The fast evolution of digital platforms have placed serious limitations on traditional CMS like Wordpress. These platforms are coupled, inflexible and are focused on the project, rather than the product. Thankfully, several headless CMS have been developed to tackle these challenges and many more.
Unlike traditional CMS, headless CMS, which can be described as Software as a Service (SaaS), can be used to develop websites, mobile apps, digital displays, and many more. They can be used on limitless platforms. If you are looking for a CMS that is platform independent, developer-first, and offers cross platform support, you need not look farther from headless CMS.
A headless CMS is simply a CMS without a head. The head here refers to the frontend or the presentation layer while the body refers to the backend or the content repository. This offers a lot of interesting benefits. For instance, it allows the developer to choose any frontend of his choice and you can also design the presentation layer as you want.
There are lots of headless CMS out there, some of the most popular ones include Strapi, Contentful, Contentstack, Sanity, Butter CMS, Prismic, Storyblok, Directus, etc. These headless CMS are API-based and have their individual strong points. For instance, CMS like Sanity, Strapi, Contentful, and Storyblok are free for small projects.
These headless CMS are based on different tech stacks as well. While Sanity.io is based on React.js, Storyblok is based on Vue.js. As a React developer, this is the major reason why I quickly picked interest in Sanity. However, being a headless CMS, each of these platforms can be plugged on any frontend, whether Angular, Vue or React.
Each of these headless CMS has both free and paid plans which represent significant price jump. Although these paid plans offer more features, you wouldn’t want to pay all that much for a small to mid-sized project. Sanity tries to solve this problem by introducing pay-as-you-go options. With these options, you will be able to pay for what you use and avoid the price jump.
Another reason why I choose Sanity.io is their GROQ language. For me, Sanity stands out from the crowd by offering this tool. Graphical-Relational Object Queries (GROQ) reduces development time, helps you get the content you need in the form you need it, and also helps the developer to create a document with a new content model without code changes.
Moreover, developers are not constrained to the GROQ language. You can also use GraphQL or even the traditional axios and fetch in your React app to query the backend. Like most other headless CMS, Sanity has comprehensive documentation that contains helpful tips to build on the platform.
Note: This article requires a basic understanding of React, Redux and CSS.
Getting Started With Sanity.io
To use Sanity in your machine, you’ll need to install the Sanity CLI tool. While this can be installed locally on your project, it is preferable to install it globally to make it accessible to any future applications.
To do this, enter the following commands in your terminal.
npm install -g @sanity/cli
The -g flag in the above command enables global installation.
Next, we need to initialize Sanity in our application. Although this can be installed as a separate project, it is usually preferable to install it within your frontend app (in this case React).
In her blog, Kapehe explained in detail how to integrate Sanity with React. It will be helpful to go through the article before continuing with this tutorial.
Enter the following commands to initialize Sanity in your React app.
sanity init
The sanity command becomes available to us when we installed the Sanity CLI tool. You can view a list of the available Sanity commands by typing sanity or sanity help in your terminal.
When setting up or initializing your project, you’ll need to follow the prompts to customize it. You’ll also be required to create a dataset and you can even choose their custom dataset populated with data. For this listing app, we will be using Sanity’s custom sci-fi movies dataset. This will save us from entering the data ourselves.
To view and edit your dataset, cd to the Sanity subdirectory in your terminal and enter sanity start. This usually runs on http://localhost:3333/. You may be required to login to access the interface (make sure you login with the same account you used when initializing the project). A screenshot of the environment is shown below.
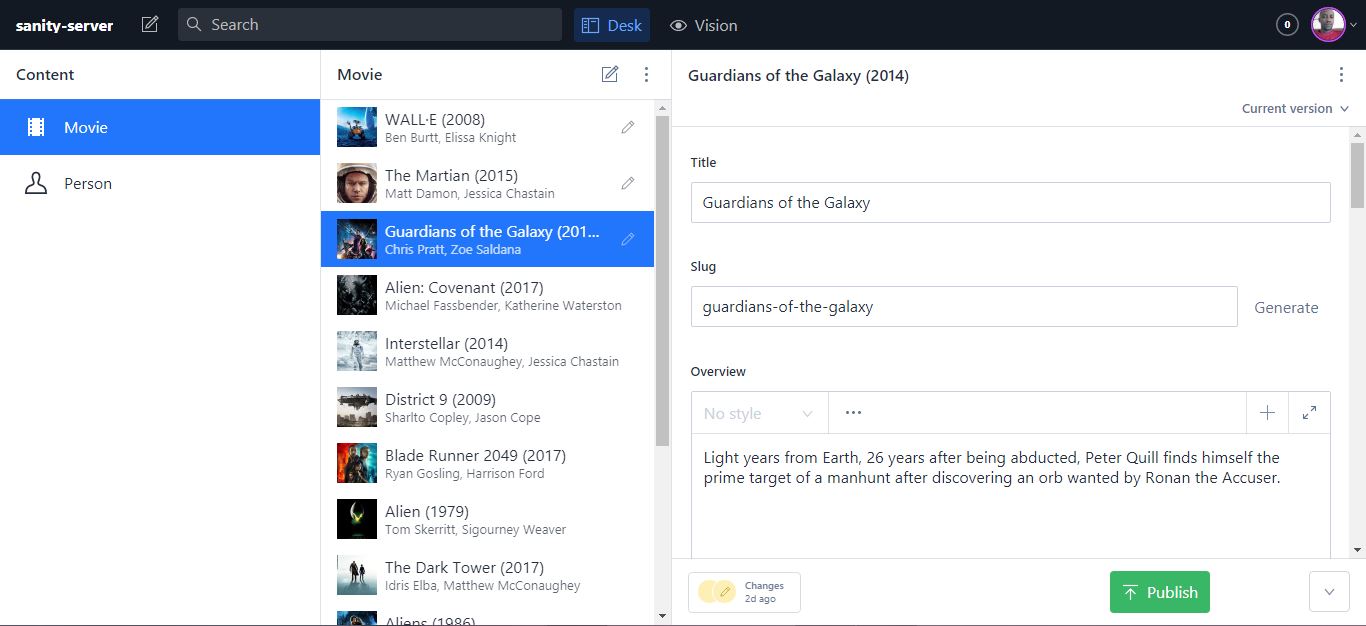
Sanity-React Two-way Communication
Sanity and React need to communicate with each other for a fully functional application.
