So, We just spent about 28+ days — using Stack Overflow and Hibernate Search Forums as also various other resources to 'FIX' the strangest of issues using Hibernate Search and Apache Lucene. The right help or pointer came from the 'Hibernate Search Committers/Creators' (Official Forums). Thanks a lot to 'sanne.grinovero'.
Issue Description: In a (non-replicated) clustered environment, if the Indexing by Lucene or Hibernate Search is done from the Same Database (Instance) using the Same Data the Results obtained are Different on Different Nodes. In other words, the Same Data from the Same Database Instance Indexed using the Same Code Yields a Different Result Set for the Same Search Term (Index Contents are Different on Different Machines).
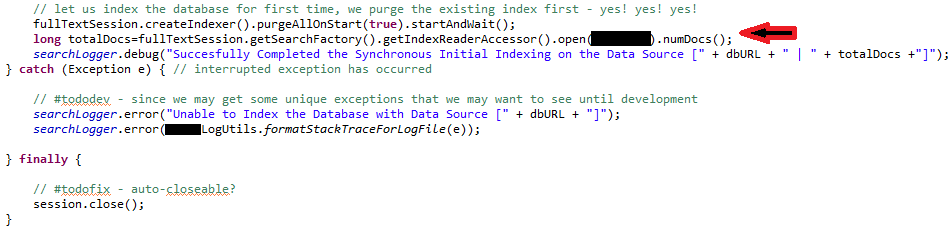
Issue Resolution / Root Cause: The point to note is that, if you open a 'Hibernate Session' that you use for your 'Apache Lucene or Hibernate Search Indexing' and if a 'Runtime/Exception' occurs before you 'Close' the session, the results that are obtained across different machines, when queried using the same search term. Though this occurred after the 'console logs' reported that the Index is '100% Successfully Completed' — It has led to an inconsistent index across machine. My analysis is that 'session.close()' below may be leading to some 'flushing or committing to the indexing', which leads to the inconsistency when a runtime exception occurs — even after indexing is reported complete by the Hibernate/Hibernate Search on the 'Console Logs'.
Suggestion: Make sure that there are no Runtime Exceptions (or Errors) before Closing the Session. Even if you find that the Indexing is 100% Complete and there is an Exception right at the End — Please do not Ignore/Keep/Park it (Considering it a Minor or Unrelated Error) for a fix at the 'End of Dev Cycle' as it may Impact Results. This is true for any seemingly unrelated exception that may occur before calling 'session.close()'.
I am pasting the statement here from Hibernate Search Forums (Committer), which may be useful for all of you and helped us to finally resolve this error: If a batch of documents failed, you might have a block of documents missing in one of the indexes (and this could happen several times). By default errors are logged, you might want to hook up an ErrorHandler to raise a more serious notification to your admins — if logs are ignored.
![The culprit line of code, pointed out in red.]() [CULPRIT LINE OF CODE - WHERE RUNTIME EXCEPTION OCCURS - POINTED OUT USING ARROW]
[CULPRIT LINE OF CODE - WHERE RUNTIME EXCEPTION OCCURS - POINTED OUT USING ARROW]