Code reviews are a fundamental part of the software development lifecycle, allowing you to identify bugs early. If you perform code reviews at your company, you can incorporate several tools to have a more robust development workflow and to make your job easier.
This blog post focuses on tools that can help you improve your code review GitHub workflow. Some can be integrated directly in GitHub, while others work as standalone desktop clients. Let’s check them out.
I have interviewed many engineers and managers lately, and one of the standard questions I ask is how to build high-quality software. Of course, I provide more context and explanations, but the gist is the same. I heard all kinds of answers. However, I was puzzled that almost none were systematic, and people immediately went into a specific pet peeve. As part of this exercise, I felt that I had to crystalize my answer to this question and write it down.
Let me start with high-level thoughts (specifically to make it systematic). First of all, I want to concentrate on software code quality (vs. larger topics, including problem definition, documentation, UX, design, etc.). High-quality software is software that has fewer bugs (and a shorter tail of fixing remaining issues). There are a bunch of other things like code readability, maintainability, debugability, and so on which can easily be swept under the quality umbrella. Let’s concentrate on the core that the product operates as expected.
"There is no single question to what does the best quality mean? However, one proven approach is comparing how well a given code interacts with its neighbors in the same technical domain."
In the world of software development, code quality often comes to mean a certain level of complexity in a code. The code that is too complex for users or developers to understand or use easily is considered low in quality. Sometimes this means that the code is too complex for even the programmers to understand.
As a manager of a software development team, you are always under pressure to deliver value to the customer. In order to do that more effectively, you monitor your Cycle Time and work to keep it as low as possible so that features get into production as quickly as possible.
One of the issues that can be a bump in the road towards meeting that goal is Review Time. Review Time is defined as the time between the first comment on your code and the time it is merged back into the main branch. It’s the third phase of Cycle Time and keeping it inside proper boundaries is critical to keeping quality code moving through the pipeline.
The perlcritic tool is often your first defense against "awkward, hard to read, error-prone, or unconventional constructs in your code," per its description. It's part of a class of programs historically known as linters, so-called because like a clothes dryer machine's lint trap, they "detect small errors with big effects." (Another such linter is perltidy, which I've referenced in the past.)
Pretty much everyone does code reviews. They’ve been around a long time. I remember back in my Borland days when the Chief Scientist would come in every morning and review all the code that had been checked into the Subversion(!) repository the previous day and send emails out to folks whose code wasn’t up to snuff. That’s old school.
Slightly less old school? Saving all the check-ins up until Friday for the Dev Leads and/or Dev Managers to review and approve. Both of these techniques leave a lot to be desired -- the main thing being a complete lack of interaction between the developer, the code, and the reviewer.
How frequent is it for you to be reviewing code at 3 am? When code reviewing, do you find yourself thinking: “I mentioned this before.. We should have some sort of process”.
We keep learning a lot at Codacy with our user base which currently supports more than 200 000 developers.
You might not realize it, but you probably know when you see bad quality code. It might be written in a way that doesn't make sense, be full of errors, excessively verbose, or highly inconsistent in its use of terminology and naming conventions. Fortunately, there are lots of ways you can improve your code quality, make it easier to review and test and reduce the pain later of having to fix all of the errors. Let's take a look.
The Basics of Code Quality
Code quality refers to the attributes and characteristics of your code. These may differ according to your organization's specific business focus and the particular needs of your team. While there's no definitive checklist, there are broadly several things that separate good quality code from poor quality.