CORS Origins Setting In Sanity Manager
We’ll first connect our React app to Sanity. To do this, login to https://manage.sanity.io/ and locate CORS origins under API Settings in the Settings tab. Here, you’ll need to hook your frontend origin to the Sanity backend. Our React app runs on http://localhost:3000/ by default, so we need to add that to the CORS.
This is shown in the figure below.
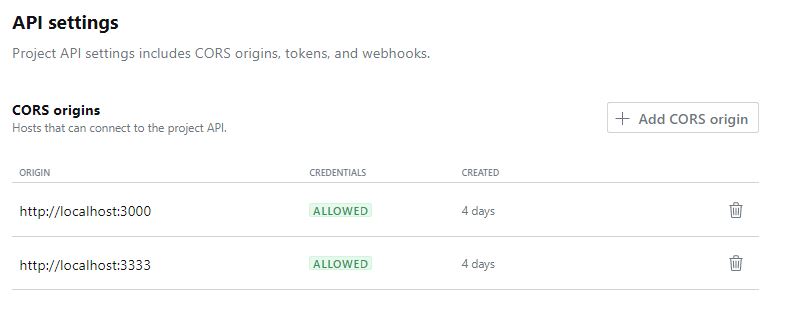
Connecting Sanity To React
Sanity associates a project ID to every project you create. This ID is needed when connecting it to your frontend application. You can find the project ID in your Sanity Manager.
The backend communicates with React using a library known as sanity client. You need to install this library in your Sanity project by entering the following commands.
npm install @sanity/client
Create a file sanitySetup.js (the filename does not matter), in your project src folder and enter the following React codes to set up a connection between Sanity and React.
import sanityClient from "@sanity/client"
export default sanityClient({
projectId: PROJECT_ID,
dataset: DATASET_NAME,
useCdn: true
});
We passed our projectId, dataset name and a boolean useCdn to the instance of the sanity client imported from @sanity/client. This works the magic and connects our app to the backend.
Now that we’ve completed the two-way connection, let’s jump right in to build our project.
Setting Up And Connecting Redux To Our App
We’ll need a few dependencies to work with Redux in our React app. Open up your terminal in your React environment and enter the following bash commands.
npm install redux react-redux redux-thunk
Redux is a global state management library that can be used with most frontend frameworks and libraries such as React. However, we need an intermediary tool react-redux to enable communication between our Redux store and our React application. Redux thunk will help us to return a function instead of an action object from Redux.
While we could write the entire Redux workflow in one file, it is often neater and better to separate our concerns. For this, we will divide our workflow into three files namely, actions, reducers, and then the store. However, we also need a separate file to store the action types, also known as constants.
Setting Up The Store
The store is the most important file in Redux. It organizes and packages the states and ships them to our React application.
Here is the initial setup of our Redux store needed to connect our Redux workflow.
import { createStore, applyMiddleware } from "redux";
import thunk from "redux-thunk";
import reducers from "./reducers/";
export default createStore(
reducers,
applyMiddleware(thunk)
);
The createStore function in this file takes three parameters: the reducer (required), the initial state and the enhancer (usually a middleware, in this case, thunk supplied through applyMiddleware). Our reducers will be stored in a reducers folder and we’ll combine and export them in an index.js file in the reducers folder. This is the file we imported in the code above. We’ll revisit this file later.
Introduction To Sanity’s GROQ Language
Sanity takes querying on JSON data a step further by introducing GROQ. GROQ stands for Graph-Relational Object Queries. According to Sanity.io, GROQ is a declarative query language designed to query collections of largely schema-less JSON documents.
Sanity even provides the GROQ Playground to help developers become familiar with the language. However, to access the playground, you need to install sanity vision.
Run sanity install @sanity/vision on your terminal to install it.
GROQ has a similar syntax to GraphQL but it is more condensed and easier to read. Furthermore, unlike GraphQL, GROQ can be used to query JSON data.
For instance, to retrieve every item in our movie document, we’ll use the following GROQ syntax.
*[_type == "movie"]
However, if we wish to retrieve only the _ids and crewMembers in our movie document. We need to specify those fields as follows.
`*[_type == 'movie']{
_id,
crewMembers
}
Here, we used * to tell GROQ that we want every document of _type movie. _type is an attribute under the movie collection. We can also return the type like we did the _id and crewMembers as follows:
*[_type == 'movie']{
_id,
_type,
crewMembers
}
We’ll work more on GROQ by implementing it in our Redux actions but you can check Sanity.io’s documentation for GROQ to learn more about it. The GROQ query cheat sheet provides a lot of examples to help you master the query language.
Setting Up Constants
We need constants to track the action types at every stage of the Redux workflow. Constants help to determine the type of action dispatched at each point in time. For instance, we can track when the API is loading, fully loaded and when an error occurs.
