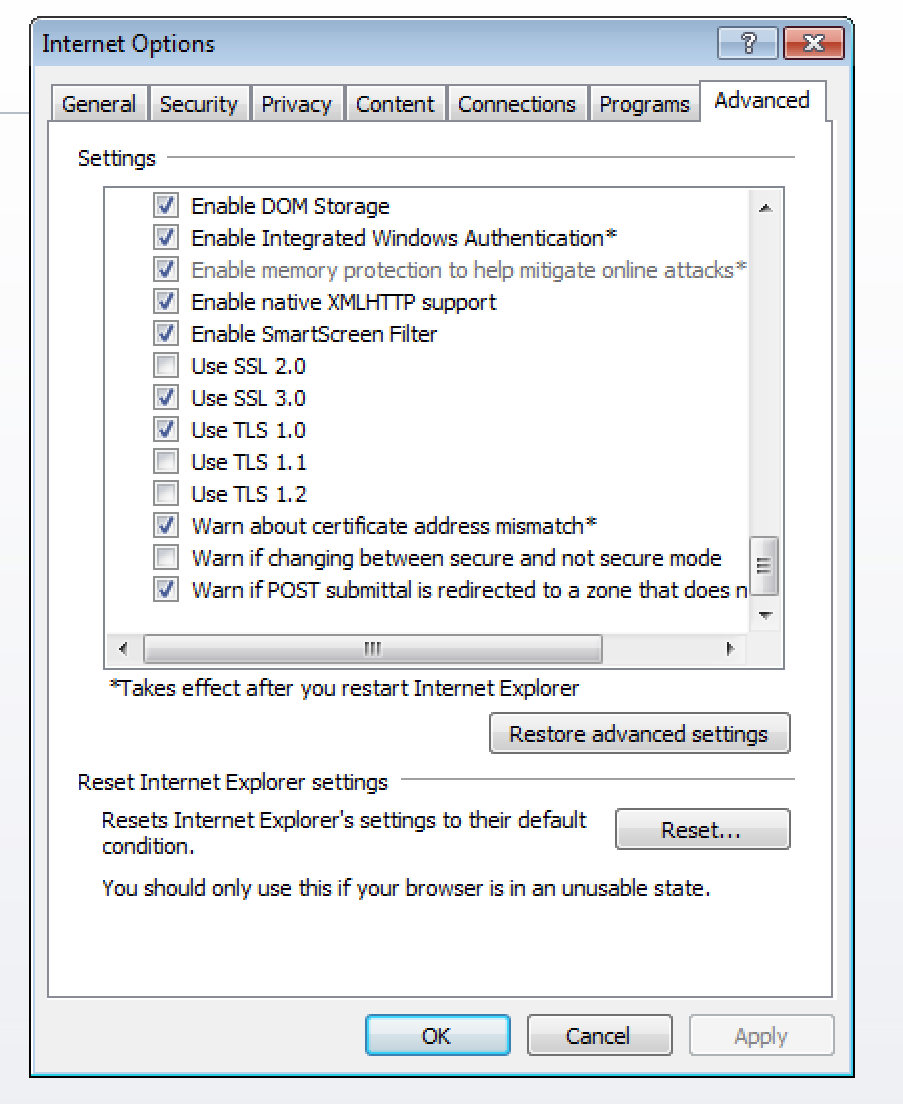

