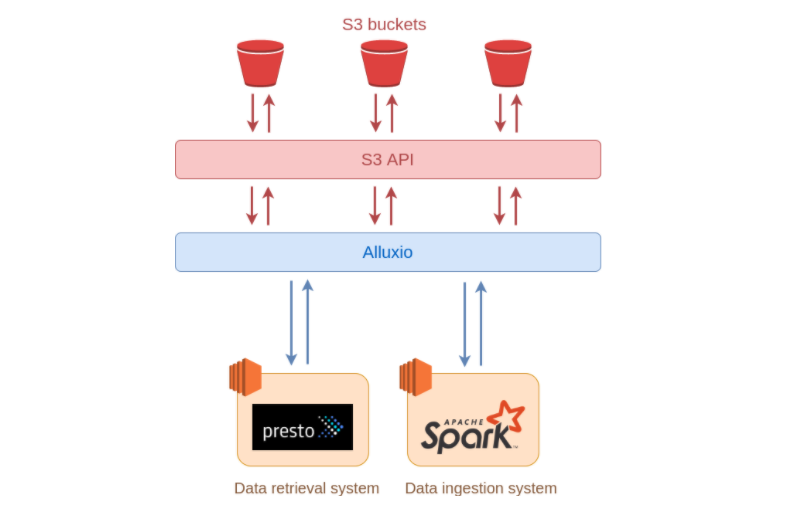
S3 Select is an AWS S3 feature that allows developers to run SQL queries on objects in S3 buckets. Here's an example.
SQL
SELECT s.zipcode, s.id FROM s3object s where s.name = 'Harshil'Previously we wrote about the different ways you can write SQL with AWS. In this article, we will see how to configure and use S3 Select to make working with big datasets easier.
 We had an outage in our online application
We had an outage in our online application