We don’t necessarily need to define constants in a separate file but for simplicity and clarity, this is usually the best practice in Redux.
By convention, constants in Javascript are defined with uppercase. We’ll follow the best practices here to define our constants. Here is an example of a constant for denoting requests for moving movie fetching.
export const MOVIE_FETCH_REQUEST = "MOVIE_FETCH_REQUEST";
Here, we created a constant MOVIE_FETCH_REQUEST that denotes an action type of MOVIE_FETCH_REQUEST. This helps us to easily call this action type without using strings and avoid bugs. We also exported the constant to be available anywhere in our project.
Similarly, we can create other constants for fetching action types denoting when the request succeeds or fails. A complete code for the movieConstants.js is given in the code below.
export const MOVIE_FETCH_REQUEST = "MOVIE_FETCH_REQUEST";
export const MOVIE_FETCH_SUCCESS = "MOVIE_FETCH_SUCCESS";
export const MOVIE_FETCH_FAIL = "MOVIE_FETCH_FAIL";
export const MOVIES_FETCH_REQUEST = "MOVIES_FETCH_REQUEST";
export const MOVIES_FETCH_SUCCESS = "MOVIES_FETCH_SUCCESS";
export const MOVIES_FETCH_FAIL = "MOVIES_FETCH_FAIL";
export const MOVIES_FETCH_RESET = "MOVIES_FETCH_RESET";
export const MOVIES_REF_FETCH_REQUEST = "MOVIES_REF_FETCH_REQUEST";
export const MOVIES_REF_FETCH_SUCCESS = "MOVIES_REF_FETCH_SUCCESS";
export const MOVIES_REF_FETCH_FAIL = "MOVIES_REF_FETCH_FAIL";
export const MOVIES_SORT_REQUEST = "MOVIES_SORT_REQUEST";
export const MOVIES_SORT_SUCCESS = "MOVIES_SORT_SUCCESS";
export const MOVIES_SORT_FAIL = "MOVIES_SORT_FAIL";
export const MOVIES_MOST_POPULAR_REQUEST = "MOVIES_MOST_POPULAR_REQUEST";
export const MOVIES_MOST_POPULAR_SUCCESS = "MOVIES_MOST_POPULAR_SUCCESS";
export const MOVIES_MOST_POPULAR_FAIL = "MOVIES_MOST_POPULAR_FAIL";
Here we have defined several constants for fetching a movie or list of movies, sorting and fetching the most popular movies. Notice that we set constants to determine when the request is loading, successful and failed.
Similarly, our personConstants.js file is given below:
export const PERSONS_FETCH_REQUEST = "PERSONS_FETCH_REQUEST";
export const PERSONS_FETCH_SUCCESS = "PERSONS_FETCH_SUCCESS";
export const PERSONS_FETCH_FAIL = "PERSONS_FETCH_FAIL";
export const PERSON_FETCH_REQUEST = "PERSON_FETCH_REQUEST";
export const PERSON_FETCH_SUCCESS = "PERSON_FETCH_SUCCESS";
export const PERSON_FETCH_FAIL = "PERSON_FETCH_FAIL";
export const PERSONS_COUNT = "PERSONS_COUNT";
Like the movieConstants.js, we set a list of constants for fetching a person or persons. We also set a constant for counting persons. The constants follow the convention described for movieConstants.js and we also exported them to be accessible to other parts of our application.
Finally, we’ll implement light and dark mode in the app and so we have another constants file globalConstants.js. Let’s take a look at it.
export const SET_LIGHT_THEME = "SET_LIGHT_THEME";
export const SET_DARK_THEME = "SET_DARK_THEME";
Here we set constants to determine when light or dark mode is dispatched. SET_LIGHT_THEME determines when the user switches to the light theme and SET_DARK_THEME determines when the dark theme is selected. We also exported our constants as shown.
Setting Up The Actions
By convention, our actions are stored in a separate folder. Actions are grouped according to their types. For instance, our movie actions are stored in movieActions.js while our person actions are stored in personActions.js file.
We also have globalActions.js to take care of toggling the theme from light to dark mode.
Let’s fetch all movies in moviesActions.js.
import sanityAPI from "../../sanitySetup";
import {
MOVIES_FETCH_FAIL,
MOVIES_FETCH_REQUEST,
MOVIES_FETCH_SUCCESS
} from "../constants/movieConstants";
const fetchAllMovies = () => async (dispatch) => {
try {
dispatch({
type: MOVIES_FETCH_REQUEST
});
const data = await sanityAPI.fetch(
`*[_type == 'movie']{
_id,
"poster": poster.asset->url,
} `
);
dispatch({
type: MOVIES_FETCH_SUCCESS,
payload: data
});
} catch (error) {
dispatch({
type: MOVIES_FETCH_FAIL,
payload: error.message
});
}
};
Remember when we created the sanitySetup.js file to connect React to our Sanity backend? Here, we imported the setup to enable us to query our sanity backend using GROQ. We also imported a few constants exported from the movieConstants.js file in the constants folder.
Next, we created the fetchAllMovies action function for fetching every movie in our collection. Most traditional React applications use axios or fetch to fetch data from the backend. But while we could use any of these here, we’re using Sanity’s GROQ. To enter the GROQ mode, we need to call sanityAPI.fetch() function as shown in the code above. Here, sanityAPI is the React-Sanity connection we set up earlier. This returns a Promise and so it has to be called asynchronously. We’ve used the async-await syntax here, but we can also use the .then syntax.
Since we are using thunk in our application, we can return a function instead of an action object. However, we chose to pass the return statement in one line.
const fetchAllMovies = () => async (dispatch) => {
...
