“We mustn’t use live data for testing.” This is the reason why most organizations start to look at superficial solutions to certain challenges that are ingrained in their DNA. For years, this aversion has driven the way that organizations have changed their “best” practices, struggling to wean themselves off deep-set habits.
These organizations often start with low-hanging fruit and create a capability to replace live data with either masked/obfuscated data or synthetic alternatives. They then believe that’s “job done!” It isn’t. It doesn’t tackle or even reduce many of the core challenges associated with using production in test, let alone the systemic problems that led the organization to test using production data in the first place.
No-code and low-code technologies have been making inroads for years but have never quite delivered on their promise as reliable alternatives to traditional software development for complex, business-critical applications. Then COVID-19 forced a new, expedited timeline for moving analog in-person processes to semi- or fully-automated online ones. At the same time, IT and engineering roadmaps have been thrown out the window as technical teams scramble to adjust to new distributed working conditions while juggling multiple "hair on fire" problems. As a result, operations and business teams have been left with urgent needs for new business applications and scant developer resources, creating the perfect storm for no- or low-code solutions to emerge as the savior of productivity. But decision-makers should be wary of treating these platforms as a panacea to avoid costly failures and lost time.
What Are No-Code and Low-Code Technologies?
To understand how no- and low-code solutions fill the gap between business demand for development and supply of technical resources, it is helpful to understand what those terms mean exactly. No-code platforms allow people with no technical knowledge to stand up complex, cloud-based business applications using simple, drag-and-drop tooling. Relatedly, low-code platforms are also based on the concept of abstraction through pre-built software building blocks oriented towards accelerating time to development by reducing the amount of “original” code that needs to be written in any given application. Perhaps because of their shared DNA, there is a trend towards convergence; as no-code platforms become more powerful and versatile with add-ons and application marketplaces, and low-code platforms build features to require less coding. Given this trend, we can collectively refer to these platforms as Low-code Development Platforms.
The security landscape is changing fast with new architectures and platforms emerging every day. This article attempts to explore some of the aspects of end-to-end security while building containerized applications.
With more and more organizations moving to the cloud, security is gaining paramount importance and a security-first approach has to be embedded into the DNA of organizations; security should be treated as a first-class citizen, rather than being an afterthought.
Beyond The Browser: Getting Started With Serverless WebAssembly
Beyond The Browser: Getting Started With Serverless WebAssembly
Robert Aboukhalil
Now that WebAssembly is supported by all major browsers and more than 85% of users worldwide, JavaScript is no longer the only browser language in town. If you haven’t heard, WebAssembly is a new low-level language that runs in the browser. It’s also a compilation target, which means you can compile existing programs written in languages such as C, C++, and Rust into WebAssembly, and run those programs in the browser. So far, WebAssembly has been used to port all sorts of applications to the web, including desktop applications, command-line tools, games and data science tools.
Note:For an in-depth case study of how WebAssembly can be used inside the browser to speed up web applications, check out my previous article.
WebAssembly Outside The Web?
Although most WebAssembly applications today are browser-centric, WebAssembly itself wasn’t originally designed just for the web, but really for any sandboxed environment. In fact, there’s recently been a lot of interest in exploring how WebAssembly could be useful outside the browser, as a general approach for running binaries on any OS or computer architecture, so long as there is a WebAssembly runtime that supports that system. In this article, we’ll look at how WebAssembly can be run outside the browser, in a serverless/Function-as-a-Service (FaaS) fashion.
WebAssembly For Serverless Applications
In a nutshell, serverless functions are a computing model where you hand your code to a cloud provider, and let them execute and manage scaling that code for you. For example, you can ask for your serverless function to be executed anytime you call an API endpoint, or to be driven by events, such as when a file is uploaded to your cloud bucket. While the term “serverless” may seem like a misnomer since servers are clearly involved somewhere along the way, it is serverless from our point of view since we don’t need to worry about how to manage, deploy or scale those servers.
Although these functions are usually written in languages like Python and JavaScript (Node.js), there are a number of reasons you might choose to use WebAssembly instead:
Faster Initialization Times Serverless providers that support WebAssembly (including Cloudflare and Fastly report that they can launch functions at least an order of magnitude faster than most cloud providers can with other languages. They achieve this by running tens of thousands of WebAssembly modules in the same process, which is possible because the sandboxed nature of WebAssembly makes for a more efficient way of obtaining the isolation that containers are traditionally used for.
No Rewrites Needed One of the main appeals of WebAssembly in the browser is the ability to port existing code to the web without having to rewrite everything to JavaScript. This benefit still holds true in the serverless use case because cloud providers limit which languages you can write your serverless functions in. Typically, they will support Python, Node.js, and maybe a few others, but certainly not C, C++, or Rust. By supporting WebAssembly, serverless providers can indirectly support a lot more languages.