I love reviews. When it comes to new gadgets and whether they're worth my money, it’s a blessing to have so much free advice to guide your choice. Last year I bought a new digital piano online, purely based on internet reviews since retail was locked down and I couldn’t try it out anywhere. Most reviews were favorable to raving, so I found safety in numbers there. Sure, retailers reviewing their own wares are naturally biased, but then again nobody would go to the trouble of a scathing review simply because they don’t like music in general or have it in for Casio as a company. Pianos are not controversial, unlike coding styles. And movies. Cinematic opinions are as subjective and controversial as it gets. The site Rotten Tomatoes simplifies all reviews into a thumbs up/down verdict and gives you a percentage. It works great for anything in the upper 20th percentile as well as the lower. I rarely regret watching a 90% movie and I ignore anything under thirty percent. Movie reviews are pure gut feeling. There’s no checklist by which to arrive at an objective verdict. Often reviewers are just film lovers with a gift for writing. They are seldom other directors, screenwriters, or actors.
So why do we treat code reviews like movie reviews? A crude thumbs up/down rating exercise by someone who was not involved or even interested in the creative process. True, the analogy doesn’t hold when it comes to expertise since code reviewers are your programming peers, but that only means they should know better. The movie reviewer who shows off her literary style is like the code reviewer who likes to nitpick on small imperfections to make himself look clever. This is counter-productive, not to say toxic for team morale. You’d better not do reviews at all than do them in this way. Good teams usually do their best to be fair and constructive in their criticism towards each other if only because they need to get along and everybody knows they will be on the receiving end tomorrow. This sounds plausible, but it still misses what I believe is the true purpose of code review. That is firstly to share your work with the team, not to subject it to a quality test.
We have all been there: you’re deep into code and find a bug that has not been noticed before, or some code that should be cleaned up. You are right there so why not fix it? Sometimes the answer is yes, it makes sense to fix it then, following the old backpacker’s mantra of leaving things better than you found them. But other times the answer is no. How do you decide?
Here are some questions to ask. To proceed, the answer to each must be favorable.
Most of us know the definition of a git pull request:
Software developers submit a pull request (often abbreviated to PR) in their git system like GitHub, GitLab or BitBucket to signal to their teammates or manager that a branch or fork they have been working on is ready for review.
The git pull request usually happens in the software development process after coding and before merge.
Read on to learn more about code reviews and Java code structure!
Code reviews are a proven practice to help keep your code as clean as possible. Doing it means nitpicking every detail of each method and class: naming, length, responsibility, algorithm, style, and so on. You have to look at everything used to ensure that lines of code are understood not only by the machine (compiler) but also by humans. As humans, you or your fellow programmers will have to maintain the code.
What about the bigger picture? Well, there’s the architecture of the system. Perhaps, it just sits with the leads of your team, or perhaps it is properly documented, but generally, people know which applications or microservices are integrated with each other and in what direction the data flows between them. Somebody cares about this highest level of modularity.
The world’s greatest chefs never put anything on the plate that will never be eaten, this rule corresponds to the YAGNI principle in Software Engineering. The non-used code blocks saved for future use are sometimes forgotten and another developer could not be in want of changing the code of the legacy system. Such non-used code blocks may affect code readability in the future. We are lucky today many code review tools exist for coding mistakes etc., but using tools is not enough to help code readability.
The code review process is crucial for quality assurance, and there are many ways of going about it. Patterns for code review make this process run a lot more smoothy. This Refcard covers eight of the most popular patterns: long-running PRs, self-merging PRs, heroing, over-helping, “just one more thing,” rubber stamping, knowledge silos, and a high bus factor.
I’ve been auditing a ton of CSS lately and thought it would be neat to jot down how I’m going about doing that. I’m sure there are a million different ways to do this depending on the size and scale of your app and how your CSS works under the hood, so please take all this with a grain of salt.
First a few disclaimers: at Gusto, the company I work for today, our engineers and designers all write in Sass and use webpack to compile those files into CSS. Our production environment minifies all that code into a single CSS file. However, our CSS is made up of three separate domains. so I downloaded them all to my desktop because I wanted to test them individually.
