The current landscape of web tooling is increasingly more complex than ever before. We have libraries such as Solid, Vue, Svelte, Angular, React, and others that handle UI (User Interface) updates in an ergonomic fashion. The ever more important topic weighing on developers is the balance and trade-off of performance and usability best practices.
Developers are also blurring the lines between front-end and back-end code. The way we colocate logic and data is becoming more interesting as we integrate and mesh the way they work together to deliver a unified app experience.
With these shifts in ideology in mind, meta-frameworks have evolved around the core libraries in unique ways. To encapsulate the paradigms in which the UI is rendered and create seamless interoperability between our server code and our browser code, new practices are emerging.
While the initial idea of having a “meta” framework was to stitch together different sets of tools in order to build smooth experiences, it is tough to create integrations without making some level of opinionated decisions. So frameworks such as QwikCity, SvelteKit, Redwood, and Next.js went all the way into their own opinionated territory and provided a hard railway to ensure a defined set of conventions.
Meanwhile, others like Nuxt, Remix, and Analog stayed with a more shallow abstraction of their integrations, allowing a mix of their toolings and more easily using resources from the community (Vite is a good example of a tool that is shallowly used by all of them).
This not only produces a lower vendor lock-in to developers but also allows configuration to be re-used in some cases as such decisions are stripped out of opinions in favor of stronger abstractions. SolidStart takes a giant step beyond that into unbiased territory. Its own core is around 1500 lines of code, and the biggest pieces of functionality are provided with a meshing of well-integrated tools.
Modules Over MonolithsThe impetus behind decoupling the architecture completely is to give power to the consuming developer to pick the framework and build it according to their desire. A developer may want to use Solid and SSR, but let’s imagine legacy code has a tight dependency on TanStack Router, while SolidStart and most Solid projects have Solid-Router instead. With a decoupled architecture, it becomes possible to either create an incremental adoption or integration layer so that everything will work tailored to the team’s best benefit.
The decoupled architecture sustaining newer frameworks also empowers the developer for a better debugging experience within and beyond its community. If an issue is encountered on the server, you’re not restricted to the knowledge of a specific framework.
For example, since both are based on Nitro, the Analog and SolidStart communities can now share knowledge with each other. Beyond that, because all of them are based in Nitro and Vite, Nuxt, Analog, and SolidStart can deploy to the same platforms and share implementation details to make each ecosystem grow together. The community wins with this approach, and the library/framework developers win as well. This is a radically new pattern and approach to jointly sharing the weight of meta-framework maintenance (one of the most feared responsibilities of maintainers).
What Is SolidStart Exactly?SolidStart is built from five fundamental pillars:
- Solid: the view library that provides rendering abstractions.
- Vite (within Vinxi): the bundler to optimize code for execution in different runtimes.
- Nitro (within Vinxi): the agnostic web server created by the Nuxt team and based on h3 with Rollup.
- Vinxi: the orchestrator, what determines where the runtimes and the code each one has.
- Seroval: the data serializer that will bridge data from server to browser and back.

Solid as a rendering library has become increasingly popular because of its incredible rendering performance and thin abstraction layer. It’s built on top of Signals, a renewing and modern implementation of the classical Observer Pattern, and provides a series of helpers to empower the developer to create extremely high-performance and easy-to-read code.
It uses JSX and has syntax that is very similar to React, but under the hood, it operates in a completely different manner. Bringing the developer closer to the DOM while still providing the needed ergonomics to be productive in the developer environment. At only 3Kb of bundle size, it’s often a choice even for mostly static sites. e.g., many people use Solid to bring interactivity to their content-based Astro websites when needed.
Solid also brings first-class primitives, built-in Control Flow components, high-quality state management, and full TypeScript support. Solid packs a punch in a small efficient package.
2. ViteArguably the best bundler in the JavaScript ecosystem, Vite has the right balance between declarative and customizable configuration. It’s fully based on TypeScript, which makes it easy to extend by the consuming library or framework, and has a large enough user base that guarantees its versatility. Vite works with and has become the de-facto tool for many frameworks, such as Astro, Vue, Preact, Elm, Lit, Svelte, Nuxt, Analog, Remix, and many others.