More Lightweight When running WebAssembly in the browser, we’re relying on the end user’s computer to perform our computations. If those computations are too intensive, our users won’t be happy when their computer fan starts whirring. Running WebAssembly outside the browser gives us the speed and portability benefits of WebAssembly, while also keeping our application lightweight. On top of that, since we’re running our WebAssembly code in a more predictable environment, we can potentially perform more intensive computations.
A Concrete Example
In my previous article here on Smashing Magazine, we discussed how we sped up a web application by replacing slow JavaScript calculations with C code compiled to WebAssembly. The web app in question was fastq.bio, a tool for previewing the quality of DNA sequencing data.
As a concrete example, let’s rewrite fastq.bio as an application that makes use of serverless WebAssembly instead of running the WebAssembly inside the browser. For this article, we’ll use Cloudflare Workers, a serverless provider that supports WebAssembly and is built on top of the V8 browser engine. Another cloud provider, Fastly, is working on a similar offering, but based on their Lucet runtime.
First, let’s write some Rust code to analyze the data quality of DNA sequencing data. For convenience, we can leverage the Rust-Bio bioinformatics library to handle parsing the input data, and the wasm-bindgen library to help us compile our Rust code to WebAssembly.
Here’s a snippet of the code that reads in DNA sequencing data and outputs a JSON with a summary of quality metrics:
// Import packages
extern crate wasm_bindgen;
use bio::seq_analysis::gc;
use bio::io::fastq;
...
// This "wasm_bindgen" tag lets us denote the functions
// we want to expose in our WebAssembly module
#[wasm_bindgen]
pub fn fastq_metrics(seq: String) -> String
{
...
// Loop through lines in the file
let reader = fastq::Reader::new(seq.as_bytes());
for result in reader.records() {
let record = result.unwrap();
let sequence = record.seq();
// Calculate simple statistics on each record
n_reads += 1.0;
let read_length = sequence.len();
let read_gc = gc::gc_content(sequence);
