This article is part of our “Advanced Git” series. Be sure to follow Tower on Twitter or sign up for their newsletter to hear about the next articles.
Interactive Rebase is the Swiss Army knife of Git commands: lots of use cases and lots of possibilities! It’s really a great addition to any developer’s tool chain, because it lets you revise your local commit history—before you share your work with the rest of the team.
Let’s see what you can do with an interactive rebase and then look at some practical examples.
Advanced Git series:
- Part 1: Creating the Perfect Commit in Git
- Part 2: Branching Strategies in Git
- Part 3: Better Collaboration With Pull Requests
- Part 4: Merge Conflicts
- Part 5: Rebase vs. Merge
- Part 6: Interactive Rebase (You are here!)
- Part 7: Cherry-Picking Commits in Git (Coming soon!)
- Part 8: Using the Reflog to Restore Lost Commits
Rewriting your commit history
In short, interactive rebase allows you to manipulate your commit history. It’s meant for optimizing and cleaning up. You can…
- change commit messages
- combine multiple commits
- split and edit existing commits
- reorder commits
- delete commits
Keep in mind that an interactive rebase rewrites your commit history: all of the involved commits get a new hash ID. Also, a quick reminder: commit IDs are there to identify commits—they are SHA-1 checksums. So, by changing that hash, you technically create completely new commits. This means that you shouldn’t use an interactive rebase on stuff that you’ve already pushed to a shared remote repository. Your colleagues might have based their work on these commits—and when you use interactive rebase to rewrite commit history, you are changing these base commits.
All of this means that an interactive rebase is meant to help you clean up and optimize your own local commit history before you merge (and possibly push) it back into a shared team branch.
Interactive rebase workflow
Before we take interactive rebase for a test drive, let’s look at the general workflow. This is always the same, no matter what exactly we’re doing—deleting a commit, changing a commit message, combining commits… the steps are identical.
The first step is to determine the range of commits you want to manipulate. How far back in time do you want to go? Once you have the answer, you can start your interactive rebase session. Here, you have the chance to edit your commit history. For example, you can manipulate the selected commits by reordering, deleting, combining them, and so on.
In your first step, you are always going to look at the current state of the commit history. You can use the git log command to examine a project’s history and show the commit log.
Here’s the little example repository we’re going to use throughout this article:

After you’ve examined the list, it’s time to start the work. Let’s do this step-by-step. In the examples of this article, we will do the following things:
- First, we change an old commit’s message.
- Secondly, we combine two old commits.
- After that, we split one commit.
- Finally, we delete a commit.
Change a commit message
In many cases, you’ll want to change the most recent commit. Keep in mind that there’s a shortcut for this scenario which doesn’t involve interactive rebase:
$ git commit --amendThis command can modify both the content and the message of the most recent commit, and it opens your default text editor. Here you can make your changes, save them, and quit the editor. This will not only update the commit message, but will effectively change the commit itself and write a new one.
Again, please be careful and don’t amend your last commit if you’ve already pushed it to the remote repository!
For any other commit (anything older than the most recent one), you have to perform an interactive rebase. To run git rebase interactively, add the -i option.
The first step is to determine the base commit: the parent commit of the one you want to change. You can achieve this by using the commit’s hash ID or by doing a little bit of counting. To change the last three commit messages (or at least one of them), you can define the parent commit like this:
$ git rebase -i HEAD~3An editor window opens and you can see all three commits you selected (and by “selected” I mean a range of commits: from HEAD all the way down to HEAD~3). Please notice the reverse order: unlike git log, this editor shows the oldest commit (HEAD~3) at the top and the newest at the bottom.

