Site performance is potentially the most important metric. The better the performance, the better chance that users stay on a page, read content, make purchases, or just about whatever they need to do. A 2017 study by Akamai says as much when it found that even a 100ms delay in page load can decrease conversions by 7% and lose 1% of their sales for every 100ms it takes for their site to load which, at the time of the study, was equivalent to $1.6 billion if the site slowed down by just one second. Google’s industry benchmarks from 2018 also provide a striking breakdown of how each second of loading affects bounce rates.

On the flip side, Firefox made their webpages load 2.2 seconds faster on average and it drove 60 million more Firefox downloads per year. Speed is also something Google considers when ranking your website placement on mobile. Having a slow site might leave you on page 452 of search results, regardless of any other metric.
With all of this in mind, I thought improving the speed of my own version of a slow site would be a fun exercise. The code for the site is available on GitHub for reference.
This is a very basic site made with simple HTML, CSS, and JavaScript. I’ve intentionally tried to keep this as simple as possible, meaning the reason it is slow has nothing to do with the complexity of the site itself, or because of some framework it uses. About the most complex part are some social media buttons for people to share the page.
Here’s the thing: performance is more than a one-off task. It’s inherently tied to everything we build and develop. So, while it’s tempting to solve everything in one fell swoop, the best approach to improving performance might be an iterative one. Determine if there’s any low-hanging fruit, and figure out what might be bigger or long-term efforts. In other words, incremental improvements are a great way to score performance wins. Again, every millisecond counts.
In that spirit, what we’re looking at in this article is focused more on the incremental wins and less on providing an exhaustive list or checklist of performance strategies.
Lighthouse
We’re going to be working with Lighthouse. Many of you may already be super familiar with it. It’s even been covered a bunch right here on CSS-Tricks. It’s is a Google service that audit things performance, accessibility, SEO, and best practices. I’m going to audit the performance of my slow site before and after the things we tackle in this article. The Lighthouse reports can be accessed directly in Chrome’s DevTools.
Go ahead, briefly look at the things that Lighthouse says are wrong with the website. It’s good to know what needs to be solved before diving right in.

We can totally fix this, so let’s get started!
Improvement #1: Redirects
Before we do anything else, let’s see what happens when we first hit the website. It gets redirected. The site used to be at one URL and now it lives at another. That means any link that references the old URL is going to redirect to the new URL.
Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort.
We can try to remove them by updating wherever we use the previous URL of the site, and point it to the updated URL so users are taken there directly instead of redirected. Using a network request inspector, I’m going to see if there’s anything we can remove via the Network panel in DevTools. We could also use a tool, like Postman if we need to, but we’ll limit our work to DevTools as much as possible for the sake of simplicity.
First, let’s see if there are any HTTP or HTML redirects. I like using Fiddler, and when I inspect the network requests I see that there are indeed some old URLs and redirects floating around.

It looks like the first request we hit is https://anonrobot.github.io/redirect-to-slow-site/ before it HTML redirects to https://anonrobot.github.io/slow-site/. We can repoint all our redirect-to-slow-site URLs to the updated URL. In DevTools, the Network inspector helps us see what the first webpage is doing too. From my view in Fiddler it looks like this:

