Introduction
The Need for Prometheus High Availability
Kubernetes adoption has grown multifold in the past few months and it is now clear that Kubernetes is the defacto for container orchestration. That being said, Prometheus is also considered an excellent choice for monitoring both containerized and non-containerized workloads. Monitoring is an essential aspect of any infrastructure, and we should make sure that our monitoring set-up is highly-available and highly-scalable in order to match the needs of an ever growing infrastructure, especially in the case of Kubernetes.
Therefore, today we will deploy a clustered Prometheus set-up which is not only resilient to node failures, but also ensures appropriate data archiving for future references. Our set-up is also very scalable, to the extent that we can span multiple Kubernetes clusters under the same monitoring umbrella.
Present Scenario
Majority of Prometheus deployments use persistent volume for pods, while Prometheus is scaled using a federated set-up. However, not all data can be aggregated using a federated mechanism, where you often need a mechanism to manage Prometheus configuration when you add additional servers.
The Solution
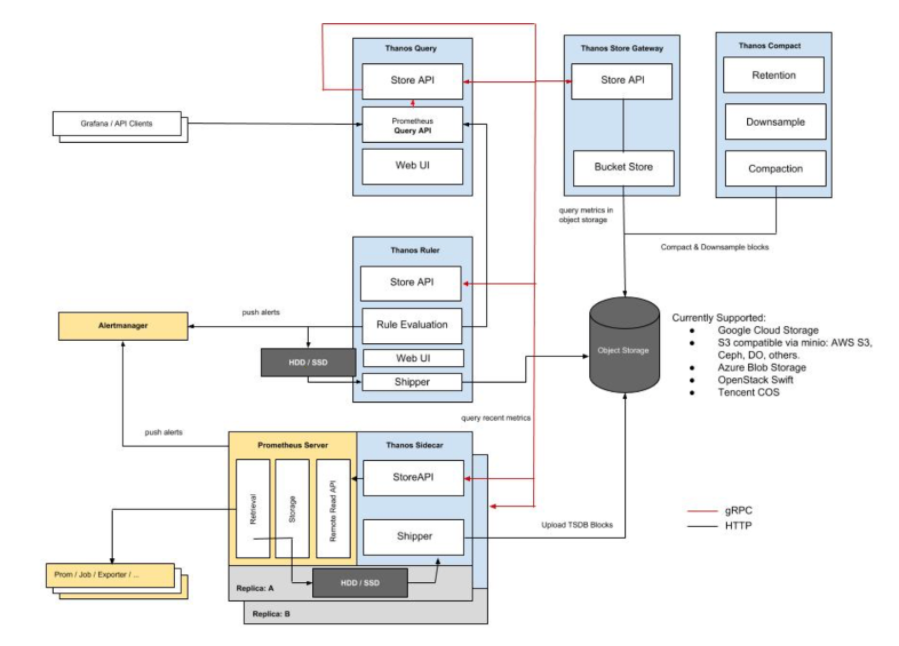
Thanos aims at solving the above problems. With the help of Thanos, we can not only multiply instances of Prometheus and de-duplicate data across them, but also archive data in a long term storage such as GCS or S3.
Implementation
Thanos Architecture