The formula is the heart of an Excel file. And of course, we all want to do correct calculations and deliver accurate results. When there is something wrong, we want to trace back to those referenced cells to find the root cause. Excel natively has a built-in convenient formula dependent/precedent trace feature, it highlights the dependent/precedent cells and displays arrows to indicate the relationships. This helps users to trace back and find any error formulas easily.
Now, when bringing the spreadsheet online, we can do more. We can display the relationships in a custom way that is most useful according to the application context, or bring them to a different service or application for doing the validation programmatically.
Spreadsheets are no doubt the most popular business application – they are heavily used in all fields, favored by users from finance experts in Wall Street to top scientists in NASA. Spreadsheets allow users to calculate, organize and store data, and most important of all, analyze data without having to program.
Nowadays spreadsheets extend their reach more – they no longer sit inside a user’s Excel desktop application, they are now widely used online, either being embedded inside applications or run on an online platform like google sheets. But when a spreadsheet goes online, can we do more than just duplicating Excel’s functionality into the browser?
Excelize is a library written in pure Go providing a set of functions that allow you to write to and read from XLSX / XLSM / XLTM files. Supports reading and writing spreadsheet documents generated by Microsoft Excel™ 2007 and later. Supports complex components by high compatibility, and provided streaming API for generating or reading data from a worksheet with huge amounts of data. This library needs Go version 1.10 or later.
You’re probably familiar with the numerous stats dedicated to customer retention. For example, customer acquisition is 5 times more expensive than retention. Providing an exceptional customer experience is critical to keeping customers happy. For most B2B technology companies, this starts with the onboarding process.
But data onboarding—that critical first step of bringing customer data into a platform—isn’t as well understood or discussed. Fortunately for frustrated software customers everywhere, that’s changing.
Data onboarding is an emerging category with a big impact: getting your customers to reap value from your product faster and with fewer demands on your internal engineering and customer success teams.
Data onboarding is a problem for companies of all sizes
According to a data onboarding survey that Flatfile recently conducted, 23% of software companies state that it can take weeks or months to import customer data, and 96% reported that they have run into problems while doing so.
Importing CSV files isn’t enjoyable for the customers prepping them, for the developers building the import function, or for the customer service and success teams fielding constant data import questions.
CRMs, ERPs, product lifecycle management software, and inventory management software are just a few of the many software categories that necessitate data importing. Without customer data, they’re useless. Unfortunately, importing customer data into these software tools is easier said than done. And a poor data onboarding experience has repercussions.
If an enterprise software provider lacks simple and effective data import capabilities, customer frustration and churn could be the result. In addition, companies typically waste precious time and resources having internal teams format spreadsheet errors, fix validation problems, and generally wrangle spreadsheets on behalf of their customers who are simply trying to import their data.
Companies face a build vs. buy decision for importing data
Importing data is essential to get customers onboarded quickly, gaining value from a software platform. But it turns out that building a high quality data importer is both costly and time-consuming. Essentially, it’s a product in and of itself.
Your engineering and product teams are busy building out new features that matter to your customers and fixing bugs for critical functionality. Building a data importer is not typically on their growing to-do list.
When companies build their own data importers in house, the inevitable occurs:
The team can’t give a data importer the full attention it deserves so they’re likely to produce something that isn’t intuitive for customers to use and doesn’t offer clear troubleshooting steps when an import fails.
Maintaining a data importer requires ongoing work. Once a data importer is built, there needs to be dedicated resources to update, fix and add new features to the importer.
There is, however, another option. Software companies can choose to buy a data onboarding solution to import data rather than build one from scratch.
John Baigent, the co-founder of Oversight Software and a customer of Flatfile’s data importer, Portal, says, “We aren’t spending precious time reinventing the wheel in terms of file upload, we’re spending our time developing features that our customers want to see and subsequently make their jobs easier.”
The ROI of a pre-built data importer
Startups like ParrotMob and TableCloth are using Flatfile Portal to solve their data import challenges. Early-stage startups, in particular, shouldn’t waste resources on building and maintaining a data importer. Michael McCarthy, CEO of Inkit describes the potential losses from a poorly built importer. “We had two clients that were paying upwards of $30,000 a year and were at risk to churn if we didn’t figure our data import issue out,” McCarthy says.
“Without Flatfile, we would have had to dedicate one or two full time engineers to the development and maintenance of an internal data import solution and honestly, it would never have been as good as Flatfile’s product,” says McCarthy. “I could see a bigger company looking at a million dollars a year in cost savings.”
Flatfile leads the emerging data onboarding category
Effective data import is an essential part of a larger category that’s on the rise: data onboarding.
Successful data onboarding ensures that it’s as easy as possible to bring customer data into a product – whether customers themselves are migrating the data or a customer success team (as part of a white-glove onboarding experience). When data onboarding works, customer onboarding is a whole lot smoother and extensive time is no longer dedicated to asking: did the data import go okay?!
Flatfile is setting a new standard in data onboarding with two innovative business products:
Thanks to Flatfile, companies of all sizes no longer need to waste time on patchwork solutions like emailing sensitive Excel files, formatting CSV templates, or hiring expensive teams to help onboard customer data.
Remember Tabletop.js? We just covered it a little bit ago in this same exact context: building editable websites. It’s a tool that turns a Google Sheet into an API, that you as a developer can hit for data when building a website. In that last article, we used that API on the client side, meaning JavaScript needed to run on every single page view, hit that URL for the data, and build the page. That might be OK in some circumstances, but let’s do it one better. Let’s hit the API during the build step so that the content is built into the HTML directly. This will be far faster and more resilient.