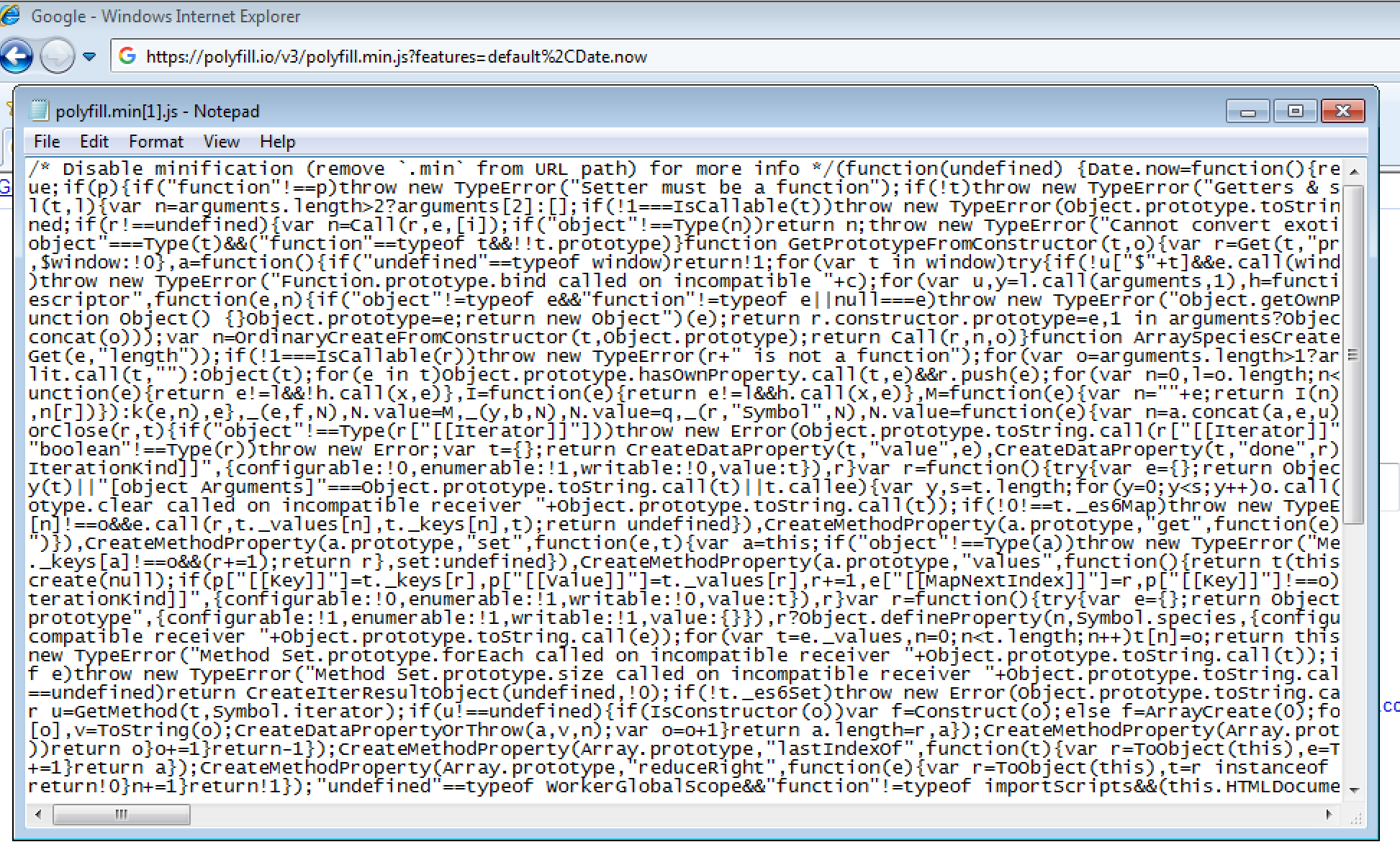






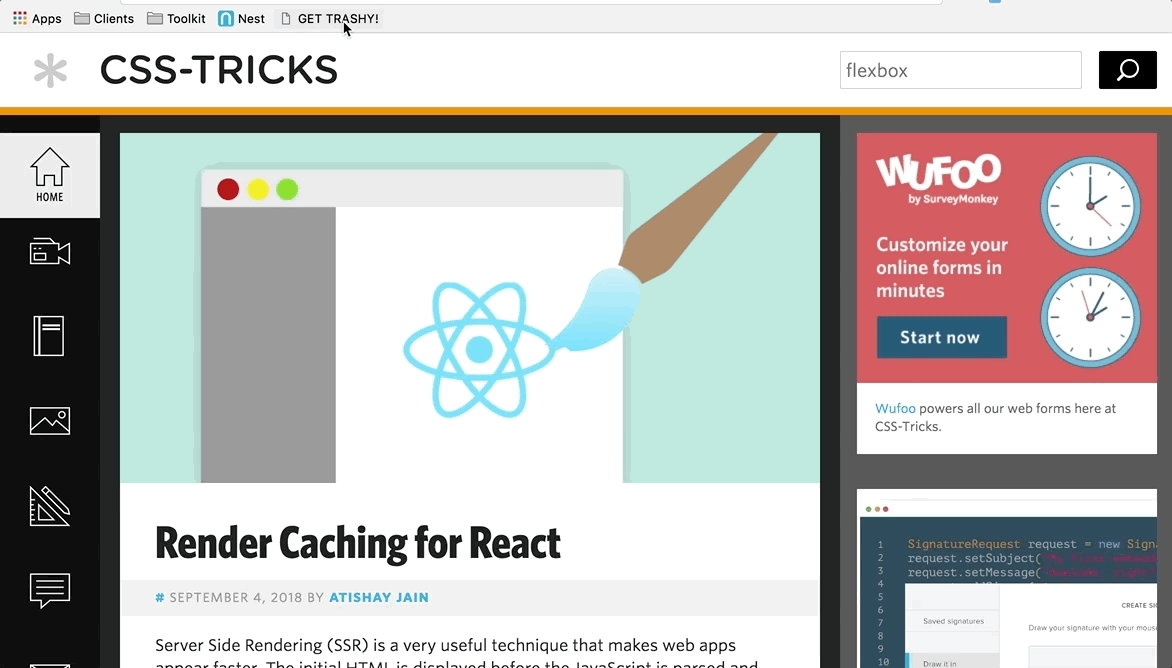