// We want to draw histograms of these values
// so we store their values for later plotting
hist_gc.push(read_gc * 100.0);
hist_len.push(read_length);
...
}
// Return statistics as a JSON blob
json!({
"n": n_reads,
"hist": {
"gc": hist_gc,
"len": hist_len
},
...
}).to_string()
}
We then used Cloudflare’s wrangler command-line tool to do the heavy lifting of compiling to WebAssembly and deploying to the cloud. Once done, we are given an API endpoint that takes sequencing data as input and returns a JSON with data quality metrics. We can now integrate that API into our application.
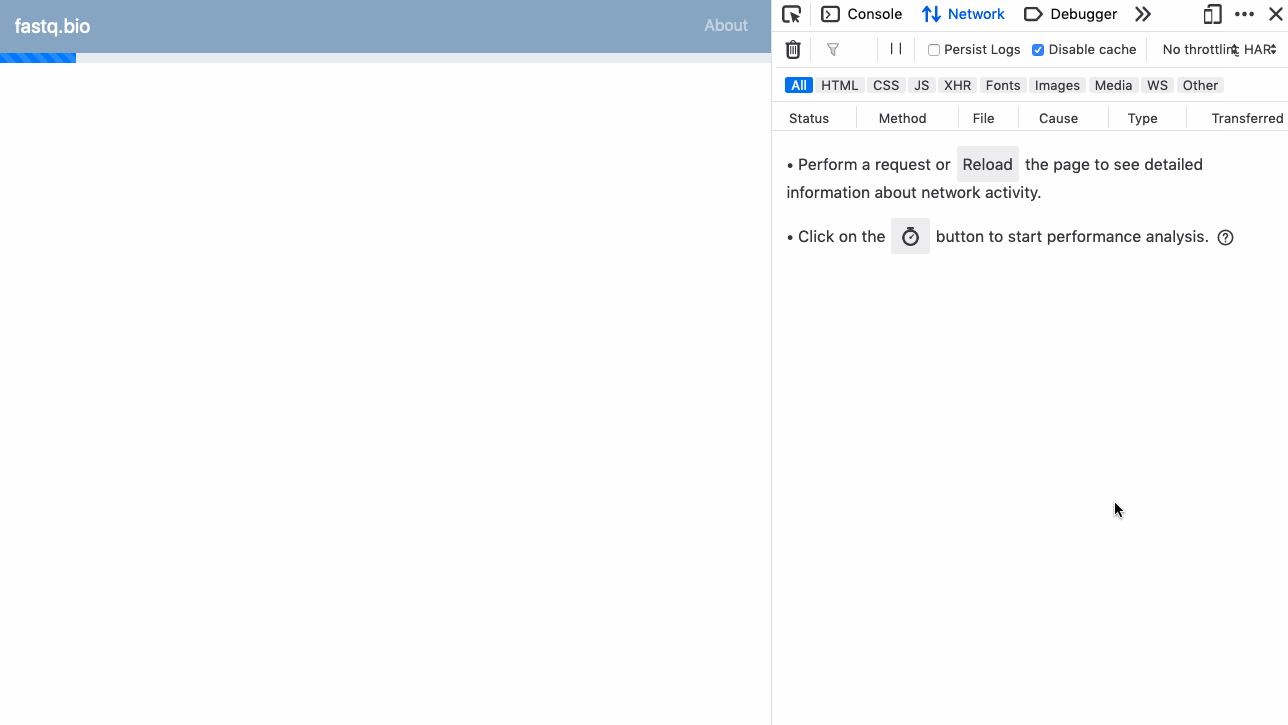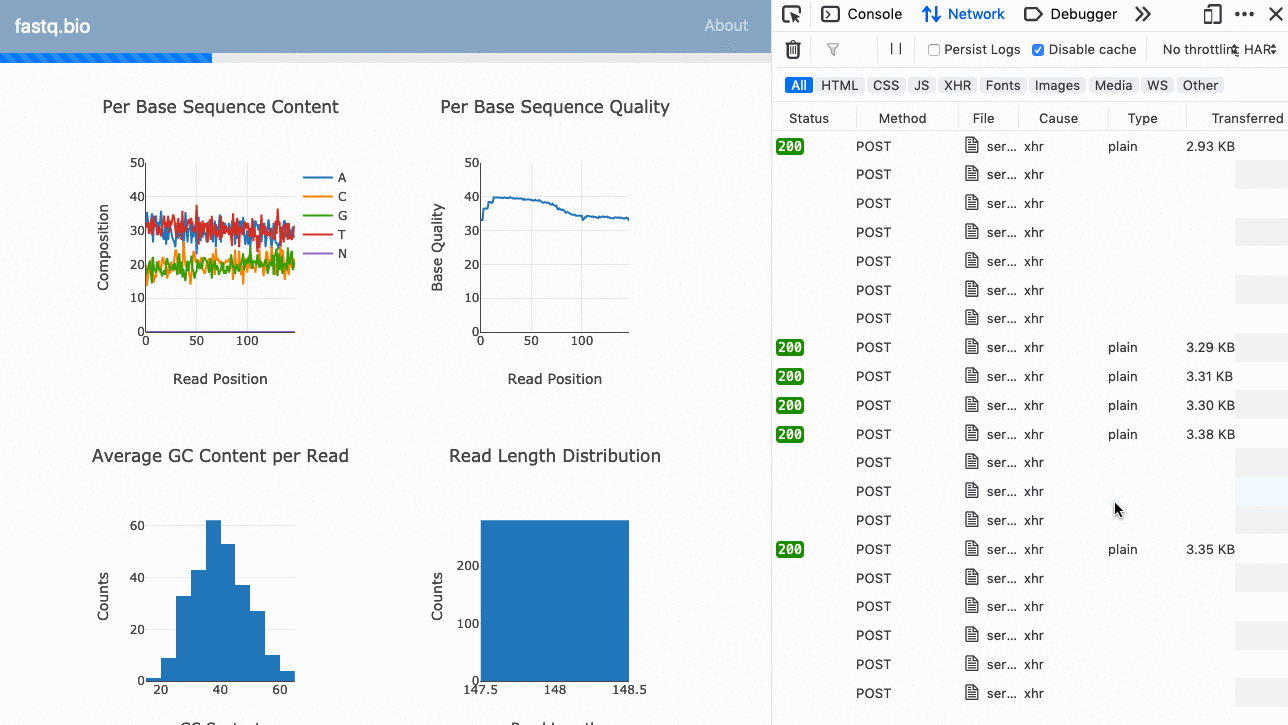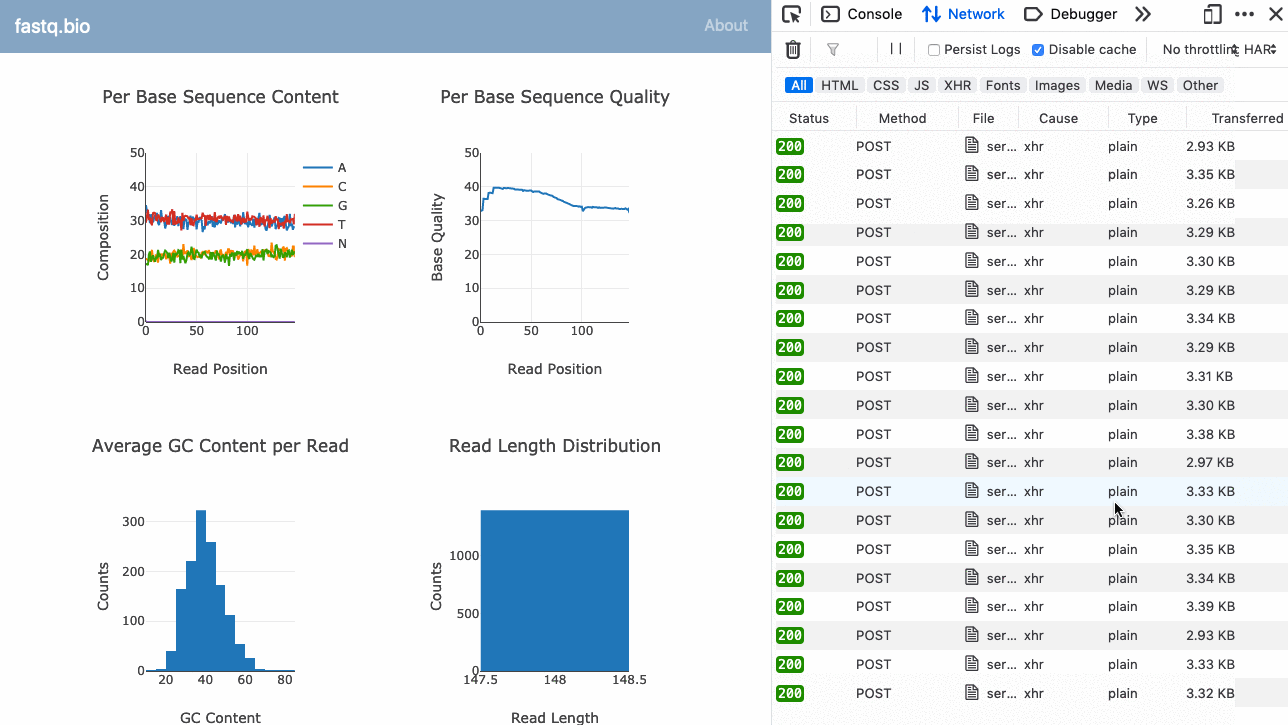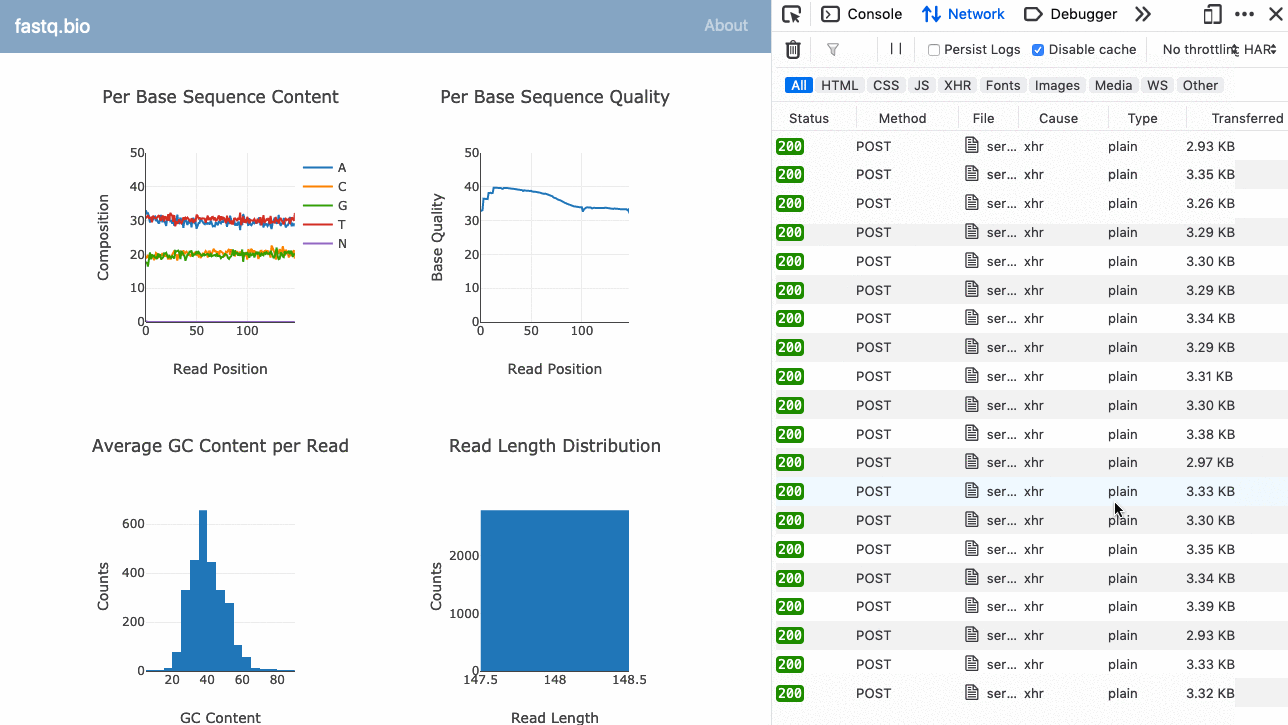
Here’s a GIF of the application in action:
Instead of running the analysis directly in the browser, the serverless version of our application makes several POST requests in parallel to our serverless function (see right sidebar), and updates the plots each time it returns more data. (Large preview)
The full code is available on GitHub (open-source).