The situation
As a developer, you might have had to work with clients who keep bugging you with unending revisions on content, sometimes, even after months of building the site. That can be frustrating as it keeps pulling you back, preventing you from doing more productive work.
We’re going to give them the keys to updating content themselves using a tool they are probably already familiar with: Google Sheets.
A new tool
In the last article, we introduced the concept of using Google Sheets with Tabletop.js. Now let’s introduce a new tool to this party: Eleventy.
We’ll be using Eleventy (a static site generator) because we want the site to be rendered as a pure static site without having to ship all of the under workings of the site in the client side JavaScript. We’ll be pulling the content from the API at build time and having Eleventy create a minified index.html that we’ll push to the server for the production website. By being static, this allows the page to load faster and is better for security reasons.
The spreadsheet
We’ll be using a demo I built, with its repo and Google Sheet to demonstrate how to replicate something similar in your own projects. First, we’ll need a Google Sheet which will be our data store.
Open a new spreadsheet and enter your own values in the columns just like mine. The first cell of each column is the reference that’ll be used later in our JavaScript, and the second cell is the actual content that gets displayed.
In the first column, “header” is the reference name and “Please edit me!” is the actual content in the first column.
Next up, we’ll publish the data to the web by clicking on File → Publish to the web in the menu bar.
A link will be provided, but it’s technically useless to us, so we can ignore it. The important thing is that the spreadsheet(and its data) is now publicly accessible so we can fetch it for our app.
Take note that we’ll need the unique ID of the sheet from its URL as we go on.
Node is required to continue, so be sure that’s installed. If you want to cut through the process of installing all of thedependencies for this work, you can fork or download my repo and run:
npm install
Run this command next — I’ll explain why it’s important in a bit:
npm run seed
Then to run it locally:
npm run dev
Alright, let’s go into src/site/_data/prod/sheet.js. This is where we’re going to pull in data from the GoogleSheet, then turn it into an object we can easily use, and finally convert the JavaScript object back to JSON format. The JSON is stored locally for development so we don’t need to hit the API every time.
Here’s the code we want in there. Again, be sure to change the variable sheetID to the unique ID of your own sheet.
module.exports = () => {
return new Promise((resolve, reject) => {
console.log(`Requesting content from ${googleSheetUrl}`);
axios.get(googleSheetUrl)
.then(response => {
// massage the data from the Google Sheets API into
// a shape that will more convenient for us in our SSG.
var data = {
"content": []
};
response.data.feed.entry.forEach(item => {
data.content.push({
"header": item.gsx$header.$t,
"header2": item.gsx$header2.$t,
"body": item.gsx$body.$t,
"body2": item.gsx$body2.$t,
"body3": item.gsx$body3.$t,
"body4": item.gsx$body4.$t,
"body5": item.gsx$body5.$t,
"body6": item.gsx$body6.$t,
"body7": item.gsx$body7.$t,
"body8": item.gsx$body8.$t,
"body9": item.gsx$body9.$t,
"body10": item.gsx$body10.$t,
"body11": item.gsx$body11.$t,
"body12": item.gsx$body12.$t,
"body13": item.gsx$body13.$t,
"body14": item.gsx$body14.$t,
"body15": item.gsx$body15.$t,
"body16": item.gsx$body16.$t,
"body17": item.gsx$body17.$t,
})
});
// stash the data locally for developing without
// needing to hit the API each time.
seed(JSON.stringify(data), `${__dirname}/../dev/sheet.json`);
// resolve the promise and return the data
resolve(data);
})
// uh-oh. Handle any errrors we might encounter
.catch(error => {
console.log('Error :', error);
reject(error);
});
})
}
In module.exports, there’s a promise that’ll resolve our data or throw errors when necessary. You’ll notice that I’m using a axios to fetch the data from the spreadsheet. I like that it handles status error codes by rejecting the promise automatically, unlike something like Fetch that requires monitoring error codes manually.
I created a data object in there with a content array in it. Feel free to change the structure of the object, depending on what the spreadsheet looks like.
We’re using the forEach() method to loop through each spreadsheet column while equating it with the corresponding name we want to allocate to it, while pushing all of these into the data object as content.
Remember that seed command from earlier? We’re using seed to transform what’s in the data object to JSON by way of JSON.stringify, which is then sent to src/site/_data/dev/sheet.json.
Yes! Now have data in a format we can use with any templating engine, like Nunjucks, to manipulate it. But, we’re focusing on content in this project, so we’ll be using the index.md template format to communicate the data stored in the project.
For example, here’s how it looks to pull item.header through a for loop statement:
<div class="listing">
{%- for item in sheet.content -%}
<h1>{{ item.header }} </h1>
{%- endfor -%}
</div>
If you’re using Nunjucks, or any other templating engine, you’ll have to pull the data accordingly.
Finally, let’s build this out:
npm run build
Note that you’ll want a dist folder in the project where the build process can send the compiled assets.
But that’s not all! If we were to edit the Google Sheet, we won’t see anything update on our site. That’s where Zapier comes in. We can “zap” Google sheet and Netlify so that an update to the Google Sheet triggers a deployment from Netlify.
Assuming you have a Zapier account up and running, we can create the zap by granting permissions for Google and Netlify to talk to one another, then adding triggers.