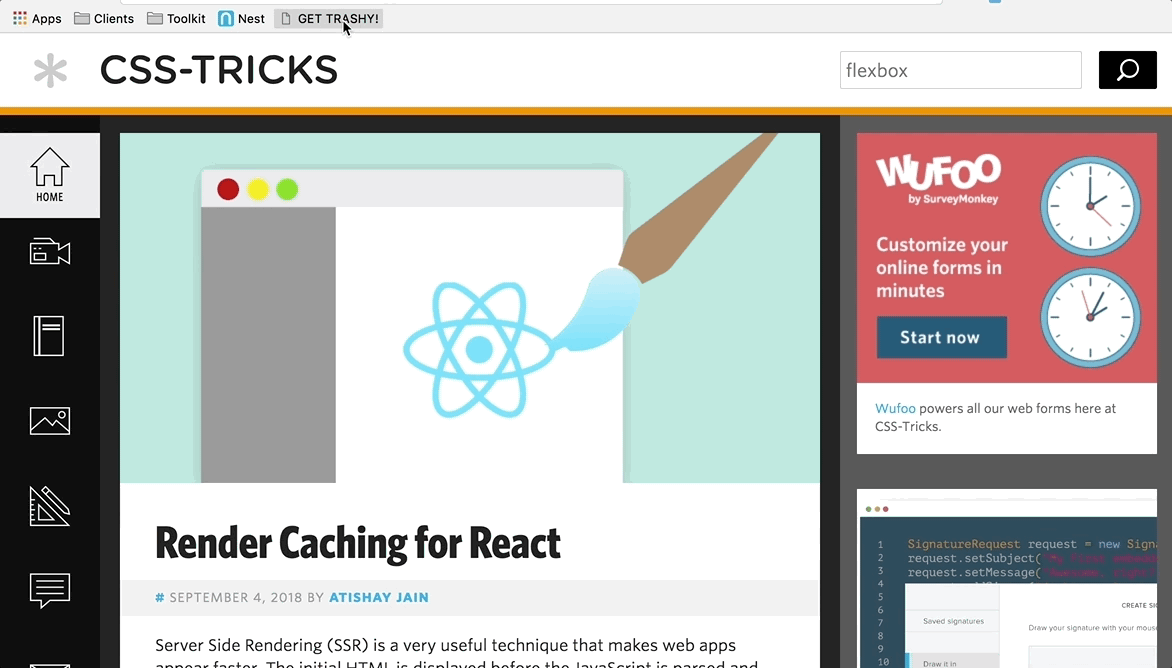