

It’s been five years since I first presented the idea of the Jamstack architecture at SmashingConf in San Francisco 2016, a talk inspired by many conversations with colleagues and friends in the industry. At that point, the idea of fundamentally decoupling the front-end web layer from the back-end business logic layer was only an early trend, and not yet a named architectural approach.
<!-- 
Static site generators were emerging as a real option for building larger content-driven sites, but the whole ecosystem around them was nascent, and the main generators were pure open-source tools with no commercial presence. Single Page Applications were the basis of some large-scale web apps, like Gmail, but the typical approach to building them was still backend-centric.
Fast forward to 2020, Jamstack hit the mainstream, and we saw millions of developers and major brands like Unilever, Nike, and PayPal embrace the architecture. Vital initiatives like the Covid Tracking Project were able to scale from 0 to 2 million API requests on the Jamstack. Frameworks like Nuxt became commercial businesses, and we celebrated large public companies like Microsoft and Cloudflare as they launched early Jamstack offerings.
As the commercial space has heated up and the developer community has grown, there’s also been more noise, and we’re even starting to test the boundaries of Jamstack’s best practices. It feels like the right time to both revisit the original vision some of us had five years ago, and look ahead at what the changes in the technological landscape will mean for the future of the Jamstack architecture and the web.
Let’s start out by quickly revisiting the core principles that have made the architecture prove popular.
Compiling The UI
In the Jamstack architecture, the UI is compiled. The goal is to do the right work at the right times — with a preference for doing as much work as possible ahead of time. Many times, the entire site can be prerendered, perhaps not even requiring a backend once deployed.
Decoupled Frontends
Decoupling the frontend from back-end services and platforms enforces a clear contract for how your UI communicates with the rest of the system. This defaults to simplicity: your frontend has a limited contact surface with anything outside itself, making it less complicated to understand how external changes will affect its operation.
Pulling Data As Needed
Of course, not everything can be prerendered, and the Jamstack architecture is capable of delivering dynamic, personalized web apps as well as more globally consistent content. Requesting data from the frontend can power some rich and dynamic applications.
A good example is the frontend of our own Netlify UI, which is itself a Jamstack application built and run on Netlify. We pre-compile an app shell, then use asynchronous requests to hit our API to load data about our users and their sites. Whether you’re using REST, GraphQL, or WebSockets, if you’re precompiling as much of the UI as possible and loading data to give your users a dynamic, customized experience, then you’re shipping the Jamstack architecture.
Jamstack In 2021 And Beyond
There’s more innovation happening across the Jamstack ecosystem than ever before. You can see a rapid evolution of the back-end services, developer tooling, and client-side technologies that are combining to enable development teams to build experiences for the web that would have seemed out of reach only a couple of years ago.
I want to point to three trends I see shaping up for Jamstack developers in the near future:
1. Distributed Persistent Rendering (DPR)
More than anything, Jamstack’s inherent simplicity has made the process of building and deploying web applications much easier to reason about. Code and content updates can be pre-rendered as clean, atomic deployments and pushed right to the edge, creating strong guarantees around reliability and performance without the need to manage complex infrastructure.
But pre-rendering a larger website may also mean waiting several minutes each time there’s a new deployment. That’s why I think we are seeing so much innovation happening to make builds smarter and faster — especially for larger sites and web apps. Take for example the raw speed of esbuild, the new “extremely fast JavaScript compiler.” A production bundle that may take Parcel or Webpack over a minute to compile can be completed by esbuild in under a second. And build tools like Vite and Snowpack lean on native ES modules to make local development feel nearly instantaneous.
In the React ecosystem, some newer frameworks like Remix or Blitz are starting to lean more on the “run everything on a server” approach we’ve all known in the past. There’s a risk of bringing back much of the complexity we’ve worked to escape. Layers of caching can help make server-side apps more performant, but developers lose the guarantees of atomic deployments that make Jamstack apps easy to reason about.
Blitz seems to be moving the monolith into the frontend. This can make full-stack apps runnable on typical Jamstack platforms, but without any clear decoupling between the web experience layer and the back-end business logic layer. I think decoupling the frontend from the backend is fundamental to the Jamstack approach and responsible for unlocking so many of its benefits.