This tell us that the site is using an HTML redirect to the next site. I’m going to update my referenced URL to the new site to help decrease latency that adds drag to the initial page load.
Improvement #2: The Critical Render Path
Next, I’m going to profile the sit with the Performance panel in DevTools. I am most interested in unblocking the site from rendering content as fast as it can. This is the process of turning HTML, CSS and JavaScript into a fully fleshed out, interactive website.
It begins with retrieving the HTML from the server and converting this into the Document Object Model (DOM). We’ll run any inline JavaScript as we see it, or download it if it’s an external asset as we go line-by-line parsing the HTML. We’ll also build the CSS into the CSS Object Model (CSSOM). The CSSOM and the DOM combine to make the render tree. From there, we run the layout which places everything on the screen in the correct place before finally running paint.
This process can be “blocked” if it has to wait for resources to load before it runs. That’s what we call the Critical Render Path, and the things that block the path are critical resources.
The most common critical resources are:
- A
<script>tag that is in the<head>and doesn’t contain anasync, ordefer, ormoduleattribute. - A
<link rel="stylesheet">that doesn’t have thedisabledattribute to inform the browser to not download the CSS and doesn’t have amediaattribute that matches the user’s device.
There’s a few more types of resources that might block the Critical Render Path, like fonts, but the two above are by far the most common. These resources block rendering because the browser thinks the page is “unfinished” and has no idea what resources it needs or has. For all the browser knows, the site could download something that expects the browser to do even more work, like styling or color changes; hence, the site is incomplete to the browser, so it assumes the worst and blocks rendering.
An example CSS file that wouldn’t block rendering would be:
<link href="printing.css" rel="stylesheet" media="print">The "media="print" attribute only downloads the stylesheet when the user prints the webpage (because perhaps you want to style things differently in print), meaning the file itself isn’t blocking anything from rendering before it.
As Chris likes to say, a front-end developer is aware. And being aware of what a page needs to download before rendering begins is vitally important for improving performance audit scores.
Improvement #3: Unblock parsing
Blocking the render path is one thing we can immediately speed up, and we can also block parsing if we aren’t careful with our JavaScript. Parsing is what makes HTML elements part of the DOM, and whenever we encounter JavaScript that needs to run now, we block that HTML parsing from happening.
Some of the JavaScript in my slow webpage doesn’t need to block parsing. In other words, we can download the scripts asynchronously and continue parsing the HTML into the DOM without delay.
The <async> tag is what allows the browser to download the JavaScript asset asynchronously. The <defer> tag only runs the JavaScript once the page construction is complete.
There’s a trade off here between inlining JavaScript (so running it doesn’t require a network request) versus placing it into it’s own JavaScript file (for modularity and code-reuse). Feel free to make your own judgement call here as the best route is going to depend on the use case. The actual performance of applying CSS and JavaScript to a webpage will be the same whether it’s an external asset or inlined, once it has arrived. The only thing we are removing when we inline is the network request time to get the external assets (which sometimes makes a big difference).
The main thing we’re aiming for is to do as little as we can. We want to defer loading assets and make those assets as small as possible at the same time. All of this will translate into a better performance outcome.
My slow site is chaining multiple critical requests, where the browser has to read the next line of HTML, wait, then read the next on to check for another asset, then wait. The size of the assets, when they get downloaded, and whether they block are all going to play hugely into how fast our webpage can load.
I approached this by profiling the site in the DevTools Performance panel, which is simply records the way the site loads over time. I briefly scanned my HTML and what it was downloading, then added <async> to any external JavaScript script that was blocking things (like the social media <script>, which isn’t necessary to load before rendering).

It’s interesting that Chrome has a browser limit where it can only deal with six inflight HTTP connections per domain name, and will wait for an asset to return before requesting another once those six are in-flight. That makes requesting multiple critical assets even worse for HTML parsing. Allowing the browser to continue parsing will speed up the time it takes to show something to the user, and improve our performance audit.
Improvement #4: Reduce the payload size
The total size of a site is a huge determining factor as to how fast it will load. According to web.dev, sites should aim to be below 1,600 KB interactive under 10 seconds. Large payloads are strongly correlated with long times to load. You can even consider a large payload as an expense to the end user, as large downloads may require larger data plans that cost more money.
At this exact point in time, my slow site is a whopping 9,701 KB — more than six times the ideal size. Let’s trim that down.
Identifying unused dependencies
At the beginning of my development, I thought I might need certain assets or frameworks. I downloaded them onto my page and now can’t even remember which ones are actually being used. I definitely have some assets that are doing nothing but wasting time and space.
Using the Network inspector in DevTools (or a tool you feel comfortable with), we can see some things that can definitely be removed from the site without changing its underlying behavior. I found a lot of value in the Coverage panel in DevTools because it will show just how much code is being used after everything’s downloaded.