Aside from its popularity, it is particularly loved for its fast server start time, HMR support, optimized builds, ease of configuration, rich plug-in ecosystem, modern tooling, and high-quality overall developer experience.
3. NitroA framework in itself, Nitro is written in TypeScript and is completely agnostic and open for every meta-framework to use as a foundation. It provides a powerful set of tools and APIs to manage caching, routes, and tree-shaking. It is a fast base for any JavaScript-based project to build their server on. Nitro is highly scalable, integrating easily into DevOps and CI/CD pipelines, security-focused, robust, and boasts a rich set of adapters, making it deployable on most, if not all, major vendor platforms.
Think of Nitro as a bolt-on extension that makes Vite easier to build on and more pliable. It solves a majority of run-time level concerns that would need to be solved in Vite.
4. VinxiVinxi is an SDK (Software Development Kit) that brings a powerful set of configuration-based tools to create full-stack applications. It composes Nitro under the hood to establish a web server and leverages Vite for the bundling components. It is inspired by the Bun App API and works via a very declarative interface to instantiate an app by setting routers for each runtime.
For example:
import { createApp } from "vinxi";
import solid from "vite-plugin-solid";
const resources = {
name: "public",
mode: "static",
dir: "./public",
};
const spa = {
name: "client",
mode: "build",
handler: "./app/client.tsx",
target: "browser",
plugins: () => [solid({ ssr: true })],
base: "/_build"
}
const server = {
name: "ssr",
mode: "handler",
handler: "./app/server.tsx",
target: "server",
plugins: () => [solid({ ssr: true })],
}
export default createApp({
routers: [resources, spa, server],
});
As resource routes work as a bucket, by defining mode: "static" there’s no need to define a handler. Your router can also be statically built (mode: “build”) and targeted towards the browser runtime, or it can be on the server and handle each request via its entry-point handler: "./app/server.tsx".
Vinxi will leverage the right set of APIs from Nitro and Vite so your resources aren’t exposed to the wrong runtimes and so that deployment works smoothly for defined platform providers.
5. SerovalOnce routers are set, and the app can handle navigation (hard navigation via the “ssr” handler and soft navigation via the “client” handler), it’s time to stitch them together. This is the part where SolidStart’s core comes into place. It supplies APIs that deliver the ergonomics to fetch and mutate requests.
All these APIs are powered by yet another agnostic library called Seroval. In order to send data between server and client in a secure manner, it all needs to be serialized. Seroval defines itself in an over-simplistic way: “Stringify JS Values.” However, this definition doesn’t address the fact it does so in an extremely powerful and fast fashion.
Thanks to Seroval, SolidStart is able to safely and efficiently cross the serialization boundary. Resource serialization is arguably the most important feature of a full-stack framework — without it, the back-end and front-end bridge simply won’t work in a smooth way.
Besides resource serialization, SolidStart can also use server actions. Straight from the documentation, this is how server actions look for us (note the "use server" directive that allows Vinxi to put the code in the correct place.