Putting It All In Context
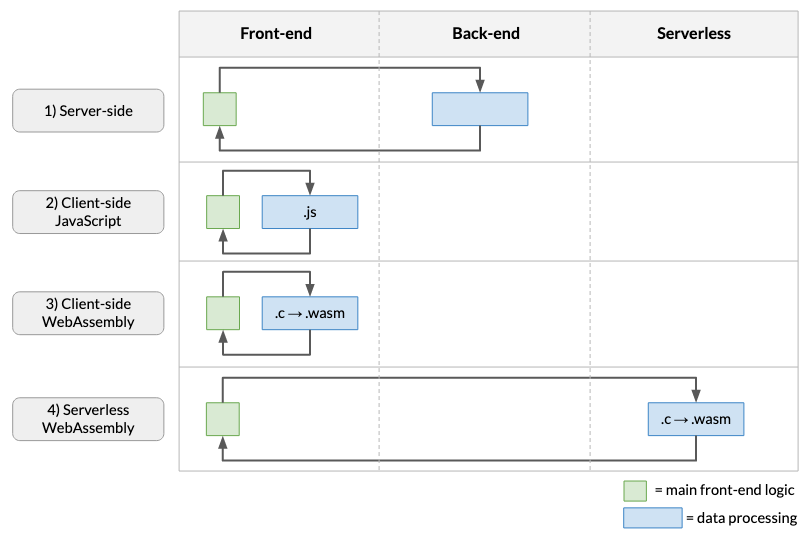
To put the serverless WebAssembly approach in context, let’s consider four main ways in which we can build data processing web applications (i.e. web apps where we perform analysis on data provided by the user):
Four different architectural choices that we can take for apps that process data. (Large preview)
As shown above, the data processing can be done in several places:
Server-Side
This is the approach taken by most web applications, where API calls made in the front-end launch data processing on the back-end.
Client-Side JavaScript
In this approach, the data processing code is written in JavaScript and runs in the browser. The downside is that your performance will take a hit, and if your original code wasn’t in JavaScript, you’ll need to rewrite it from scratch!
Client-Side WebAssembly
This involves compiling data analysis code to WebAssembly and running it in the browser. If the analysis code was written in languages like C, C++ or Rust (as is often the case in my field of genomics), this obviates the need to rewrite complex algorithms in JavaScript. It also provides the potential for speeding up our application (e.g. as discussed in a previous article).
Serverless WebAssembly
This involves running the compiled WebAssembly on the cloud, using a FaaS kind of model (e.g. this article).
So why would you choose the serverless approach over the others? For one thing, compared to the first approach, it has the benefits that come with using WebAssembly, especially the ability to port existing code without having to rewrite it to JavaScript. Compared to the third approach, serverless WebAssembly also means our app is more lightweight since we don’t use the user’s resources for number crunching. In particular, if the computations are fairly involved or if the data is already in the cloud, this approach makes more sense.
On the other hand, however, the app now needs to make network connections, so the application will likely be slower. Furthermore, depending on the scale of the computation and whether it is amenable to be broken down into smaller analysis pieces, this approach might not be suitable due to limitations imposed by serverless cloud providers on runtime, CPU, and RAM utilization.
Conclusion
As we saw, it is now possible to run WebAssembly code in a serverless fashion and reap the benefits of both WebAssembly (portability and speed) and those of function-as-a-service architectures (auto-scaling and per-per-use pricing). Certain types of applications — such as data analysis and image processing, to name a few — can greatly benefit from such an approach. Though the runtime suffers because of the additional round-trips to the network, this approach does allow us to process more data at a time and not put a drain on users’ resources.
How We Used WebAssembly To Speed Up Our Web App By 20X (Case Study)
How We Used WebAssembly To Speed Up Our Web App By 20X (Case Study)
Robert Aboukhalil
If you haven’t heard, here’s the TL;DR: WebAssembly is a new language that runs in the browser alongside JavaScript. Yes, that’s right. JavaScript is no longer the only language that runs in the browser!
But beyond just being “not JavaScript”, its distinguishing factor is that you can compile code from languages such as C/C++/Rust (and more!) to WebAssembly and run them in the browser. Because WebAssembly is statically typed, uses a linear memory, and is stored in a compact binary format, it is also very fast, and could eventually allow us to run code at “near-native” speeds, i.e. at speeds close to what you’d get by running the binary on the command line. The ability to leverage existing tools and libraries for use in the browser and the associated potential for speedup, are two reasons that make WebAssembly so compelling for the web.
So far, WebAssembly has been used for all sorts of applications, ranging from gaming (e.g. Doom 3), to porting desktop applications to the web (e.g. Autocad and Figma). It is even used outside the browser, for example as an efficient and flexible language for serverless computing.
This article is a case study on using WebAssembly to speed up a data analysis web tool. To that end, we’ll take an existing tool written in C that performs the same computations, compile it to WebAssembly, and use it to replace slow JavaScript calculations.
Note: This article delves into some advanced topics such as compiling C code, but don’t worry if you don’t have experience with that; you will still be able to follow along and get a sense for what is possible with WebAssembly.
Background
The web app we will work with is fastq.bio, an interactive web tool that provides scientists with a quick preview of the quality of their DNA sequencing data; sequencing is the process by which we read the “letters” (i.e. nucleotides) in a DNA sample.