}
Note that we can also write the function this way:
const fetchAllMovies = () => {
return async (dispatch)=>{
...
}
}
In general, to fetch all movies, we first dispatched an action type that tracks when the request is still loading. We then used Sanity’s GROQ syntax to asynchronously query the movie document. We retrieved the _id and the poster url of the movie data. We then returned a payload containing the data gotten from the API.
Similarly, we can retrieve movies by their _id, sort movies, and get the most popular movies.
We can also fetch movies that match a particular person’s reference. We did this in the fetchMoviesByRef function.
const fetchMoviesByRef = (ref) => async (dispatch) => {
try {
dispatch({
type: MOVIES_REF_FETCH_REQUEST
});
const data = await sanityAPI.fetch(
`*[_type == 'movie'
&& (castMembers[person._ref match '${ref}'] ||
crewMembers[person._ref match '${ref}'])
]{
_id,
"poster" : poster.asset->url,
title
} `
);
dispatch({
type: MOVIES_REF_FETCH_SUCCESS,
payload: data
});
} catch (error) {
dispatch({
type: MOVIES_REF_FETCH_FAIL,
payload: error.message
});
}
};
This function takes an argument and checks if person._ref in either the castMembers or crewMembers matches the passed argument. We return the movie _id, poster url, and title alongside. We also dispatch an action of type MOVIES_REF_FETCH_SUCCESS, attaching a payload of the returned data, and if an error occurs, we dispatch an action of type MOVIE_REF_FETCH_FAIL, attaching a payload of the error message, thanks to the try-catch wrapper.
In the fetchMovieById function, we used GROQ to retrieve a movie that matches a particular id passed to the function.
The GROQ syntax for the function is shown below.
const data = await sanityAPI.fetch(
`*[_type == 'movie' && _id == '${id}']{
_id,
"cast" :
castMembers[]{
"ref": person._ref,
characterName,
"name": person->name,
"image": person->image.asset->url
}
,
"crew" :
crewMembers[]{
"ref": person._ref,
department,
job,
"name": person->name,
"image": person->image.asset->url
}
,
"overview": {
"text": overview[0].children[0].text
},
popularity,
"poster" : poster.asset->url,
releaseDate,
title
}[0]`
);
Like the fetchAllMovies action, we started by selecting all documents of type movie but we went further to select only those with an id supplied to the function. Since we intend to display a lot of details for the movie, we specified a bunch of attributes to retrieve.
We retrieved the movie id and also a few attributes in the castMembers array namely ref, characterName, the person’s name, and the person’s image. We also changed the alias from castMembers to cast.
Like the castMembers, we selected a few attributes from the crewMembers array, namely ref, department, job, the person’s name and the person’s image. we also changed the alias from crewMembers to crew.
In the same way, we selected the overview text, popularity, movie's poster url, movie's release date and title.
Sanity's GROQ language also allows us to sort a document. To sort an item, we pass order next to a pipe operator.
For instance, if we wish to sort movies by their releaseDate in ascending order, we could do the following.
const data = await sanityAPI.fetch(
`*[_type == 'movie']{
...
} | order(releaseDate, asc)`
);
We used this notion in the sortMoviesBy function to sort either by ascending or descending order.
Let’s take a look at this function below.
const sortMoviesBy = (item, type) => async (dispatch) => {
try {
dispatch({
type: MOVIES_SORT_REQUEST
});
const data = await sanityAPI.fetch(
`*[_type == 'movie']{
_id,
"poster" : poster.asset->url,
title
} | order( ${item} ${type})`
);
dispatch({
type: MOVIES_SORT_SUCCESS,
payload: data
});
} catch (error) {
dispatch({
type: MOVIES_SORT_FAIL,
payload: error.message
});
}
};
We began by dispatching an action of type MOVIES_SORT_REQUEST to determine when the request is loading. We then used the GROQ syntax to sort and fetch data from the movie collection. The item to sort by is supplied in the variable item and the mode of sorting (ascending or descending) is supplied in the variable type. Consequently, we returned the id, poster url, and title. Once the data is returned, we dispatched an action of type MOVIES_SORT_SUCCESS and if it fails, we dispatch an action of type MOVIES_SORT_FAIL.
A similar GROQ concept applies to the getMostPopular function. The GROQ syntax is shown below.
const data = await sanityAPI.fetch(
`
*[_type == 'movie']{
_id,
"overview": {
"text": overview[0].children[0].text
},
"poster" : poster.asset->url,
title
}| order(popularity desc) [0..2]`
);
The only difference here is that we sorted the movies by popularity in descending order and then selected only the first three. The items are returned in a zero-based index and so the first three items are items 0, 1 and 2. If we wish to retrieve the first ten items, we could pass [0..9] to the function.
Here’s the complete code for the movie actions in the movieActions.js file.