In this window you don’t actually change the commit message. You only tell Git what kind of manipulation you want to perform. Git offers a series of keywords for this—in our case, we change the word pick to reword which allows us to change the commit messages. After saving and closing the editor, Git will show the actual commit message and you can change it. Save and exit again, that’s it!
Combining two commits
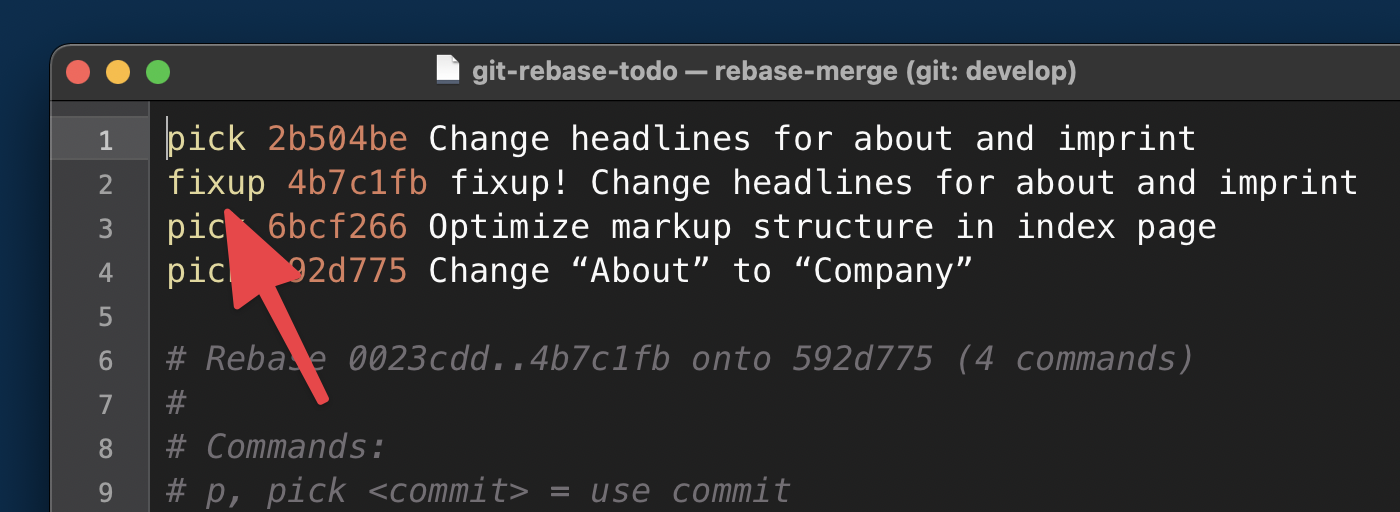
In this next example, we’ll combine the two commits—“7b2317cf Change the page structure” and “6bcf266 Optimize markup”—so that they become one single commit. Again, as a first step you need to determine the base commit. And again, we have to go back to at least the parent commit:
$ git rebase -i HEAD~3The editor window opens again, but instead of reword, we’ll enter squash. To be exact, we replace pick with squash in line 2 to combine it with line 1. This is an important bit to keep in mind: the squash keyword combines the line you mark up with the line above it!

After saving the changes and closing the window, a new editor window pops up. Why’s that? By combining two commits we are creating… well… a new commit! And this new commit wants a commit message. Enter the message, save and close the window… and you’ve successfully combined the two commits. Powerful stuff!
Finally a little “pro tip” for those of you working with the “Tower” Git desktop GUI: to perform a squash, you can simply drag and drop commits onto each other, right in the commits view. And if you want to change a commit message, simply right click the commit in question and select “Edit commit message” from the contextual menu.

Deleting a commit
We’re bringing in the big guns for our final example: we are going to delete a revision from our commit history! To do this, we’re using the drop keyword to mark up the commit we want to get rid of:
drop 0023cdd Add simple robots.txt
pick 2b504be Change headlines for about and imprint
pick 6bcf266 Optimizes markup structure in index pageThis is probably a good moment to answer a question you might have had for some time now: what can you do if you’re in the middle of a rebase operation and think, “Oh, no, this wasn’t such a good idea after all”? No problem—you can always abort! Just enter the following command to turn back to the state your repository was in before you initiated the rebase:
$ git rebase --abortChanging the past
These were just a few examples of what an interactive rebase can do. There are plenty of other possibilities to control and revise your local commit history.
If you want to dive deeper into advanced Git tools, feel free to check out my (free!) “Advanced Git Kit”: it’s a collection of short videos about topics like branching strategies, Interactive Rebase, Reflog, Submodules and much more.
Happy rebasing and hacking—and see you soon for the next part in our series on “Advanced Git”!
Advanced Git series:
- Part 1: Creating the Perfect Commit in Git
- Part 2: Branching Strategies in Git
- Part 3: Better Collaboration With Pull Requests
- Part 4: Merge Conflicts
- Part 5: Rebase vs. Merge
- Part 6: Interactive Rebase (You are here!)
- Part 7: Cherry-Picking Commits in Git (Coming soon!)
- Part 8: Using the Reflog to Restore Lost Commits
The post Interactive Rebase: Clean up your Commit History appeared first on CSS-Tricks. You can support CSS-Tricks by being an MVP Supporter.