We won’t go into the details of the calculations, but in a nutshell, the plots above provide scientists a sense for how well the sequencing went and are used to identify data quality issues at a glance.
Although there are dozens of command line tools available to generate such quality control reports, the goal of fastq.bio is to give an interactive preview of data quality without leaving the browser. This is especially useful for scientists who are not comfortable with the command line.
The input to the app is a plain-text file that is output by the sequencing instrument and contains a list of DNA sequences and a quality score for each nucleotide in the DNA sequences. The format of that file is known as “FASTQ”, hence the name fastq.bio.
If you’re curious about the FASTQ format (not necessary to understand this article), check out the Wikipedia page for FASTQ. (Warning: The FASTQ file format is known in the field to induce facepalms.)
fastq.bio: The JavaScript Implementation
In the original version of fastq.bio, the user starts by selecting a FASTQ file from their computer. With the File object, the app reads a small chunk of data starting at a random byte position (using the FileReader API). In that chunk of data, we use JavaScript to perform basic string manipulations and calculate relevant metrics. One such metric helps us track how many A’s, C’s, G’s and T’s we typically see at each position along a DNA fragment.
Once the metrics are calculated for that chunk of data, we plot the results interactively with Plotly.js, and move on to the next chunk in the file. The reason for processing the file in small chunks is simply to improve the user experience: processing the whole file at once would take too long, because FASTQ files are generally in the hundreds of gigabytes. We found that a chunk size between 0.5 MB and 1 MB would make the application more seamless and would return information to the user more quickly, but this number will vary depending on the details of your application and how heavy the computations are.
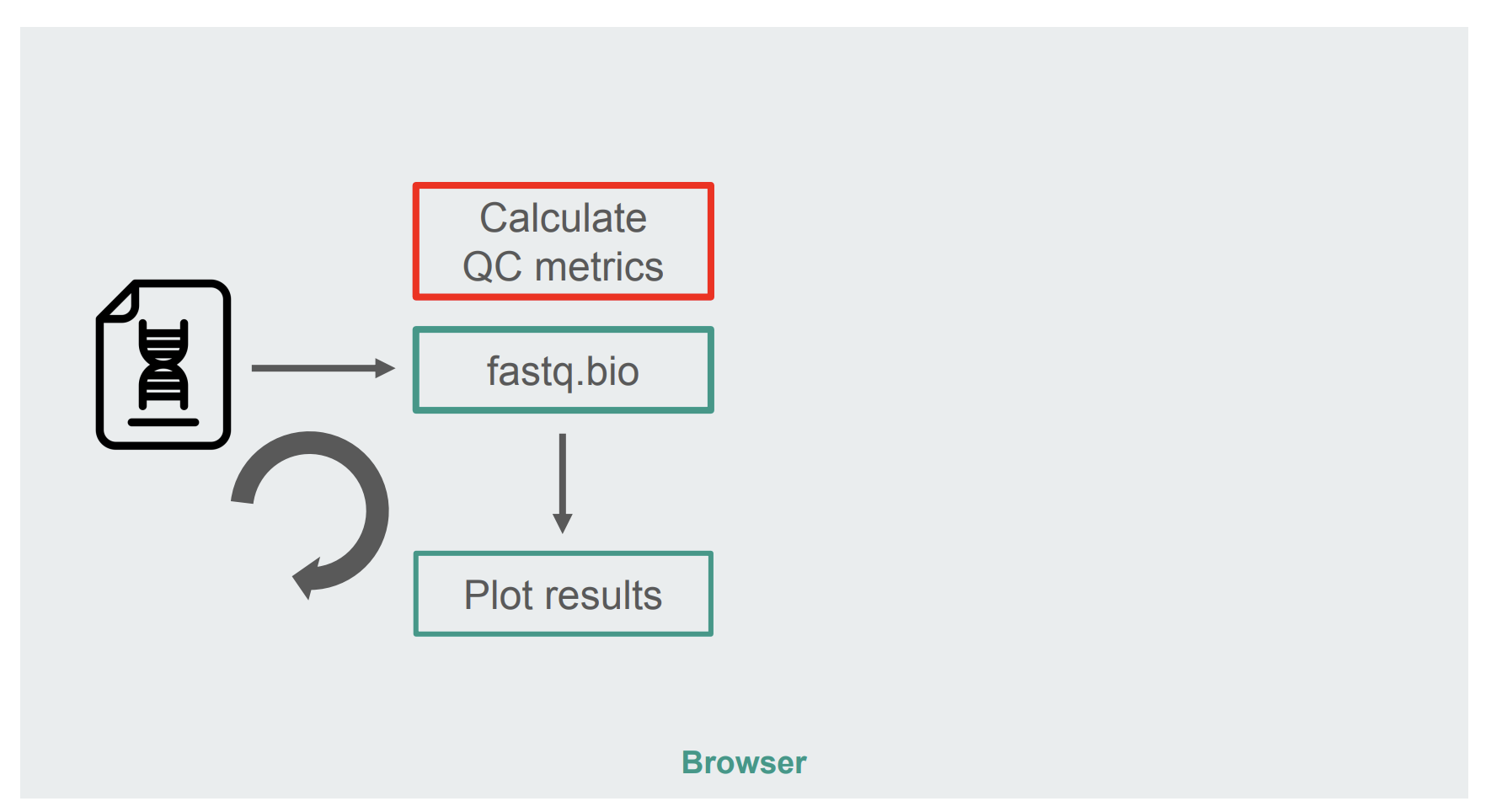
The architecture of our original JavaScript implementation was fairly straightforward:
The architecture of the JavaScript implementation of fastq.bio (Large preview)
The box in red is where we do the string manipulations to generate the metrics. That box is the more compute-intensive part of the application, which naturally made it a good candidate for runtime optimization with WebAssembly.