What I see gaining real momentum are the “hybrid” frameworks like Next.js, Nuxt.js, and SvelteKit that allow developers to seamlessly mix pages pre-rendered at build time with other routes that are rendered via serverless functions. The challenge is that serverless functions (while certainly scalable) have their own set of performance implications.
Ultimately, I see the community moving towards an extremely powerful trio that provides Jamstack developers request-level control over the performance profile of any site or application:
- Delivering pages entirely pre-rendered at build time,
- Delivering pages dynamically via serverless functions, or
- Building pages on-demand that then persist as static CDN assets.
Next.js has done quite a bit of work on a concept they call Incremental Static Regeneration. The idea is to ensure high-performance pages by paring serverless functions with different caching strategies like Stale While Revalidate. While the idea of distributing some of the builds to an on-demand approach that still includes strong caching guarantees is a powerful technique, there’s a risk to breaking atomic deploys in this particular implementation, and the benefits are locked into a singular framework, and in some cases, a provider.
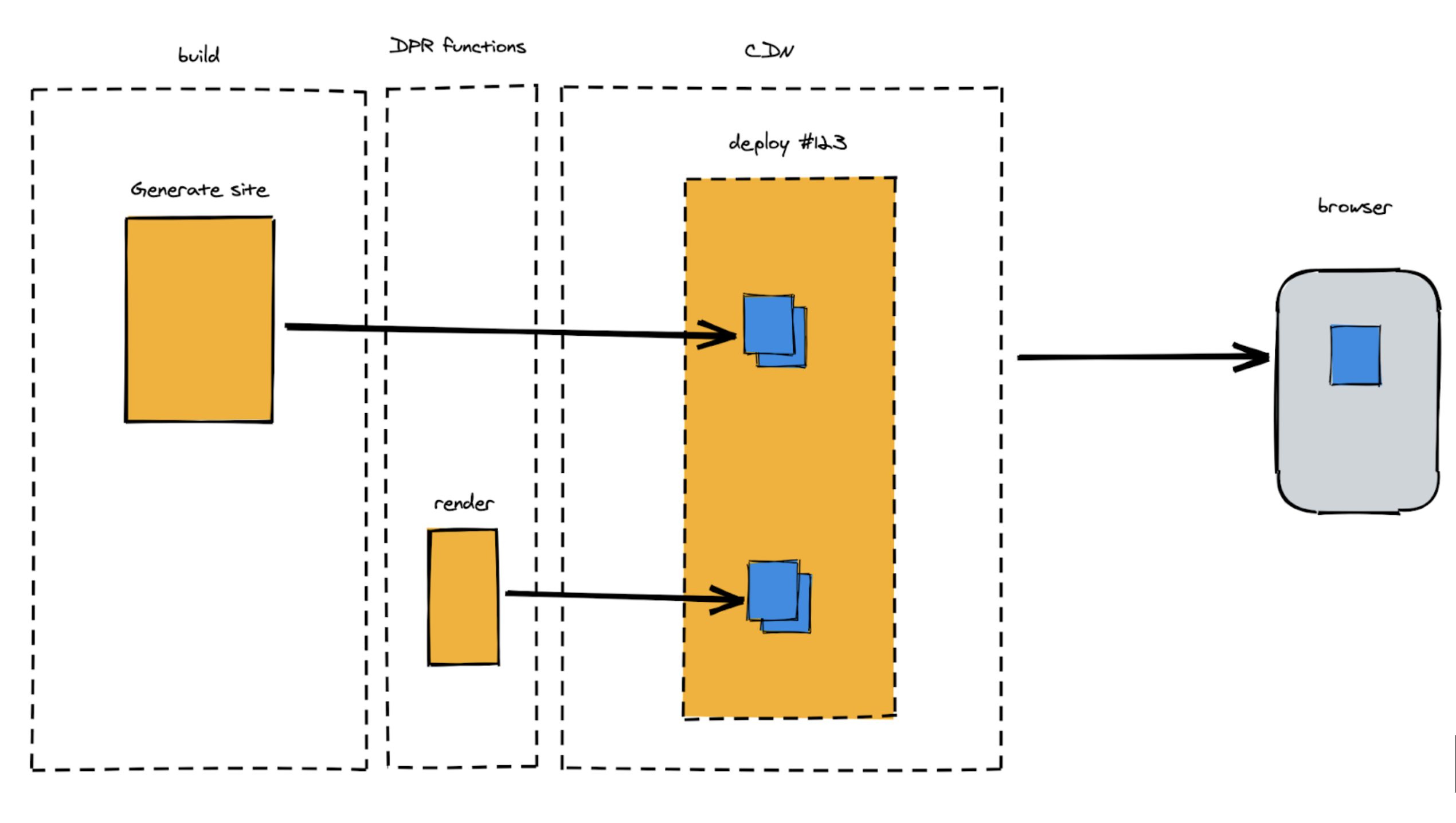
At Netlify, we see a lot of promise in the idea of allowing developers to render critical pages at build time, while deferring other pages (like older blog posts, for example) to be built only when and if they are requested. We’re calling the approach Distributed Persistent Rendering or DPR. It’s an architecture for incremental builds that can be compatible across almost every framework and Jamstack site generator, from 11ty to Nuxt to Next.js.
DPR will dramatically reduce upfront build times for larger sites, solving a core criticism of static site generation. On Jamstack.org, we’ve opened a Request For Comments to involve the entire community in our efforts to give developers more options for how pages are rendered while adhering closely to the principles that have made Jamstack so popular. By giving this architecture a name and refining it with community input, we can help Jamstack developers build patterns around it — regardless of the framework.
2. Streaming Updates From The Data Layer
If you develop web applications, you’ve likely followed the evolution of state management libraries as developers have built more and more complex web interfaces using tools like React, Vue, and Svelte. But state management has largely been an in-browser and in-memory concern. Each browser tab essentially has its own state, but can be quite complex to connect that local browser state of your application back to the data services that power it.