As we’ve already discussed, there is always a fine balance when it comes to inlining CSS and JavaScript versus using an external asset. But, at this very moment, it certainly appears that the site is downloading far too much than it really needs.
Another quick way to trim things down is to find whether any of the assets the site is trying to load 404s. Those requests can definitely be removed without any negative impact to the site since they aren’t loading anyway. Here’s what Fiddler shows me:
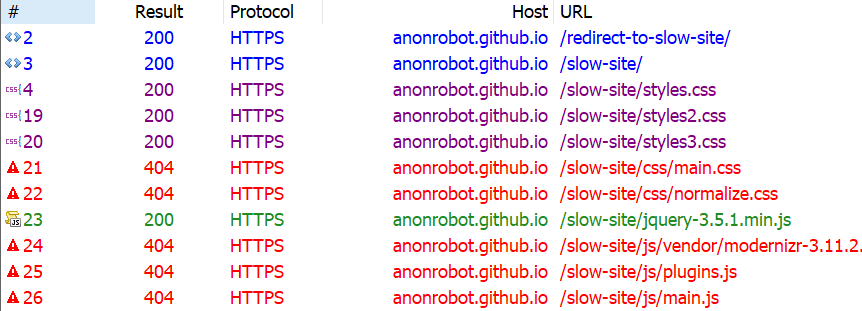
Looking again at the Coverage report, we know there are things that are downloaded but have a significant amount of unused code still making its way to the page. In other words, these assets are doing something, but are also ready to do things we don’t even need them to do. That includes React, jQuery and Vue, so those can be removed from my slow site with no real impact.
Why so many JavaScript libraries? Well, we know there are real-life scenarios where we reach for something because it meets our requirements; but then those requirements change and we need to reach for something else. Again, we’ve got to be aware as front-end developers, and continually keeping an eye on what resources are relevant to site is part of that overall awareness.
Compressing, minifying and caching assets
Just because we need to serve an asset doesn’t mean we have to serve it as its full size, or even re-serve that asset the next time the user visits the site. We can compress our assets, minify our styles and scripts, and cache things responsibly so we’re serving what the user needs in the most efficient way possible.
- Compressing means we optimize a file, such as an image, to its smallest size without impacting its visual quality. For example, gzip is a common compression algorithm that makes assets smaller.
- Minification improves the size of text-based assets, like external script files, by removing cruft from the code, like comments and whitespace, for the sake of sending fewer bytes over the wire.
- Caching allows us to store an asset in the browser’s memory for an amount of time so that it is immediately available for users on subsequent page loads. So, load it once, enjoy it many times.
Let’s look at three different types of assets and how to crunch them with these tactics.
Text-based assets
These include text files, like HTML, CSS and JavaScript. We want to do everything in our power to make these as lightweight as possible, so we compress, minify, and cache them where possible.
At a very high level, gzip works by finding common, repeated parts in the content, stores these sequences once, then removes them from the source text. It keeps a dictionary-like look-up so it can quickly reference the saved pieces and place them back in place where they belong, in a process known as gunzipping. Check out this gzipped examples a file containing poetry.

We’re doing this to make any text-based downloads as small as we can. We are already making use of gzip. I checked using this tool by GIDNetwork. It shows that the slow site’s content is 59.9% compressed. That probably means there are more opportunities to make things even smaller.
I decided to consolidate the multiple CSS files into one single file called styles.css. This way, we’re limiting the number of network requests necessary. Besides, if we crack open the three files, each one contained such a tiny amount of CSS that the three network requests are simply unjustified.
And, while doing this, it gave me the opportunity to remove unnecessary CSS selectors that weren’t being applied in the DOM anywhere, again reducing the number of bytes sent to the user.
Ilya Grigorik wrote an excellent article with strategies for compressing text-based assets.
Images
We are also able to optimize the images on the slow site. As reports consistently show, images are the most common asset request. In fact, the median data transfer for images is 948.1 KB for desktops and 902 KB for mobile devices from 2016 to 2021. That already more than half of the ideal 1,600KB size for an entire page load.
My slow site doesn’t serve that many images, but the images it does serve can be smaller. I ran the images through an online tool called Squoosh, and achieved a 40% savings (18.6 KB to 11.2 KB). That’s a win! Of course, this is something you can do either before upload using a desktop application, like ImageOptim, or even as part of your build process.
I couldn’t see any visual differences between the original images and the optimized versions (which is great!) and I was even able to reduce the size further by resizing the actual file, reducing the quality of the image, and even changing the color palette. But those are things I did in image editing software. Ideally, that’s something you or a designer would do when initially making the assets.
Caching
We’ve touched on minification and compression and what we can do to try and use these to our advantage. The final thing we can check is caching.
I have been requesting the slow site over and over and, so far, I can see it always looks like it’s requested fresh every time without any caching whatsoever. I looked through the HTML and saw caching was disabling here:
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate">I removed that line, so browser caching should now be able to take place, helping serve the content even faster.
Improvement #5: Use a CDN
Another big improvement we can make on any website is serving as much as you can from a Content Delivery Network (CDN). David Attard has a super thorough piece on how to add and leverage a CDN. The traditional path of delivering content is to hit the server, request data, and wait for it to return. But if the user is requesting data from way across the other side of the world from where your data is served, well, that adds time. Making the bytes travel further in the response from the server can add up to large losses of speed, even if everything else is lightning quick.
A CDN is a set of distributed servers around the world that are capable of intelligently delivering content closer to the user because it has multiple locations it choose to serve it from.