The recipe we’re looking for? We’re connecting Google Sheets to Netlify so that when a “new or updated sheet row” takes place, Netlify starts a deploy. It’s truly a set-it-and-forget-it sort of deal.
Yay, there we go! We have a performant static site that takes its data from Google Sheets and deploys automatically when updates are made to the sheet.
Many companies have operated their business with Excel for decades. It is powerful yet easy to use, however, one of the biggest issues with Excel is that it is hard to integrate an Excel file with other systems and services, especially with a database. If you upload an Excel file as an attachment to a system and have to download it and open it up in Excel whenever you need to edit the file, you are just using Excel in a standalone manner. This is not an integrated solution.
In this article, I will show you how you can make your Excel file work seamlessly in a database-driven web application.
Hi there. Today, I’d like to share a bit of code I made to turn a repetitive Excel task into an automated web application. We have so many time-consuming processes that are easy to automate and make easier.
Our administrative staff deals with contractors and suppliers. We have the usual system in which every single company working with us needs to provide its administrative information through the vendor registration form. Being added to the approved vendor list is a necessary step before we can order services or supplies from them.
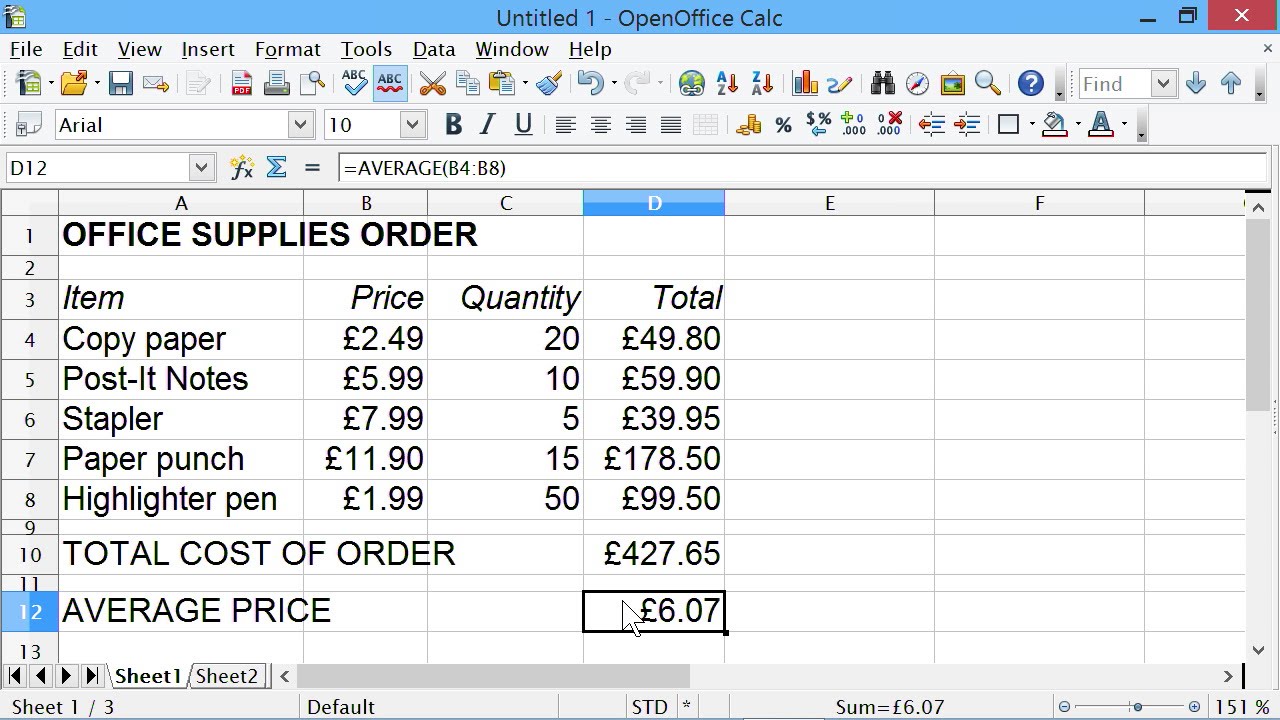
A spreadsheet has always been a strong (if fairly literal) analogy for a database. A database has tables, which is like a single spreadsheet. Imagine a spreadsheet for tracking RSVPs for a wedding. Across the top, column titles like First Name, Last Name, Address, and Attending?. Those titles are also columns in a database table. Then each person in that spreadsheet is literally a row, and that's also a row in a database table (or an entry, item, or even tuple if you're really a nerd).
It's been getting more and more common that this doesn't have to be an analogy. We can quite literally use a spreadsheet UI to be our actual database. That's meaningful in that it's not just viewing database data as a spreadsheet, but making spreadsheet-like features first-class citizens of the app right alongside database-like features.
With a spreadsheet, the point might be viewing the thing as a whole and understanding things that way. Browsing, sorting, entering and editing data directly in the UI, and making visual output that is useful.
With a database, you don't really look right at it — you query it and use the results. Entering and editing data is done through code and APIs.