import sanityAPI from "../../sanitySetup";
import {
MOVIE_FETCH_FAIL,
MOVIE_FETCH_REQUEST,
MOVIE_FETCH_SUCCESS,
MOVIES_FETCH_FAIL,
MOVIES_FETCH_REQUEST,
MOVIES_FETCH_SUCCESS,
MOVIES_SORT_REQUEST,
MOVIES_SORT_SUCCESS,
MOVIES_SORT_FAIL,
MOVIES_MOST_POPULAR_REQUEST,
MOVIES_MOST_POPULAR_SUCCESS,
MOVIES_MOST_POPULAR_FAIL,
MOVIES_REF_FETCH_SUCCESS,
MOVIES_REF_FETCH_FAIL,
MOVIES_REF_FETCH_REQUEST
} from "../constants/movieConstants";
const fetchAllMovies = () => async (dispatch) => {
try {
dispatch({
type: MOVIES_FETCH_REQUEST
});
const data = await sanityAPI.fetch(
`*[_type == 'movie']{
_id,
"poster" : poster.asset->url,
} `
);
dispatch({
type: MOVIES_FETCH_SUCCESS,
payload: data
});
} catch (error) {
dispatch({
type: MOVIES_FETCH_FAIL,
payload: error.message
});
}
};
const fetchMoviesByRef = (ref) => async (dispatch) => {
try {
dispatch({
type: MOVIES_REF_FETCH_REQUEST
});
const data = await sanityAPI.fetch(
`*[_type == 'movie'
&& (castMembers[person._ref match '${ref}'] ||
crewMembers[person._ref match '${ref}'])
]{
_id,
"poster" : poster.asset->url,
title
}`
);
dispatch({
type: MOVIES_REF_FETCH_SUCCESS,
payload: data
});
} catch (error) {
dispatch({
type: MOVIES_REF_FETCH_FAIL,
payload: error.message
});
}
};
const fetchMovieById = (id) => async (dispatch) => {
try {
dispatch({
type: MOVIE_FETCH_REQUEST
});
const data = await sanityAPI.fetch(
`*[_type == 'movie' && _id == '${id}']{
_id,
"cast" :
castMembers[]{
"ref": person._ref,
characterName,
"name": person->name,
"image": person->image.asset->url
}
,
"crew" :
crewMembers[]{
"ref": person._ref,
department,
job,
"name": person->name,
"image": person->image.asset->url
}
,
"overview": {
"text": overview[0].children[0].text
},
popularity,
"poster" : poster.asset->url,
releaseDate,
title
}[0]`
);
dispatch({
type: MOVIE_FETCH_SUCCESS,
payload: data
});
} catch (error) {
dispatch({
type: MOVIE_FETCH_FAIL,
payload: error.message
});
}
};
const sortMoviesBy = (item, type) => async (dispatch) => {
try {
dispatch({
type: MOVIES_MOST_POPULAR_REQUEST
});
const data = await sanityAPI.fetch(
`*[_type == 'movie']{
_id,
"poster" : poster.asset->url,
title
} | order( ${item} ${type})`
);
dispatch({
type: MOVIES_SORT_SUCCESS,
payload: data
});
} catch (error) {
dispatch({
type: MOVIES_SORT_FAIL,
payload: error.message
});
}
};
const getMostPopular = () => async (dispatch) => {
try {
dispatch({
type: MOVIES_SORT_REQUEST
});
const data = await sanityAPI.fetch( `
*[_type == 'movie']{
_id,
"overview": {
"text": overview[0].children[0].text
},
"poster" : poster.asset->url,
title
}| order(popularity desc) [0..2]`
);
dispatch({
type: MOVIES_MOST_POPULAR_SUCCESS,
payload: data
});
} catch (error) {
dispatch({
type: MOVIES_MOST_POPULAR_FAIL,
payload: error.message
});
}
};
export {
fetchAllMovies,
fetchMovieById,
sortMoviesBy,
getMostPopular,
fetchMoviesByRef
};
Setting Up The Reducers
Reducers are one of the most important concepts in Redux. They take the previous state and determine the state changes.
Typically, we’ll be using the switch statement to execute a condition for each action type. For instance, we can return loading when the action type denotes loading, and then the payload when it denotes success or error. It is expected to take in the initial state and the action as arguments.
Our movieReducers.js file contains various reducers to match the actions defined in the movieActions.js file. However, each of the reducers has a similar syntax and structure. The only differences are the constants they call and the values they return.
Let’s start by taking a look at the fetchAllMoviesReducer in the movieReducers.js file.
import {
MOVIES_FETCH_FAIL,
MOVIES_FETCH_REQUEST,
MOVIES_FETCH_SUCCESS,
} from "../constants/movieConstants";
const fetchAllMoviesReducer = (state = {}, action) => {
switch (action.type) {
case MOVIES_FETCH_REQUEST:
return {
loading: true
};
case MOVIES_FETCH_SUCCESS:
return {
loading: false,
movies: action.payload
};
case MOVIES_FETCH_FAIL:
return {
loading: false,
error: action.payload
};
case MOVIES_FETCH_RESET:
return {};
default:
return state;
}
};
Like all reducers, the fetchAllMoviesReducer takes the initial state object (state) and the action object as arguments. We used the switch statement to check the action types at each point in time. If it corresponds to MOVIES_FETCH_REQUEST, we return loading as true to enable us to show a loading indicator to the user.
If it corresponds to MOVIES_FETCH_SUCCESS, we turn off the loading indicator and then return the action payload in a variable movies. But if it is MOVIES_FETCH_FAIL, we also turn off the loading and then return the error. We also want the option to reset our movies. This will enable us to clear the states when we need to do so.