import { action, redirect } from "@solidjs/router";
const isAdmin = action(async (formData: FormData) => {
"use server";
await new Promise((resolve, reject) => setTimeout(resolve, 1000));
const username = formData.get("username");
if (username === "admin") throw redirect("/admin");
return new Error("Invalid username");
});
export function MyComponent() {
return (
<form action={isAdmin} method="post">
<label for="username">Username:</label>
<input type="text" name="username" />
<input type="submit" value="submit" />
</form>
);
}
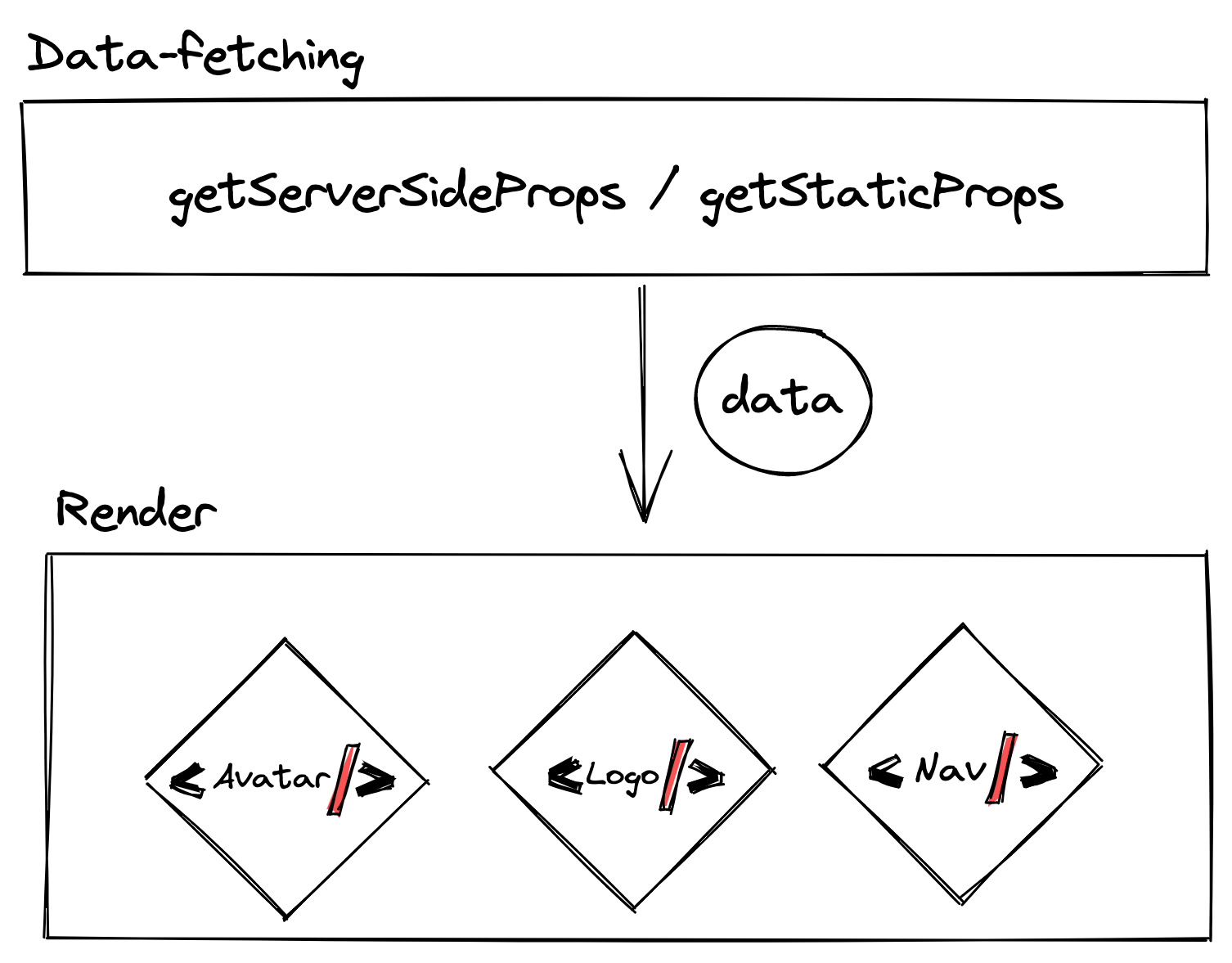
After this breakdown, things may still be a bit up in the air. So, let’s close the loop by assembling the parts:

Hopefully, this little exercise of pulling the framework apart and putting the pieces back together was interesting and insightful. Let me know in the comments below or on X if this has helped you better understand or even choose the tools for your next project.
Final ConsiderationsThis article would not have been possible without the technical help from my awesome folks at Solid’s team: Dave Di Biase, Alexis Munsayac, Alex Lohr, Daniel Afonso, and Nikhil Saraf. Thank you for your reviews, insights, and overall making me sound cleverer!