Here’s are those files and what they do:
manifest.css: a file that’s generated from all our Sass functions, mixins and contains all of our default HTML styles and utility classes.
components.css: a file that consists of our React components such as Button.scss, Card.scss, etc. This and manifest.css both come from our Component Library repo and are imported into our main app.
app.css: a collection of styles that override our components and manifest. Today, it exists in our main application repo.
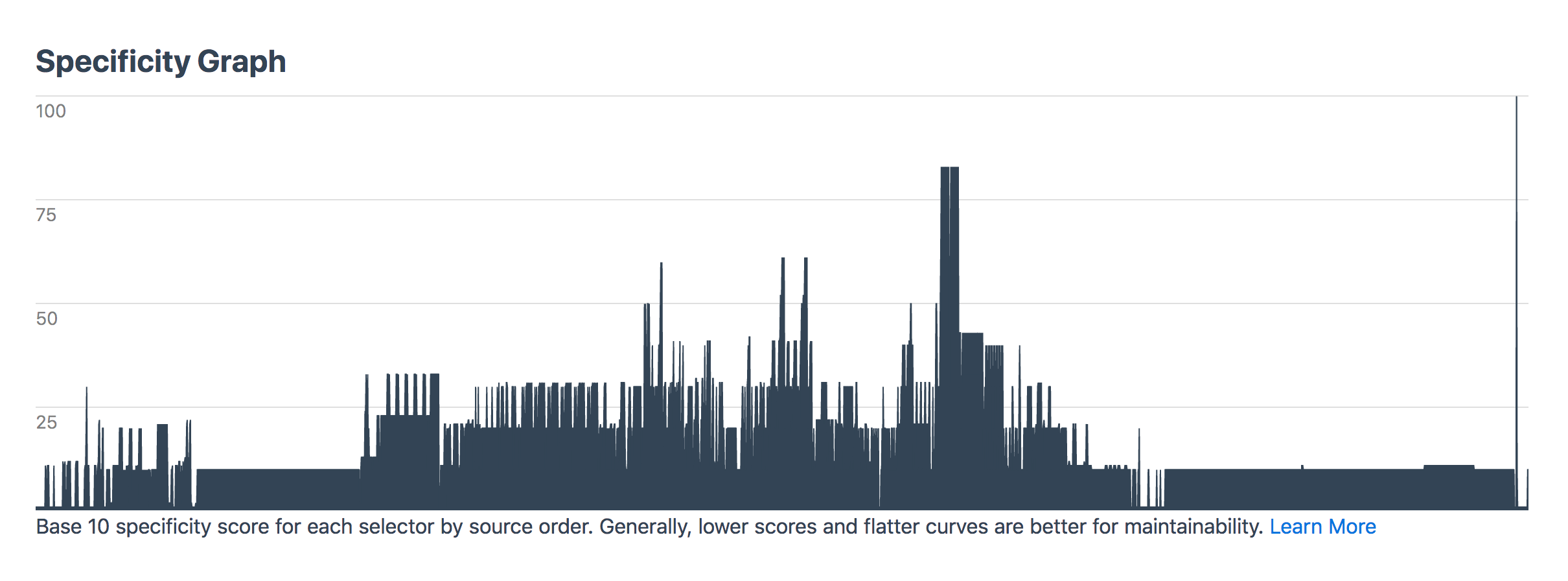
After I downloaded everything, I threw them into an S3 bucket and ran them through CSS Stats. (I couldn’t find a command line tool that I liked, so I decided stuck with this tool.) The coolest thing about CSS Stats is that it provides a ton of clarity about the health and quality of a site’s CSS, and in turn, a design system. It does this by showing the number of unique font-size and unique background-color CSS declarations there are, as well as a specificity graph for that particular CSS file.