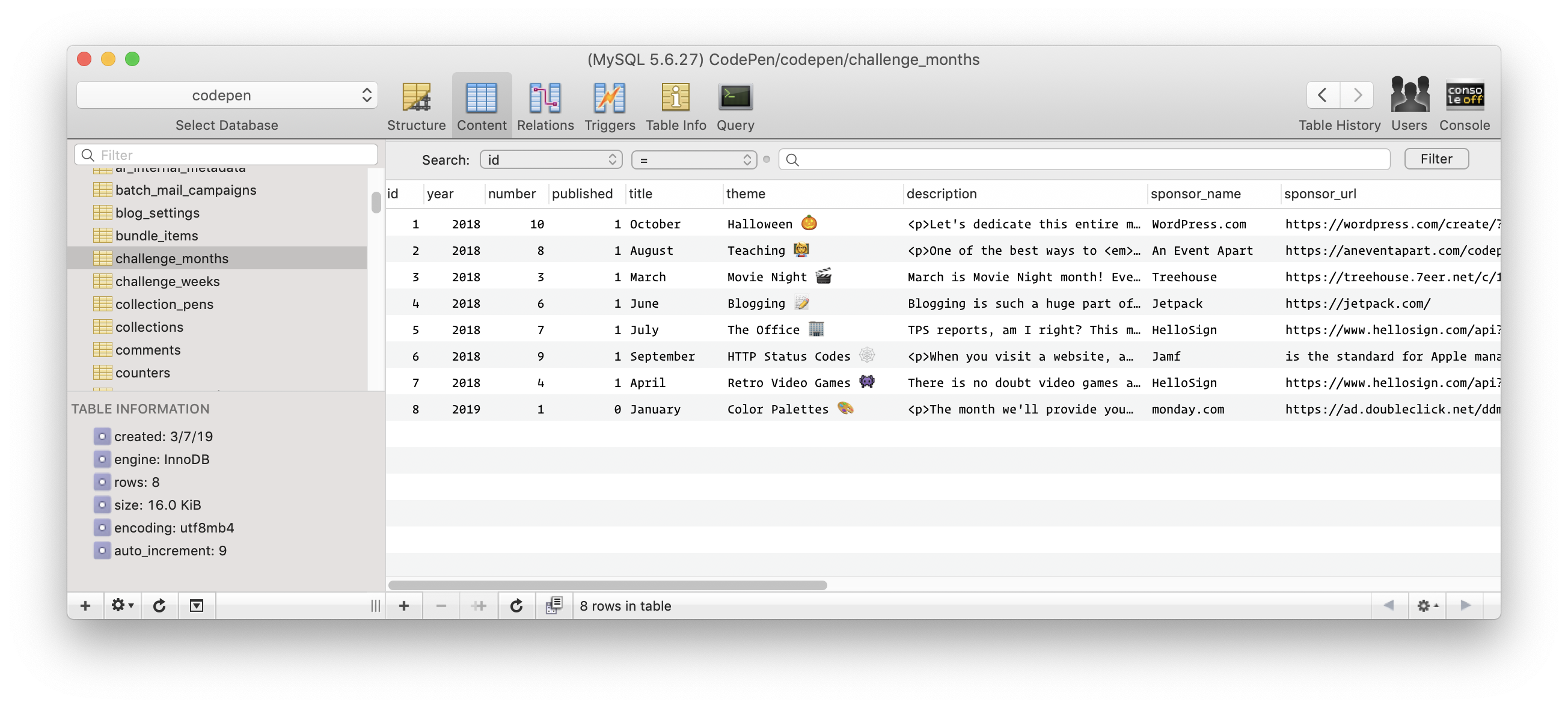
That's not to say you can't look directly at a database. Database tools like Sequel Pro (and many others!) offer an interface for looking at tables in a spreadsheet-like format:
What's nice is that the idea of spreadsheets and databases can co-exist, offering the best of both worlds at once. At least, on a certain scale.
We've talked about Airtable before here on CSS-Tricks and it's a shining example of this.
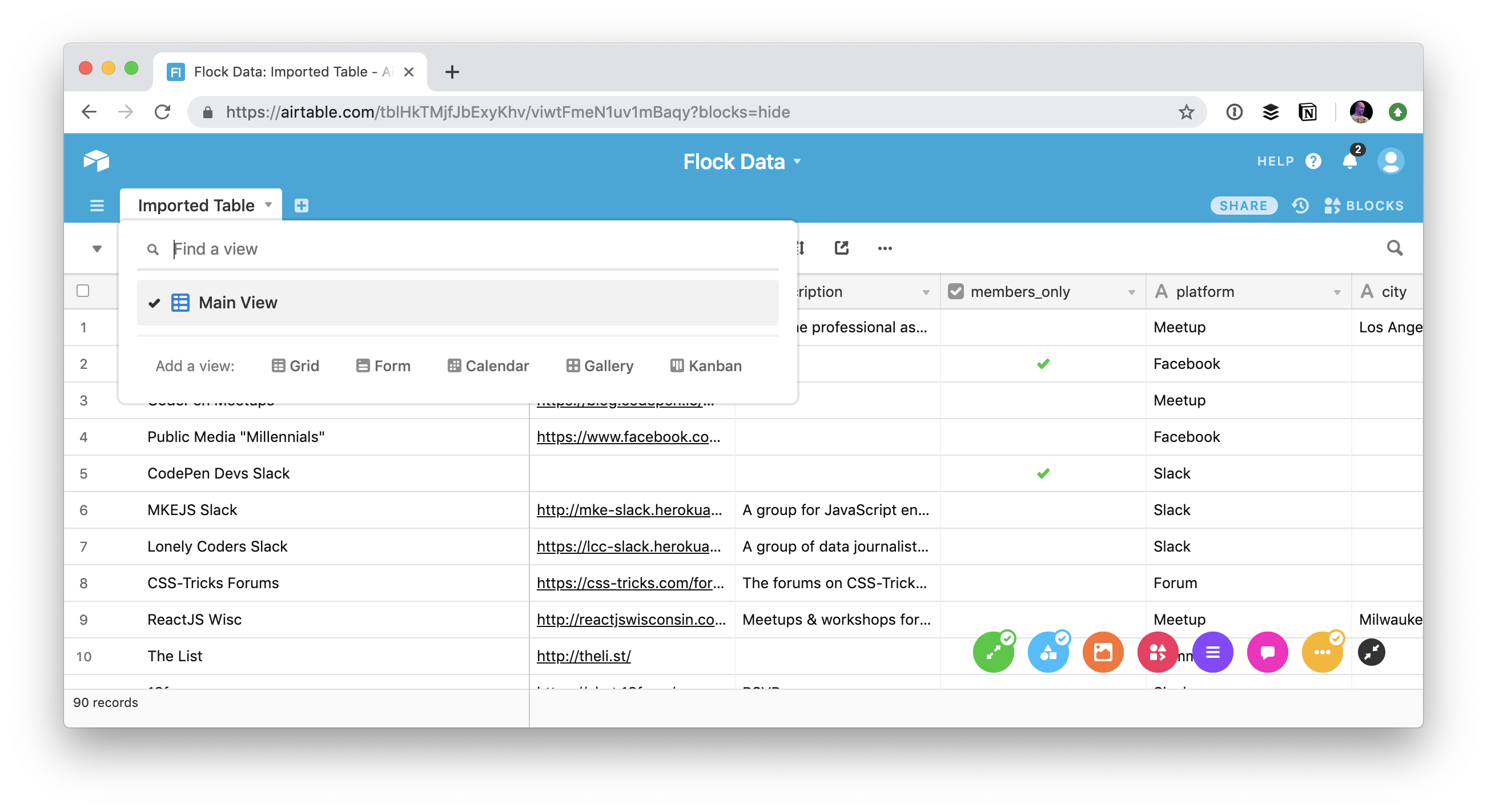
