Cloudera SQL Stream Builder (SSB)
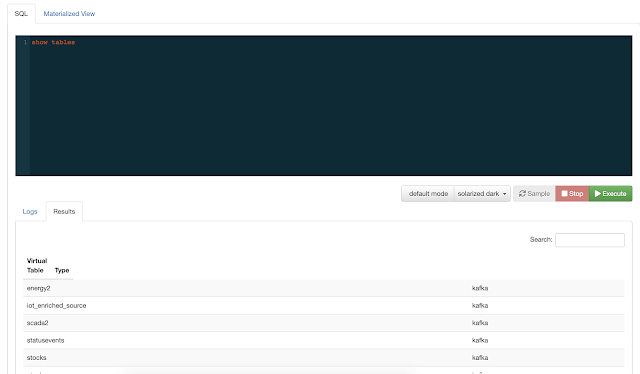
The initial release of Cloudera SQL Stream Builder as part of the CSA 1.3.0 release of Apache Flink and friends from Cloudera shows an integrated environment well integrated into Cloudera's Data Platform. SSB is an improved release of Eventador's SQL Stream Builder with integration into Cloudera Manager, Cloudera Flink, and other streaming tools.