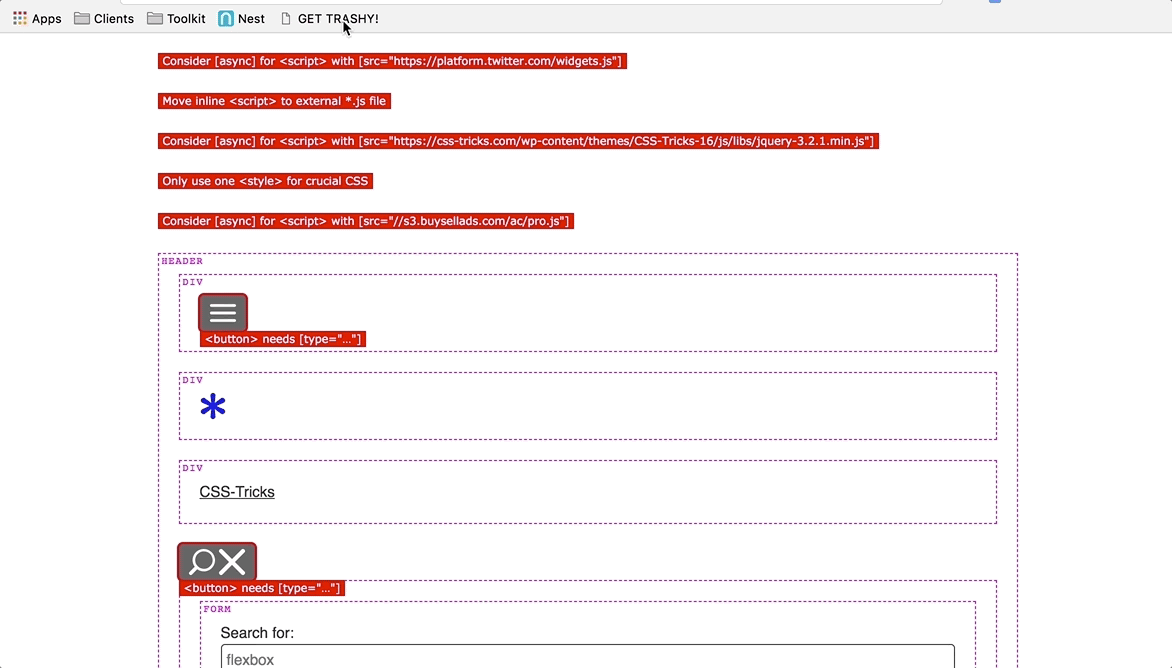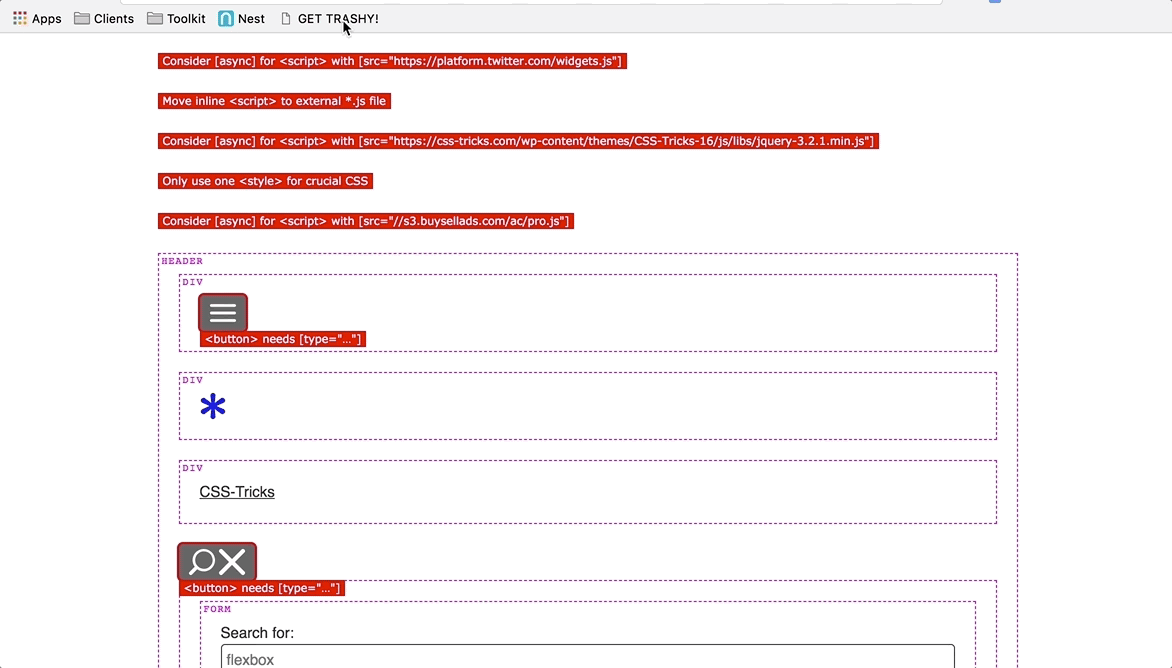