fastq.bio: The WebAssembly Implementation
To explore whether we could leverage WebAssembly to speed up our web app, we searched for an off-the-shelf tool that calculates QC metrics on FASTQ files. Specifically, we sought a tool written in C/C++/Rust so that it was amenable to porting to WebAssembly, and one that was already validated and trusted by the scientific community.
After some research, we decided to go with seqtk, a commonly-used, open-source tool written in C that can help us evaluate the quality of sequencing data (and is more generally used to manipulate those data files).
Before we compile to WebAssembly, let’s first consider how we would normally compile seqtk to binary to run it on the command line. According to the Makefile, this is the gcc incantation you need:
On the other hand, to compile seqtk to WebAssembly, we can use the Emscripten toolchain, which provides drop-in replacements for existing build tools to make working in WebAssembly easier. If you don’t have Emscripten installed, you can download a docker image we prepared on Dockerhub that has the tools you’ll need (you can also install it from scratch, but that usually takes a while):
As you can see, the differences between compiling to binary and WebAssembly are minimal:
Instead of the output being the binary file seqtk, we ask Emscripten to generate a .wasm and a .js that handles instantiation of our WebAssembly module
To support the zlib library, we use the flag USE_ZLIB; zlib is so common that it’s already been ported to WebAssembly, and Emscripten will include it for us in our project
We enable Emscripten’s virtual file system, which is a POSIX-like file system (source code here), except it runs in RAM within the browser and disappears when you refresh the page (unless you save its state in the browser using IndexedDB, but that’s for another article).
Why a virtual file system? To answer that, let’s compare how we would call seqtk on the command line vs. using JavaScript to call the compiled WebAssembly module:
# On the command line
$ ./seqtk fqchk data.fastq
# In the browser console
> Module.callMain(["fqchk", "data.fastq"])
Having access to a virtual file system is powerful because it means we don’t have to rewrite seqtk to handle string inputs instead of file paths. We can mount a chunk of data as the file data.fastq on the virtual file system and simply call seqtk’s main() function on it.
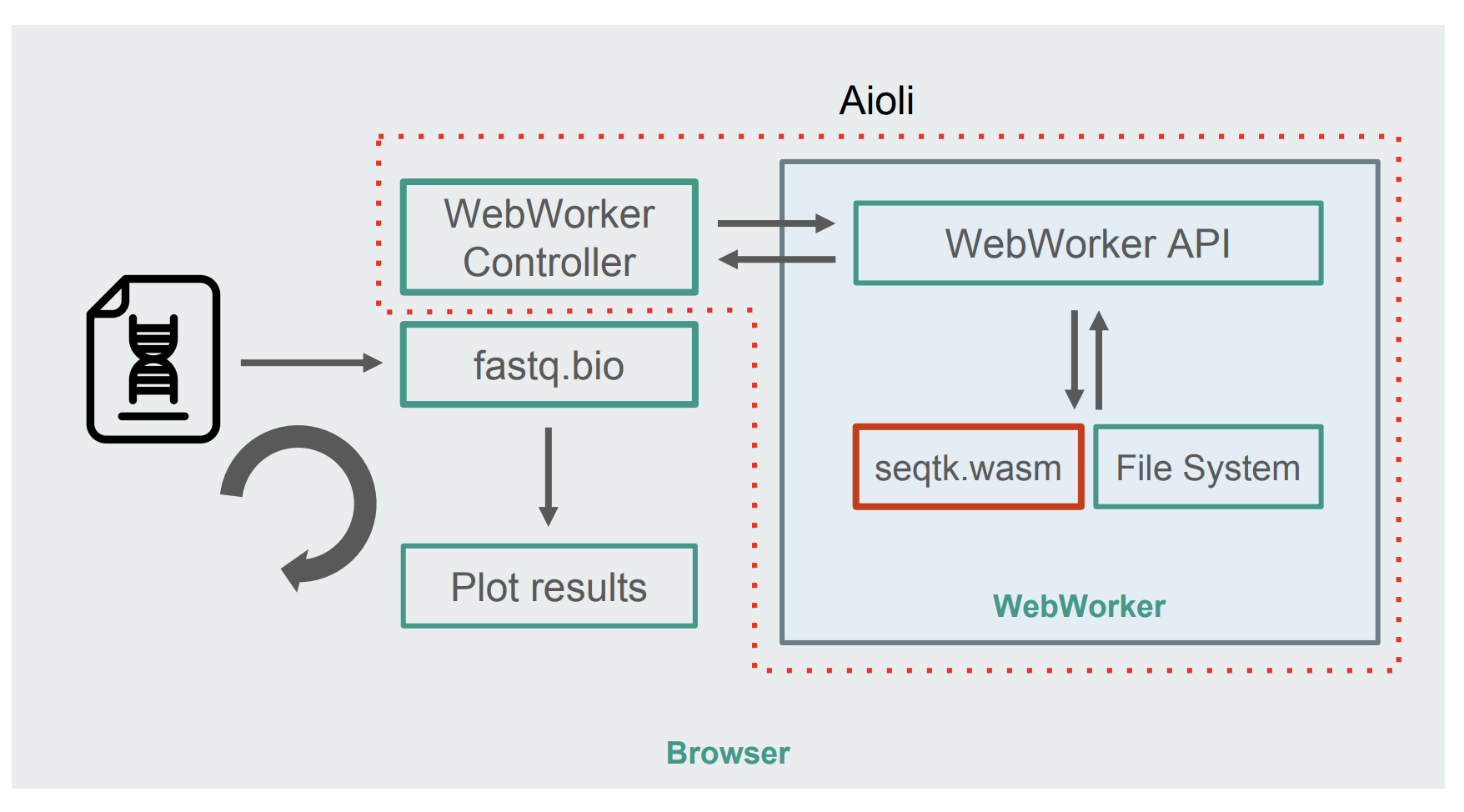
With seqtk compiled to WebAssembly, here’s the new fastq.bio architecture:
Architecture of the WebAssembly + WebWorkers implementation of fastq.bio (Large preview)
As shown in the diagram, instead of running the calculations in the browser’s main thread, we make use of WebWorkers, which allow us to run our calculations in a background thread, and avoid negatively affecting the responsiveness of the browser. Specifically, the WebWorker controller launches the Worker and manages communication with the main thread. On the Worker’s side, an API executes the requests it receives.