Luckily, this is improving as more and more services now support real-time data subscriptions. Hasura, OneGraph, and Supabase all offer this capability and I only expect to see wider adoption across all providers as the underlying data stores are cached and distributed to the edge for fast global performance. Take Twillio’s expanding APIs: they now not only offer streaming video but also streaming “data tracks,” which can be used to create complex collaboration apps that stay continually synchronized across participants.
Finally, new providers are emerging that aggregate data across back-end services. Whether or not you use GraphQL as a query language, it’s really compelling to imagine the power of connecting your UI to a single, standard stream of updates from multiple underlying APIs.
3. Developer Collaboration Goes Mainstream
The Jamstack is built on a Git workflow — an approach that scales really well to larger development teams. But going forward, we’ll start to see how these traditionally developer-focused tools will expand to involve everyone across the company: developers, sure, but also writers, editors, designers, and SEO experts.
When you think of collaboration, you tend to think of synchronous edits—the multiple cursors that fly around a Google Doc, for example. We are seeing that style of live collaboration come to CMS tools like Sanity and design tools like Figma. But so much work often happens asynchronously, and non-developers traditionally haven’t enjoyed the powerful tools that developers use to seamlessly branch, stage, and merge changes with collaborative discussion attached to each pull request.
Early on in the Jamstack, some clever git-based CMS tools emerged to help non-developers manage content like code — perhaps without even knowing that each change they made was being git-committed just like a developer working from the terminal. We’re now starting to see new tools tackle visual page edits in a way that remains compatible with popular Jamstack site generators like Gatsby and Next.js. All of this lowers the bar to collaboration for non-developers and we’ll only see that trend accelerate.
And it’s not just non-developers joining in on the collaboration: deep integrations between tools are bringing more automated contributions into our dev, build, and deploy workflows. Just browse the comment history on a GitHub pull request to see how many tools are now integrated to run automated tests and catch errors before they are deployed.