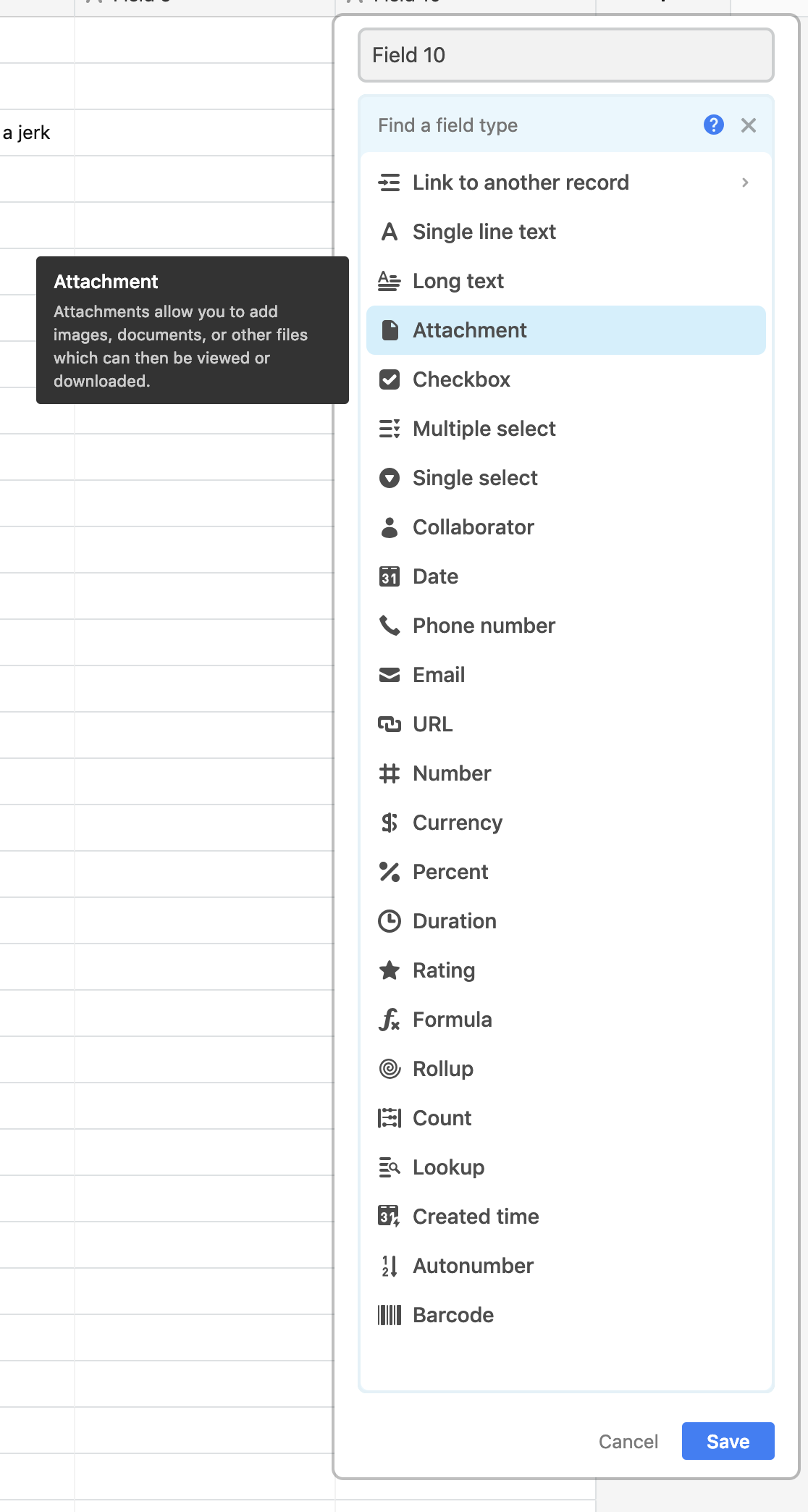
Airtable calls them bases, and while you can view the data inside them in all sorts of useful ways (a calendar! a gallery! a kanban!), perhaps the primary view is that of a spreadsheet:
If all you ever do with Airtable is use it as a spreadsheet, it's still very nice. The UI is super well done. Things like filtering and sorting feel like true first-class citizens in a way that it's almost weird that other spreadsheet technology doesn't. Even the types of fields feel practical and modern.