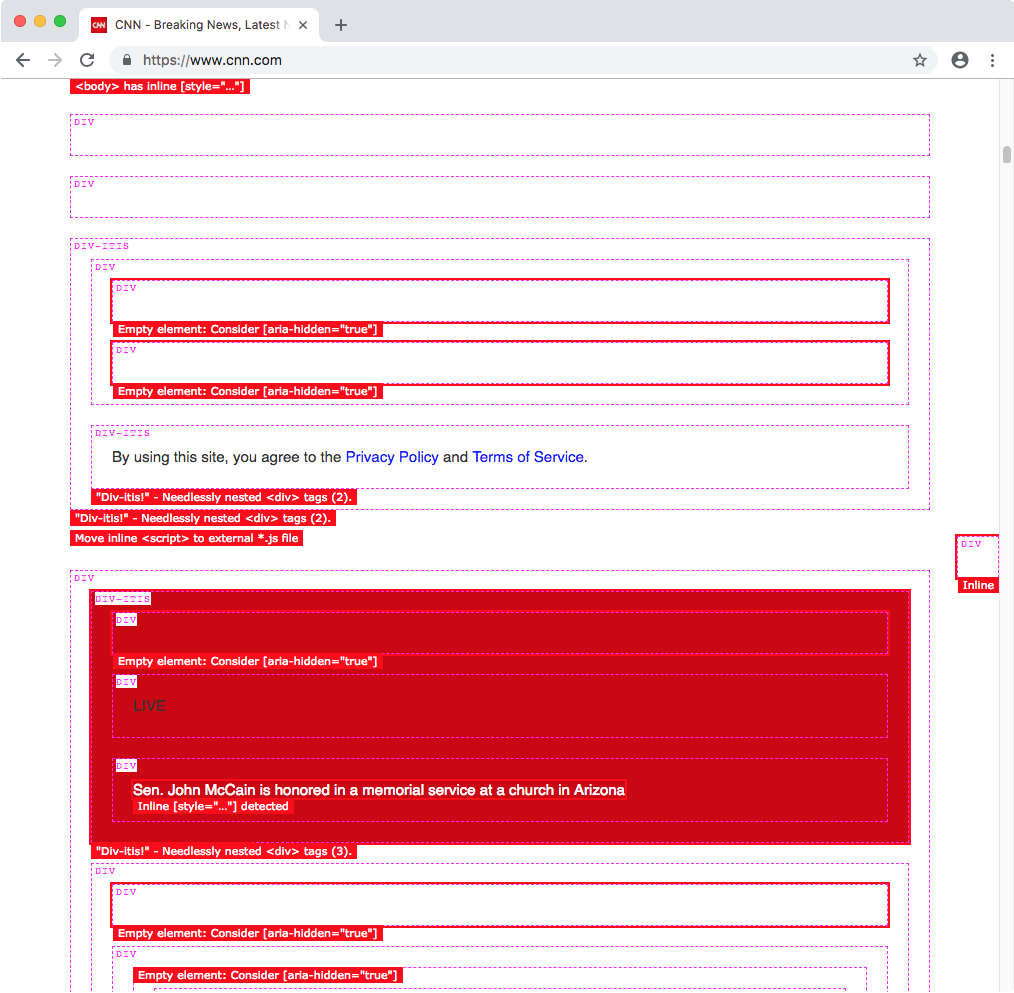






