In the video below, we take a closer look at HashMap and see an introduction and sample programs. Let's get started!
What Is HashMap? Introduction and Sample Programs | Java Collections Framework


Tips, Expertise, Articles and Advice from the Pro's for Your Website or Blog to Succeed
In the video below, we take a closer look at HashMap and see an introduction and sample programs. Let's get started!
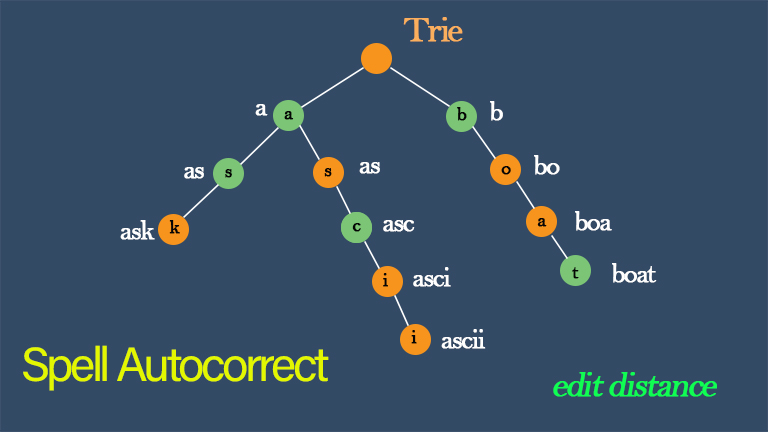
We are familiar with spell checkers. For most spell checkers, a candidate word is considered to be spelled correctly if it is found in a long list of valid words called a dictionary. Google provides a more powerful spell corrector for validating the keywords we type into the input text box. It checks against a dictionary. If it doesn’t find the keyword in the dictionary, it suggests a most likely replacement. To do this it associates with every word in the dictionary a frequency, the number of the times that word is expected to appear in a large document. When a word is misspelled (i.e. it is not found in the dictionary) Google suggests a “similar” word whose frequency is larger or equal to any other “similar” word. In this post, I will introduce the approach of how to implement spell autocorrect. It includes
For this program, we need a dictionary similar to Google’s. Our dictionary is generated using a large text file. The text file contains a large number of unsorted words. Every time our program runs it will create the dictionary from this text file. The dictionary will contain every word in the text file and a frequency for that word.
In this article, we are going to see how HashMap internally works in JAVA. Also, we will have a look at what Java 8 made changes to the internal working of Hashmap to make it faster.
A HashMap is a map used to store mappings of key-value pairs. To learn more about the HashMap, visit this article: HashMap in Java.
When a developer is working on a module, they always come across some form of data structure, like set, queue, list, etc. Data structures are used for storing Java objects in a certain fashion so that they are easy to retrieve when needed.
You may also like: How HashMap Works in Java
The right data structure makes functionality more efficient and effective — otherwise, it would be a nightmare as the implementation expands. You can start with a Map of one of the data structures where objects are stored in the key-value format. And with the help of key, we can easily retrieve the value in time complexity of O(1).
Note: Based on the response from my technical blog I am posting this article here so that it would be visible to a wider audience.
java.util.HashMap.java
Each method of ConcurrentHashMap is thread-safe. But calling multiple methods from ConcurrentHashMap for the same key leads to race conditions. And calling the same method from ConcurrentHashMap recursively for different keys leads to deadlocks.
Let us look at an example to see why this happens: