Introduction
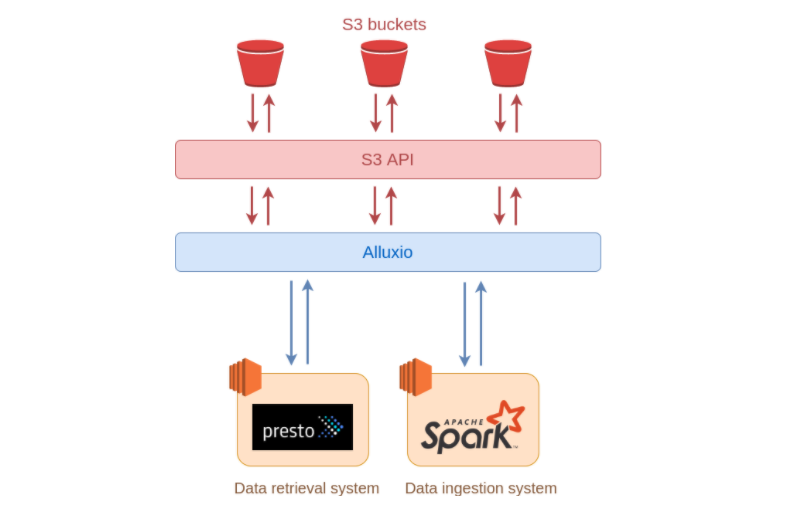
Alluxio enables data orchestration for compute in any cloud. It unifies data silos on-premise and across cloud environments to provide the data locality, accessibility, and elasticity needed to reduce the complexities associated with orchestrating data for today’s big data and AI/ML workloads.
Alluxio is designed to help any framework access any data, from any storage at high performance regardless of the environment, which enables an organization to remain agile and competitive in adopting and experimenting with new and existing technologies.