Updates to Netlify’s docs, for example, aren’t just linted against our code standards, they are also linted against our content standards, ensuring we stay consistent with our style guide for vocabulary, language, and phrasing. Teams can also now easily tie performance budgets and SEO standards to each deployment, again with alerts and logs tied directly to GitHub issues.
I would expect to see those sorts of integrations explode in the coming year, allowing a git-based workflow to underpin not just code changes, but also content, data, design assets — you name it. Friendly interfaces into these Git workflows will allow more contributors to comment, commit, and collaborate and bring developer productivity tooling further into the mainstream.
Enabling Scale And Dynamic Use Cases
While Jamstack stays true to the core concepts of decoupling the frontend from the backend and maintaining immutable and atomic deploys, new build strategies and compute primitives have the potential to unlock extremely large-scale sites and dynamic, real-time web applications.
Jamstack developers — and now entire web teams, marketers, and product managers — have much to look forward to in this space.
Further Reading And References
- “How The COVID Tracking Project Scaled From 0 To 2M API Requests In 3 Months,” Netlify, Netlify Blog
- “Incremental Static Regeneration: Its Benefits And Its Flaws,” Cassidy Williams, Netlify Blog
- “Distributed Persistent Rendering: A New Jamstack Approach For Faster Builds,” Matt Biilmann, Netlify Blog
- Glossary, Jamstack.org













































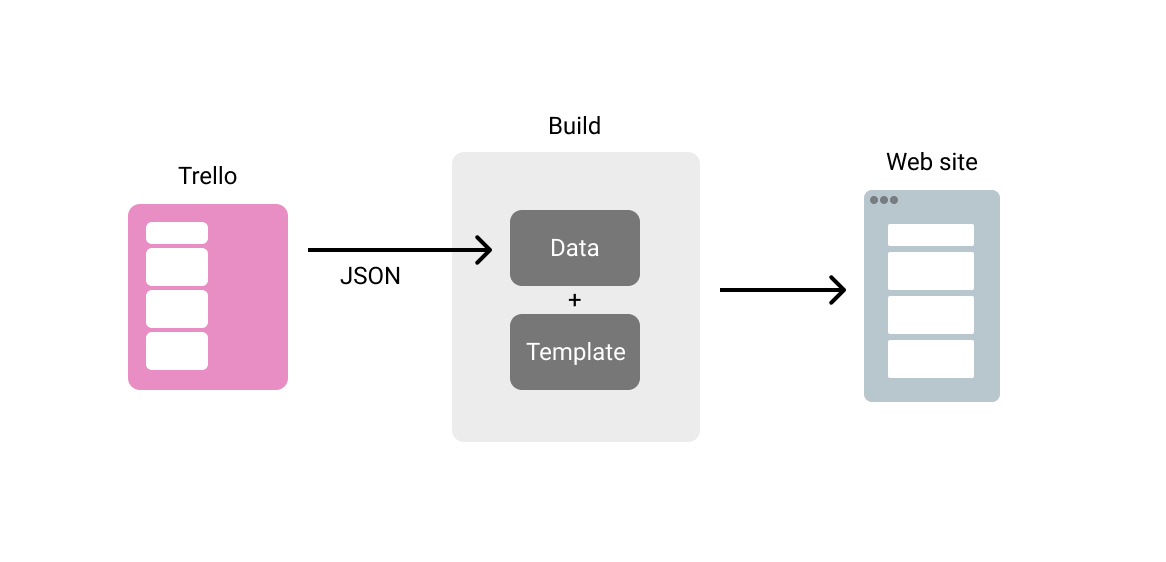
 It’s a stroke of luck for mischief makers on the internet if they can find a way to harm WordPress websites. With just one trick up their sleeves, they can take a shot at almost 30% of the websites on the internet. That’s the downside of WordPress being the most popular CMS. As website owners, […]
It’s a stroke of luck for mischief makers on the internet if they can find a way to harm WordPress websites. With just one trick up their sleeves, they can take a shot at almost 30% of the websites on the internet. That’s the downside of WordPress being the most popular CMS. As website owners, […]



