Measuring and tracking the progress of any program is key to success, as quoted in the famous saying:
If you can’t measure it, you can’t improve it.

Tips, Expertise, Articles and Advice from the Pro's for Your Website or Blog to Succeed

Measuring and tracking the progress of any program is key to success, as quoted in the famous saying:
If you can’t measure it, you can’t improve it.
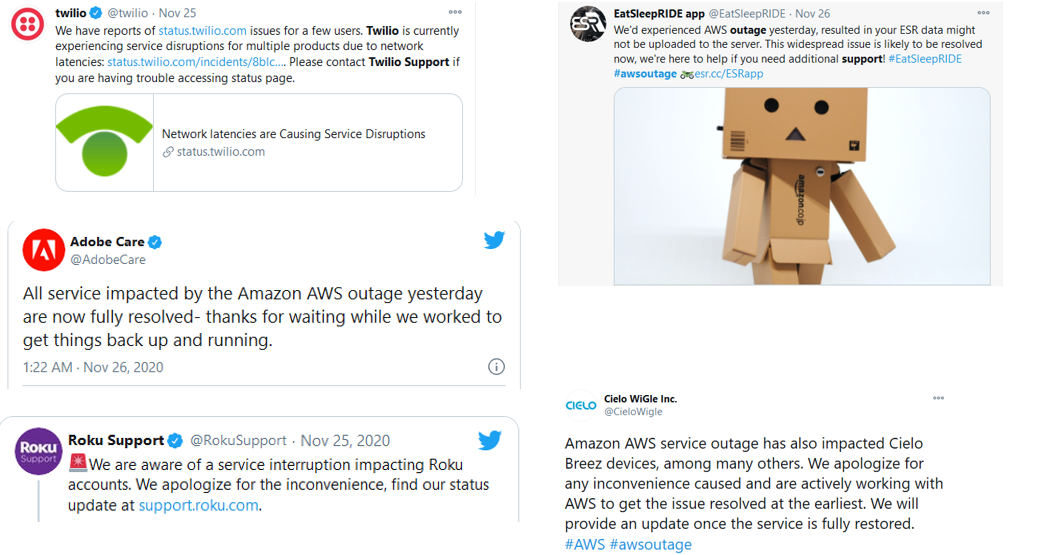
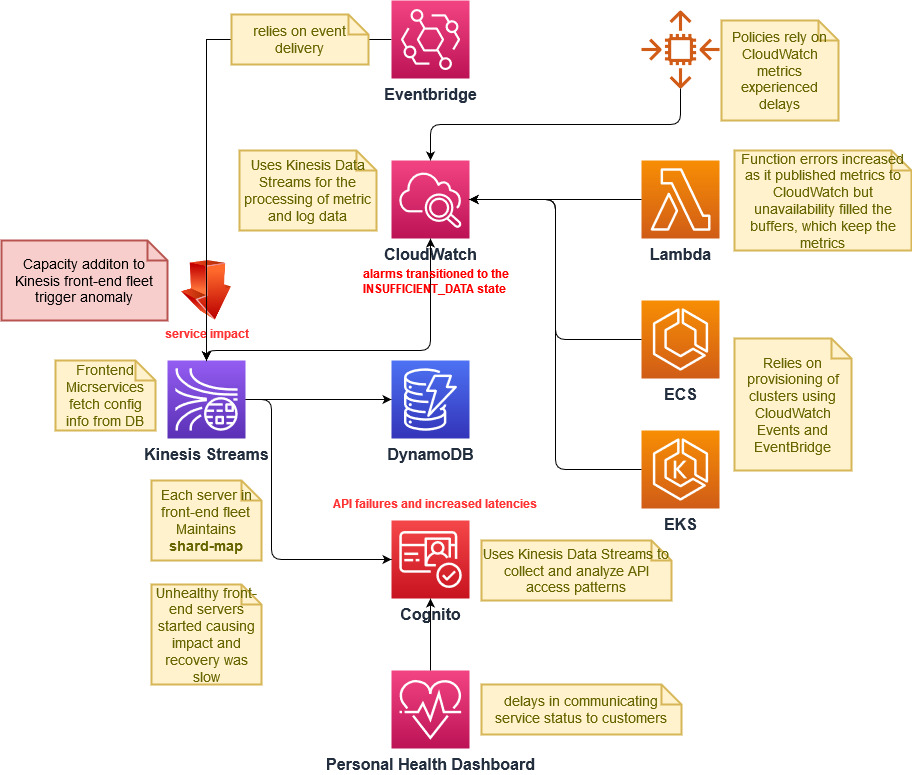
To conclude, being proactive when outages occur, having a response team equipped for unplanned outages, and improving continuously from lessons learned along the way are essential techniques to help keep the impact limited. Also, having a multi-cloud or hybrid-cloud strategy is food for thought to keep the business running.
The current technological landscape for cloud-native apps is evolving and Platform-as-a-Service (PaaS) solutions are constantly changing to meet the demand of cloud-native architecture. As flexibility and openness in terms of choosing a PaaS solution (without any vendor or technology lock-in) play a larger role, some key questions include:
This blog is an attempt to establish a reference architecture for cloud-native architecture and help enterprise architects to choose the right technology solution for each building block.