I wanted to better understand our manifest.css file first. As I mentioned, this file contains all our utility classes (such as padding-top-10px and c-salt-500) as well as our normalize and reset CSS files, so it's pretty foundational for everything else. I started digging through the results:
There are some obvious issues here, like the fact that there are 101 unique colors and 115 unique background colors. Why is this a big deal? Well, it’s a little striking to me because our team had already made a collection of Sass functions to output a very specific number of colors. In our Figma UI Kit and variables_color.scss (which gets compiled into our manifest file, we declare a total of 68 unique colors:
So, where are all these extra colors coming from? Well, I assume that they’re coming from Bootstrap. Back when we started building the application, we hastily built on top of Bootstrap’s styles without refactoring things as we went. There was a certain moment when this started to hurt as we found visual inconsistencies across our application and hundreds of lines of code being written that simply overrode Bootstrap. In a rather gallant CSS refactor, I removed Bootstrap’s CSS from our main application and archived it inside manifest.css, waiting for the day when we could return to it and refactor it all.
These extra colors are likely come from that old Bootstrap file, but it’s probably worth investigating some more. Anyway, the real issue with this for me is that my understanding of the design system is different from what’s in the front-end. That’s a big problem! If my understanding of the design system is different from how the CSS works, then there’s enormous potential for engineers and designers to pick up on the wrong patterns and for confusion to disseminate across our organization. Think about the extra bloat and lack of maintainability, not to mention other implications.
I was reading Who Are Design Systems For? by Matthew Ström and perked up when he quotes a talk by Julie Ann-Horvath where she’s noted as saying, “a design system doesn’t exist until it’s in production.” Following the logic, it's clear the design system I thought we had didn't actually exist.
Going back to manifest.css though: the specificity graph for this file should be perfectly gradual and yet there are some clear spikes that show there’s probably a bit more CSS that needs to be refactored in there:
Anyway, next up is our components.css. Remember that’s the file that our styles for our components come from so I thought beforehand that it’s bound to be a little messier than our manifest file. Throwing it into CSS Stats returns the following:
CSS-Stats shows some of the same problems — like too many font sizes (what the heck is going on with that giant font size anyway?) — but there are also way too many custom colors and background-colors. I already had a hunch about what the biggest issue with this CSS file was before I started and I don’t think the problem is not shown in this data here at all.
Let me explain.
A large number of our components used to be Bootstrap files of one kind or another. Take our Accordion.jsx React component, for instance. That imports an accordion.css file which is then compiled with all the other component’s CSS into a components.css file. The problem with this is that some Accordion styles affect a lot more than just that component. CSS from this this file bleeds into other patterns and classes that aren’t tied to just one component. It’s sort of like a poison in our system and that impacts our team because it makes it difficult to reliably make changes to a single component. It also leads to a very fragile codebase.
So I guess what I’m saying here is that tools like CSS Stats are wondrous things to help us check core vital signs for CSS health, but I don’t think they’ll ever really capture the full picture.
Anyway, next up is the app.css file:
This is the “monolith” — the codebase that our design systems team is currently trying to better understand and hopefully refactor into a series of flexible and maintainable React components that others can reuse again and again.
What worries me about this codebase is the specificity of it all what happens when something changes in the manifest.css or in our components.css? Will those styles be overridden in the monolith? What will happen to the nice and tidy component styles that we import into a new project?
Subsequently, I don’t know where I stole this, but I’ve been saying it an awful lot lately — you should always be able to predict what your CSS is going to do, whether that’s a single line of code or a giant codebase of intermingled styles. That’s what design systems are all about — designing and building predictable interfaces for the future. And if our compiled CSS has all these unpredictable and unknowable parts to it, then we need to gather everyone together to fix it.
Anywho, I threw some of the data into a Dropbox Paper doc after all this to make sure we start tackling these issues and see gradual improvements over time. That looks something like this today:
How have you gone about auditing your CSS? Does your team code review CSS? Are there any tricks and tips you’d recommend? Leave a comment below!


 For many of us, code review is like eating broccoli: We know it’s good for us, but we hate it.
For many of us, code review is like eating broccoli: We know it’s good for us, but we hate it.