We have the same structure for other reducers. The complete movieReducers.js is shown below.
import {
MOVIE_FETCH_FAIL,
MOVIE_FETCH_REQUEST,
MOVIE_FETCH_SUCCESS,
MOVIES_FETCH_FAIL,
MOVIES_FETCH_REQUEST,
MOVIES_FETCH_SUCCESS,
MOVIES_SORT_REQUEST,
MOVIES_SORT_SUCCESS,
MOVIES_SORT_FAIL,
MOVIES_MOST_POPULAR_REQUEST,
MOVIES_MOST_POPULAR_SUCCESS,
MOVIES_MOST_POPULAR_FAIL,
MOVIES_FETCH_RESET,
MOVIES_REF_FETCH_REQUEST,
MOVIES_REF_FETCH_SUCCESS,
MOVIES_REF_FETCH_FAIL
} from "../constants/movieConstants";
const fetchAllMoviesReducer = (state = {}, action) => {
switch (action.type) {
case MOVIES_FETCH_REQUEST:
return {
loading: true
};
case MOVIES_FETCH_SUCCESS:
return {
loading: false,
movies: action.payload
};
case MOVIES_FETCH_FAIL:
return {
loading: false,
error: action.payload
};
case MOVIES_FETCH_RESET:
return {};
default:
return state;
}
};
const fetchMoviesByRefReducer = (state = {}, action) => {
switch (action.type) {
case MOVIES_REF_FETCH_REQUEST:
return {
loading: true
};
case MOVIES_REF_FETCH_SUCCESS:
return {
loading: false,
movies: action.payload
};
case MOVIES_REF_FETCH_FAIL:
return {
loading: false,
error: action.payload
};
default:
return state;
}
};
const fetchMovieByIdReducer = (state = {}, action) => {
switch (action.type) {
case MOVIE_FETCH_REQUEST:
return {
loading: true
};
case MOVIE_FETCH_SUCCESS:
return {
loading: false,
movie: action.payload
};
case MOVIE_FETCH_FAIL:
return {
loading: false,
error: action.payload
};
default:
return state;
}
};
const sortMoviesByReducer = (state = {}, action) => {
switch (action.type) {
case MOVIES_SORT_REQUEST:
return {
loading: true
};
case MOVIES_SORT_SUCCESS:
return {
loading: false,
movies: action.payload
};
case MOVIES_SORT_FAIL:
return {
loading: false,
error: action.payload
};
default:
return state;
}
};
const getMostPopularReducer = (state = {}, action) => {
switch (action.type) {
case MOVIES_MOST_POPULAR_REQUEST:
return {
loading: true
};
case MOVIES_MOST_POPULAR_SUCCESS:
return {
loading: false,
movies: action.payload
};
case MOVIES_MOST_POPULAR_FAIL:
return {
loading: false,
error: action.payload
};
default:
return state;
}
};
export {
fetchAllMoviesReducer,
fetchMovieByIdReducer,
sortMoviesByReducer,
getMostPopularReducer,
fetchMoviesByRefReducer
};
We also followed the exact same structure for personReducers.js. For instance, the fetchAllPersonsReducer function defines the states for fetching all persons in the database.
This is given in the code below.
import {
PERSONS_FETCH_FAIL,
PERSONS_FETCH_REQUEST,
PERSONS_FETCH_SUCCESS,
} from "../constants/personConstants";
const fetchAllPersonsReducer = (state = {}, action) => {
switch (action.type) {
case PERSONS_FETCH_REQUEST:
return {
loading: true
};
case PERSONS_FETCH_SUCCESS:
return {
loading: false,
persons: action.payload
};
case PERSONS_FETCH_FAIL:
return {
loading: false,
error: action.payload
};
default:
return state;
}
};
Just like the fetchAllMoviesReducer, we defined fetchAllPersonsReducer with state and action as arguments. These are standard setup for Redux reducers. We then used the switch statement to check the action types and if it’s of type PERSONS_FETCH_REQUEST, we return loading as true. If it’s PERSONS_FETCH_SUCCESS, we switch off loading and return the payload, and if it’s PERSONS_FETCH_FAIL, we return the error.
Combining Reducers
Redux's combineReducers function allows us to combine more than one reducer and pass it to the store. We'll combine our movies and persons reducers in an index.js file within the reducers folder.
Let’s take a look at it.
import { combineReducers } from "redux";
import {
fetchAllMoviesReducer,
fetchMovieByIdReducer,
sortMoviesByReducer,
getMostPopularReducer,
fetchMoviesByRefReducer
} from "./movieReducers";
import {
fetchAllPersonsReducer,
fetchPersonByIdReducer,
countPersonsReducer
} from "./personReducers";
import { toggleTheme } from "./globalReducers";
export default combineReducers({
fetchAllMoviesReducer,
fetchMovieByIdReducer,
fetchAllPersonsReducer,
fetchPersonByIdReducer,
sortMoviesByReducer,
getMostPopularReducer,
countPersonsReducer,
fetchMoviesByRefReducer,
toggleTheme
});
Here we imported all the reducers from the movies, persons, and global reducers file and passed them to combineReducers function. The combineReducers function takes an object which allows us to pass all our reducers. We can even add an alias to the arguments in the process.
We’ll work on the globalReducers later.
We can now pass the reducers in the Redux store.js file. This is shown below.
import { createStore, applyMiddleware } from "redux";
import thunk from "redux-thunk";
import reducers from "./reducers/index";
export default createStore(reducers, initialState, applyMiddleware(thunk));
Having set up our Redux workflow, let’s set up our React application.
Setting Up Our React Application
Our react application will list movies and their corresponding cast and crewmembers. We will be using react-router-dom for routing and styled-components for styling the app. We’ll also use Material UI for icons and some UI components.
Enter the following bash command to install the dependencies.
npm install react-router-dom @material-ui/core @material-ui/icons query-string
Here’s what we’ll be building:
Connecting Redux To Our React App
React-redux ships with a Provider function that allows us to connect our application to the Redux store. To do this, we have to pass an instance of the store to the Provider. We can do this either in our index.js or App.js file.
Here’s our index.js file.
import React from "react";
import ReactDOM from "react-dom";
import "./index.css";
import App from "./App";
import { Provider } from "react-redux";
import store from "./redux/store";
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById("root")
);
Here, we imported Provider from react-redux and store from our Redux store. Then we wrapped our entire components tree with the Provider, passing the store to it.