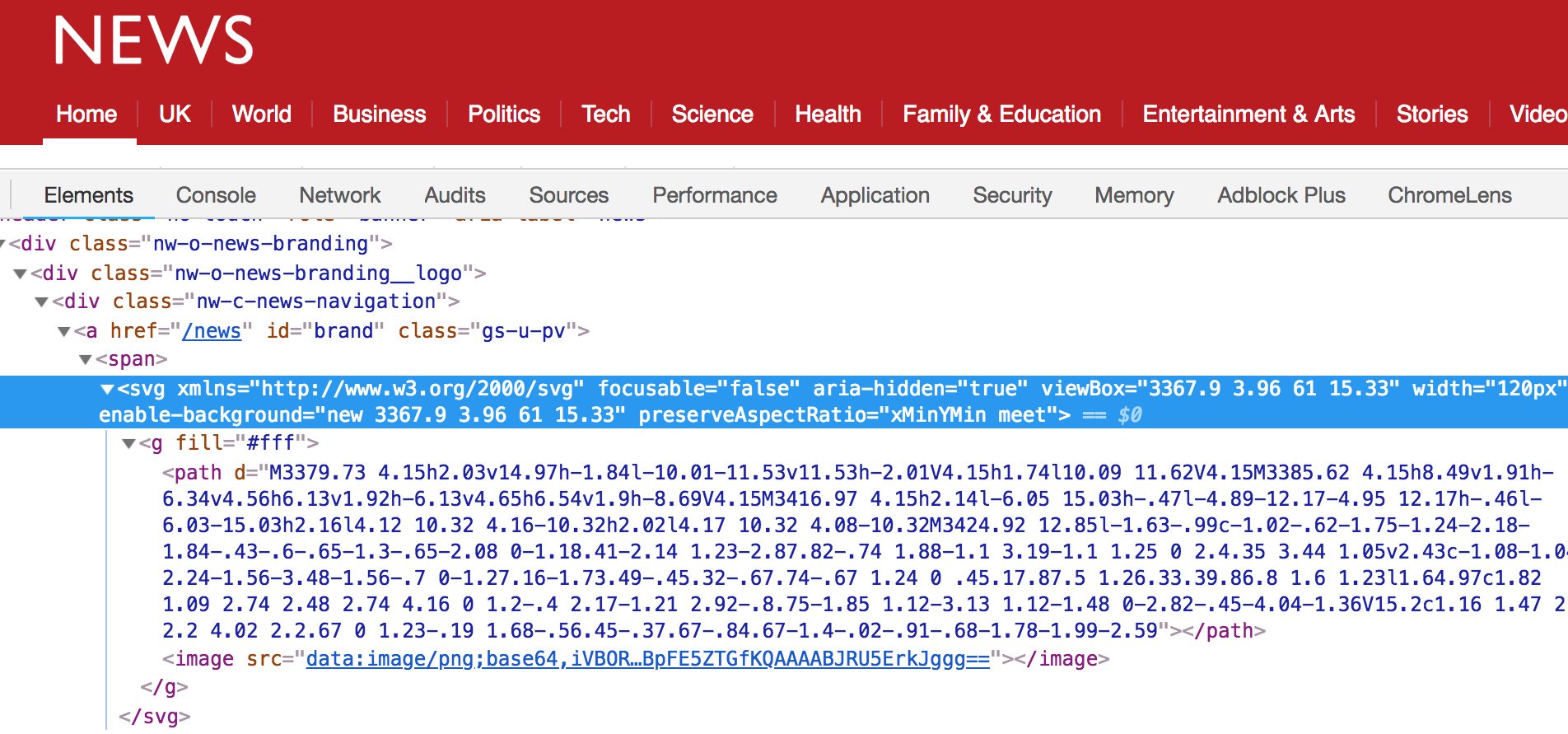{kind=link}