We discussed earlier how I was making the user download jQuery when it doesn’t actually make use of the downloaded code, and we removed it. One easy fix here, if I did actually need jQuery, is to request the asset from a CDN. Why?
- A user may have already downloaded the asset from visiting another site, so we can serve a cached response for the CDN. 75.49% of the top one million sites still use jQuery, after all.
- It doesn’t have to travel as far from the user requesting the data.
We can do something as simple as grabbing jQuery from Google’s CDN, which they make available for anyone to reference in their own sites:
<head>
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
</head>That serves jQuery significantly faster than a standard request from my server, that’s for sure.
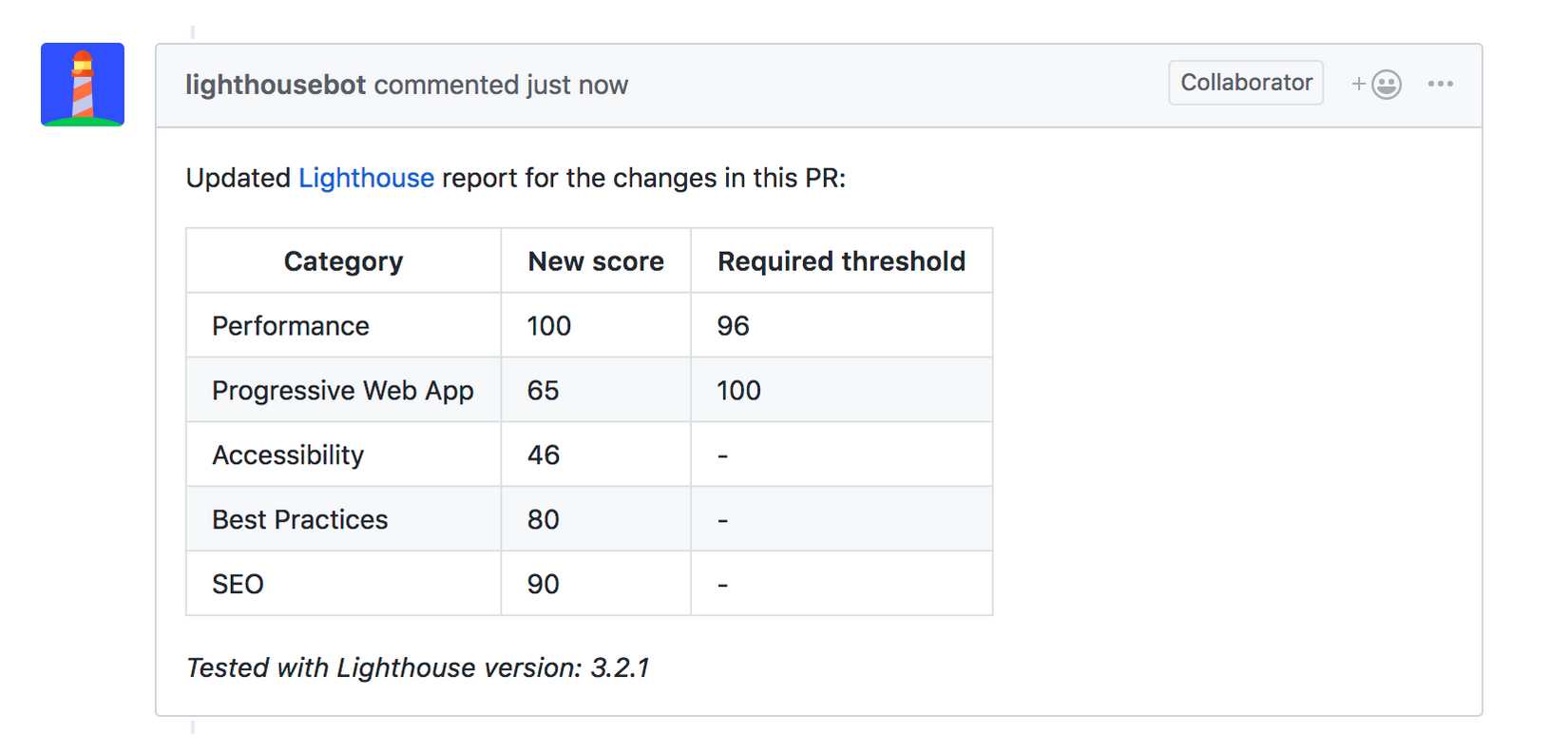
Are things better?
If you have implemented along with me so far, or just read, it’s time to re-profile and see if any improvements has been made on what we’ve done so far.
Recall where we started:
After our changes:

I hope this has been a helpful and encourages you to search for incremental performance wins on your own site. By optimally requesting assets, deferring some assets from loading, and reducing the overall size of the site size will get a functional, fully interactive site in front of the user as fast as possible.
Want to keep the conversation going? I share my writing on Twitter if you want to see more or connect.
The post Fixing a slow site iteratively appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.