Next, we need react-router-dom for routing in our React application. react-router-dom comes with BrowserRouter, Switch and Route that can be used to define our path and routes.
We do this in our App.js file. This is shown below.
import React from "react";
import Header from "./components/Header";
import Footer from "./components/Footer";
import { BrowserRouter as Router, Switch, Route } from "react-router-dom";
import MoviesList from "./pages/MoviesListPage";
import PersonsList from "./pages/PersonsListPage";
function App() {
return (
<Router>
<main className="contentwrap">
<Header />
<Switch>
<Route path="/persons/">
<PersonsList />
</Route>
<Route path="/" exact>
<MoviesList />
</Route>
</Switch>
</main>
<Footer />
</Router>
);
}
export default App;
This is a standard setup for routing with react-router-dom. You can check it out in their documentation. We imported our components Header, Footer, PersonsList and MovieList. We then set up the react-router-dom by wrapping everything in Router and Switch.
Since we want our pages to share the same header and footer, we had to pass the <Header /> and <Footer /> component before wrapping the structure with Switch. We also did a similar thing with the main element since we want it to wrap the entire application.
We passed each component to the route using Route from react-router-dom.
Defining Our Pages And Components
Our application is organized in a structured way. Reusable components are stored in the components folder while Pages are stored in the pages folder.
Our pages comprise movieListPage.js, moviePage.js, PersonListPage.js and PersonPage.js. The MovieListPage.js lists all the movies in our Sanity.io backend as well as the most popular movies.
To list all the movies, we simply dispatch the fetchAllMovies action defined in our movieAction.js file. Since we need to fetch the list as soon as the page loads, we have to define it in the useEffect. This is shown below.
import React, { useEffect } from "react";
import { fetchAllMovies } from "../redux/actions/movieActions";
import { useDispatch, useSelector } from "react-redux";
const MoviesListPage = () => {
const dispatch = useDispatch();
useEffect(() => {
dispatch(fetchAllMovies());
}, [dispatch]);
const { loading, error, movies } = useSelector(
(state) => state.fetchAllMoviesReducer
);
return (
...
)
};
export default MoviesListPage;
Thanks to the useDispatch and useSelector Hooks, we can dispatch Redux actions and select the appropriate states from the Redux store. Notice that the states loading, error and movies were defined in our Reducer functions and here selected them using the useSelector Hook from React Redux. These states namely loading, error and movies become available immediately we dispatched the fetchAllMovies() actions.
Once we get the list of movies, we can display it in our application using the map function or however we wish.
Here is the complete code for the moviesListPage.js file.
import React, {useState, useEffect} from 'react'
import {fetchAllMovies, getMostPopular, sortMoviesBy} from "../redux/actions/movieActions"
import {useDispatch, useSelector} from "react-redux"
import Loader from "../components/BackdropLoader"
import {MovieListContainer} from "../styles/MovieStyles.js"
import SortIcon from '@material-ui/icons/Sort';
import SortModal from "../components/Modal"
import {useLocation, Link} from "react-router-dom"
import queryString from "query-string"
import {MOVIES_FETCH_RESET} from "../redux/constants/movieConstants"
const MoviesListPage = () => {
const location = useLocation()
const dispatch = useDispatch()
const [openSort, setOpenSort] = useState(false)
useEffect(()=>{
dispatch(getMostPopular())
const {order, type} = queryString.parse(location.search)
if(order && type){
dispatch({ type: MOVIES_FETCH_RESET })
dispatch(sortMoviesBy(order, type))
}else{
dispatch(fetchAllMovies())
}
}, [dispatch, location.search])
const {loading: popularLoading,
error: popularError,
movies: popularMovies
} = useSelector(state => state.getMostPopularReducer)
const { loading: moviesLoading, error: moviesError, movies
} = useSelector(state => state.fetchAllMoviesReducer)
const { loading: sortLoading, error: sortError, movies: sortMovies
} = useSelector(state => state.sortMoviesByReducer)
return (
<MovieListContainer>
<div className="mostpopular">
{
popularLoading ?
<Loader />
: popularError ? popularError :
popularMovies && popularMovies.map(movie => (
<Link to={/movie?id=${movie._id}}
className="popular" key={movie._id}
style={{backgroundImage: url(${movie.poster})}}>
<div className="content">
<h2>{movie.title}</h2>
<p>{movie.overview.text.substring(0, 50)}…</p>
</div>
</Link>
))
}
</div>
<div className="moviespanel">
<div className="top">
<h2>All Movies</h2>
<SortIcon onClick={()=> setOpenSort(true)} />
</div>
<div className="movieslist">
{
moviesLoading ? <Loader />
: moviesError ? moviesError
: movies && movies.map(movie =>(
<Link to={/movie?id=${movie._id}} key={movie._id}>
<img className="movie" src={movie.poster} alt={movie.title} />
</Link>
))
}
{
(
sortLoading ? !movies && <Loader />
: sortError ? sortError
:
sortMovies && sortMovies.map(movie =>(
<Link to={/movie?id=${movie._id}} key={movie._id}>
<img className="movie" src={movie.poster} alt={movie.title} />
</Link>
))
)
}
</div>
</div>
<SortModal
open={openSort}
setOpen={setOpenSort}
/>
</MovieListContainer>
)
}
export default MoviesListPage
We started by dispatching the getMostPopular movies action (this action selects the movies with the highest popularity) in the useEffect Hook. This allows us to retrieve the most popular movies as soon as the page loads. Additionally, we allowed users to sort movies by their releaseDate and popularity. This is handled by the sortMoviesBy action dispatched in the code above. Furthermore, we dispatched the fetchAllMovies depending on the query parameters.