Plus with all the different views in a base, and even cooler, all the "blocks" they offer to make the views more dashboard-like, it's a powerful tool.
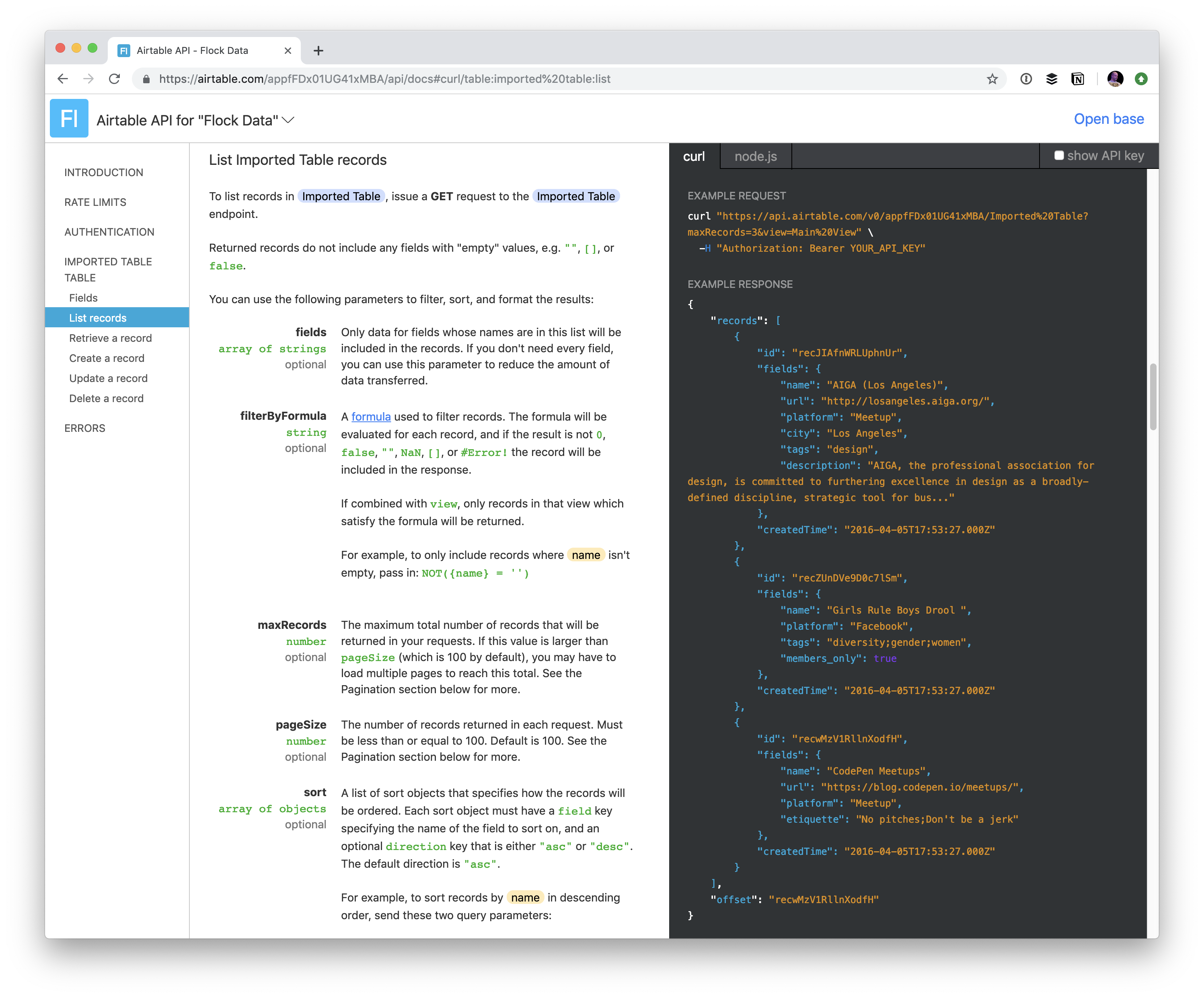
But the point I'm trying to make here is that you can use your Airtable base like a database as well, since you automatically have read/write API access to your base.
So cool that these API docs use data from your own base to demonstrate the API.
The write access is arguably even more useful. We use it at CodePen to do CRM-ish stuff by sending data into an Airtable base with all the information we need, then use Airtable directly to visualize things and do the things we want.
RowShare looks weirdly similar (although a bit lighter on features) but it doesn't look like it has an API, so it doesn't quite fit the bill for that database/spreadsheet gap spanning.
