Cloud-native technologies are revolutionary and disruptive to existing infrastructure, application, and monitoring methods that result in opacity problems. We’ll go into more detail as to why the shift to cloud-native observability has arrived, propose a broader, more meaningful definition of what it is, the resulting significance, and deeper implications. But first, let’s revisit containerization, and by extension, why cloud-native observability is so important.
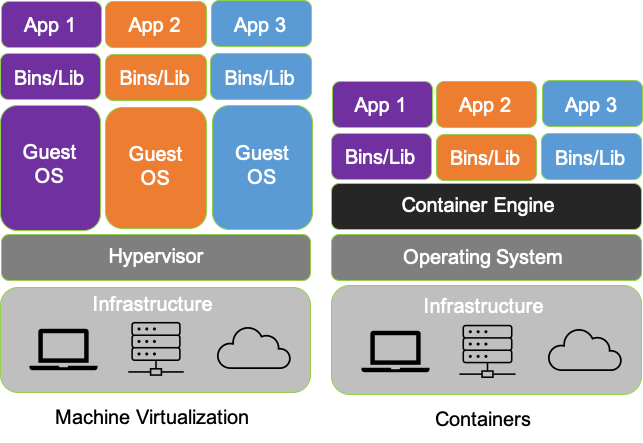
Virtualization and Cloud-Native/Container-Based Systems![cloud-native]()
There is no intervening hypervisor between the OS and the underlying infrastructure in containerized environments, enabling applications and developers to take full advantage of the benefits of cloud-native development and deployment in terms of interoperability, efficiency, and performance. Consequently, in addition to the resulting efficiency and portability advantages, containerization makes it possible to access and use operating system (and kernel) services directly to examine the state and operation of the underlying infrastructure (nodes/bare metal servers), as well as the attendant services, the operating system, and applications. This is profoundly important because in the cloud-native world – network topology (physical and virtual) is hidden, interfaces (network namespaces) are hidden, data flows are hidden, and to make matters even more challenging - resources can be ephemeral - dynamically configured, provisioned, deployed and reused.