We can then ask the Worker to run a seqtk command on the file we just mounted. When seqtk finishes running, the Worker sends the result back to the main thread via a Promise. Once it receives the message, the main thread uses the resulting output to update the charts. Similar to the JavaScript version, we process the files in chunks and update the visualizations at each iteration.
Performance Optimization
To evaluate whether using WebAssembly did any good, we compare the JavaScript and WebAssembly implementations using the metric of how many reads we can process per second. We ignore the time it takes for generating interactive graphs, since both implementations use JavaScript for that purpose.
Out of the box, we already see a ~9X speedup:
Using WebAssembly, we see a 9X speedup compared to our original JavaScript implementation. (Large preview)
This is already very good, given that it was relatively easy to achieve (that is once you understand WebAssembly!).
Next, we noticed that although seqtk outputs a lot of generally useful QC metrics, many of these metrics are not actually used or graphed by our app. By removing some of the output for the metrics we didn’t need, we were able to see an even greater speedup of 13X:
Removing unnecessary outputs gives us further performance improvement. (Large preview)
This again is a great improvement given how easy it was to achieve—by literally commenting out printf statements that were not needed.
Finally, there is one more improvement we looked into. So far, the way fastq.bio obtains the metrics of interest is by calling two different C functions, each of which calculates a different set of metrics. Specifically, one function returns information in the form of a histogram (i.e. a list of values that we bin into ranges), whereas the other function returns information as a function of DNA sequence position. Unfortunately, this means that the same chunk of file is read twice, which is unnecessary.
So we merged the code for the two functions into one—albeit messy—function (without even having to brush up on my C!). Since the two outputs have different numbers of columns, we did some wrangling on the JavaScript side to disentangle the two. But it was worth it: doing so allowed us to achieve a >20X speedup!
Finally, wrangling the code such that we only read through each file chunk once gives us >20X performance improvement. (Large preview)
A Word Of Caution
Now would be a good time for a caveat. Don’t expect to always get a 20X speedup when you use WebAssembly. You might only get a 2X speedup or a 20% speedup. Or you may get a slow down if you load very large files in memory, or require a lot of communication between the WebAssembly and the JavaScript.
Conclusion
In short, we’ve seen that replacing slow JavaScript computations with calls to compiled WebAssembly can lead to significant speedups. Since the code needed for those computations already existed in C, we got the added benefit of reusing a trusted tool. As we also touched upon, WebAssembly won’t always be the right tool for the job (gasp!), so use it wisely.
Further Reading
“Level Up With WebAssembly,” Robert Aboukhalil A practical guide to building WebAssembly applications.
Aioli (on GitHub) A framework for building fast genomics web tools.
fastq.bio source code (on GitHub) An interactive web tool for quality control of DNA sequencing data.