Zoho Creator does have an API and interesting visualization stuff built in, which actually looks pretty darn cool. It looks like some of their marketing is based around the idea that if you need to build a CRUD app, you can do that with this with zero coding — and I think they are right that it's a compelling sell.
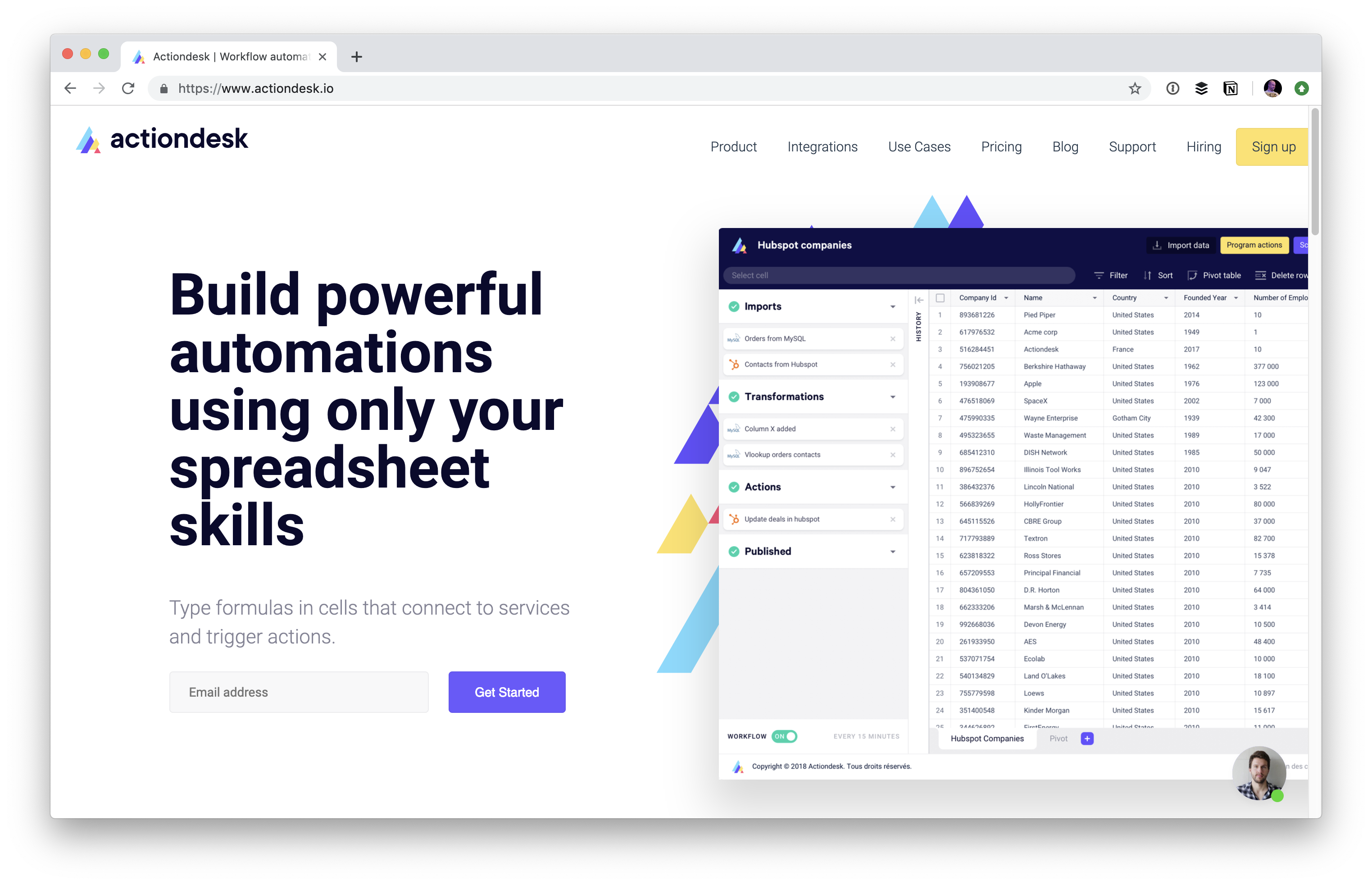
Actiondesk looks interesting in that it's in the category of a modern take on the power of spreadsheets.
While it's connected to a database in that it looks like it can yank in data from something like MySQL or PostgreSQL, it doesn't look like it has database-like read/write APIs.
Can we just use Google Sheets?
The biggest spreadsheet tool in the sky is, of course, the Google one, as it's pretty good, free, and familiar. It's more like a port of Excel to the browser, so I might argue it's more tied to the legacy of number-nerds than it is any sort of fresh take on a spreadsheet or data storage tool.
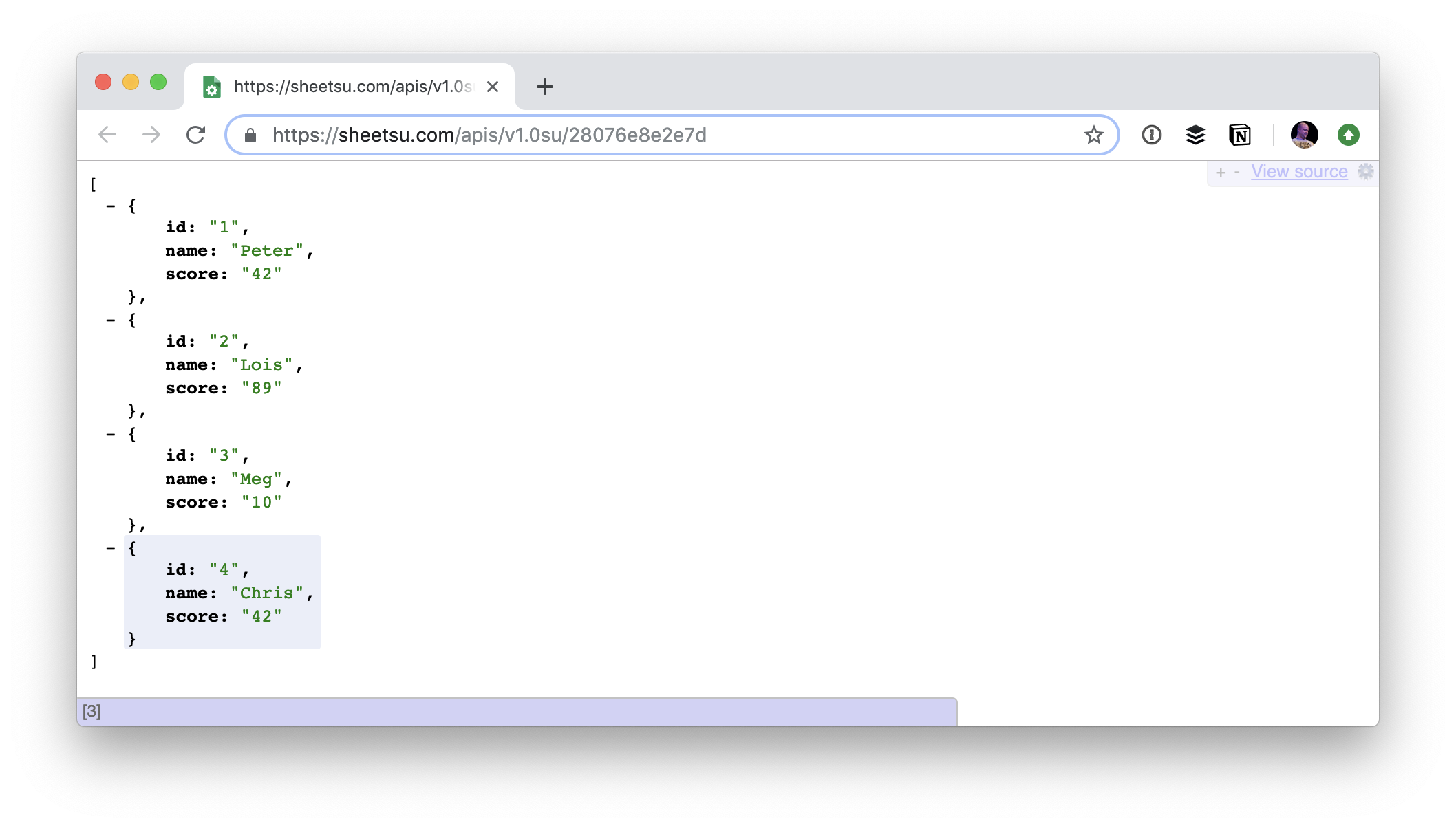
What looks like the most compelling route here, assuming you want to keep all your data in Google Sheets and use it like a database, is Sheetsu. It deals with the connection/auth to the sheet on its end, then gives you API endpoints to the data that are clean and palatable.
Plus there are some interesting features, like giving you a form UI for possibly easier (or more public) data entry than dealing with the spreadsheet itself.
There is also Sheetrock.js, an open source library helping out with that API access to a sheet, but it hasn't been touched in a few years so I'm unsure the status there.
I ain't trying to tell you this idea entirely replaces traditional databases.
For one thing, the relational part of databases, like MySQL, is a super important aspect that I don't think spreadsheets always handle particularly well.
Say you have an employee table in your database, and for each row in that table, it lists the department they work for.
ID Name Department
-- -- --
1 Chris Coyier Front-End Developer
2 Barney Butterscotch Human Resources
In a spreadsheet, perhaps those department names are just strings. But in a database, at a certain scale, that's probably not smart. Instead, you'd have another table of departments, and relate the two tables with a foreign key. That's exactly what is described in this classic explainer doc:
To find the name of a particular employee's department, there is no need to put the name of the employee's department into the employee table. Instead, the employee table contains a column holding the department ID of the employee's department. This is called a foreign key to the department table. A foreign key references a particular row in the table containing the corresponding primary key.
ID Name Department
-- -- --
1 Chris Coyier 1
2 Barney Butterscotch 2
ID Department Manager
-- -- --
1 Front-End Developers Akanya Borbio
2 Human Resources Susan Snowrinkle
To be fair, spreadsheets can have relational features too (Airtable does), but perhaps it isn't a fundamental first-class citizen like some databases treat it.
Perhaps more importantly, databases, largely being open source technology, are supported by a huge ecosystem of technology. You can host your PostgreSQL or MySQL database (or whatever all the big database players are) on all sorts of different hosting platforms and hardware. There are all sorts of tools for monitoring it, securing it, optimizing it, and backing it up. Plus, if you're anywhere near breaking into the tens of thousands of rows point of scale, I'd think a spreadsheet has been outscaled.
Choosing a proprietary host of data is largely for convenience and fancy UX at a somewhat small scale. I kinda love it though.