Also, we used the useSelector Hook to select the corresponding reducers for each of these actions. We selected the states for loading, error and movies for each of the reducers.
After getting the movies from the reducers, we can now display them to the user. Here, we have used the ES6 map function to do this. We first displayed a loader whenever each of the movie states is loading and if there’s an error, we display the error message. Finally, if we get a movie, we display the movie image to the user using the map function. We wrapped the entire component in a MovieListContainer component.
The <MovieListContainer> … </MovieListContainer> tag is a div defined using styled components. We’ll take a brief look at that soon.
Styling Our App With Styled Components
Styled components allow us to style our pages and components on an individual basis. It also offers some interesting features such as inheritance, Theming, passing of props, etc.
Although we always want to style our pages on an individual basis, sometimes global styling may be desirable. Interestingly, styled-components provide a way to do that, thanks to the createGlobalStyle function.
To use styled-components in our application, we need to install it. Open your terminal in your react project and enter the following bash command.
npm install styled-components
Having installed styled-components, Let’s get started with our global styles.
Let’s create a separate folder in our src directory named styles. This will store all our styles. Let’s also create a globalStyles.js file within the styles folder. To create global style in styled-components, we need to import createGlobalStyle.
import { createGlobalStyle } from "styled-components";
We can then define our styles as follows:
export const GlobalStyle = createGlobalStyle`
...
`
Styled components make use of the template literal to define props. Within this literal, we can write our traditional CSS codes.
We also imported deviceWidth defined in a file named definition.js. The deviceWidth holds the definition of breakpoints for setting our media queries.
import { deviceWidth } from "./definition";
We set overflow to hidden to control the flow of our application.
html, body{
overflow-x: hidden;
}
We also defined the header style using the .header style selector.
.header{
z-index: 5;
background-color: ${(props)=>props.theme.midDarkBlue};
display:flex;
align-items:center;
padding: 0 20px;
height:50px;
justify-content:space-between;
position:fixed;
top:0;
width:100%;
@media ${deviceWidth.laptop_lg}
{
width:97%;
}
...
}
Here, various styles such as the background color, z-index, padding, and lots of other traditional CSS properties are defined.
We’ve used the styled-components props to set the background color. This allows us to set dynamic variables that can be passed from our component. Moreover, we also passed the theme’s variable to enable us to make the most of our theme toggling.
Theming is possible here because we have wrapped our entire application with the ThemeProvider from styled-components. We’ll talk about this in a moment. Furthermore, we used the CSS flexbox to properly style our header and set the position to fixed to make sure it remains fixed with respect to the browser. We also defined the breakpoints to make the headers mobile friendly.
Here is the complete code for our globalStyles.js file.
import { createGlobalStyle } from "styled-components";
import { deviceWidth } from "./definition";
export const GlobalStyle = createGlobalStyle`
html{
overflow-x: hidden;
}
body{
background-color: ${(props) => props.theme.lighter};
overflow-x: hidden;
min-height: 100vh;
display: grid;
grid-template-rows: auto 1fr auto;
}
#root{
display: grid;
flex-direction: column;
}
h1,h2,h3, label{
font-family: 'Aclonica', sans-serif;
}
h1, h2, h3, p, span:not(.MuiIconButton-label),
div:not(.PrivateRadioButtonIcon-root-8), div:not(.tryingthis){
color: ${(props) => props.theme.bodyText}
}
p, span, div, input{
font-family: 'Jost', sans-serif;
}
.paginate button{
color: ${(props) => props.theme.bodyText}
}
.header{
z-index: 5;
background-color: ${(props) => props.theme.midDarkBlue};
display: flex;
align-items: center;
padding: 0 20px;
height: 50px;
justify-content: space-between;
position: fixed;
top: 0;
width: 100%;
@media ${deviceWidth.laptop_lg}{
width: 97%;
}
@media ${deviceWidth.tablet}{
width: 100%;
justify-content: space-around;
}
a{
text-decoration: none;
}
label{
cursor: pointer;
color: ${(props) => props.theme.goldish};
font-size: 1.5rem;
}
.hamburger{
cursor: pointer;
color: ${(props) => props.theme.white};
@media ${deviceWidth.desktop}{
display: none;
}
@media ${deviceWidth.tablet}{
display: block;
}
}
}
.mobileHeader{
z-index: 5;
background-color: ${(props) =>
props.theme.darkBlue};
color: ${(props) => props.theme.white};
display: grid;
place-items: center;
width: 100%;
@media ${deviceWidth.tablet}{
width: 100%;
}
height: calc(100% - 50px);
transition: all 0.5s ease-in-out;
position: fixed;
right: 0;
top: 50px;
.menuitems{
display: flex;
box-shadow: 0 0 5px ${(props) => props.theme.lightshadowtheme};
flex-direction: column;
align-items: center;
justify-content: space-around;
height: 60%;
width: 40%;
a{
display: flex;
flex-direction: column;
align-items:center;
cursor: pointer;
color: ${(props) => props.theme.white};
text-decoration: none;
&:hover{
border-bottom: 2px solid ${(props) => props.theme.goldish};
.MuiSvgIcon-root{
color: ${(props) => props.theme.lightred}
}
}
}
}
}
footer{
min-height: 30px;
margin-top: auto;
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
font-size: 0.875rem;
background-color: ${(props) => props.theme.midDarkBlue};
color: ${(props) => props.theme.white};
}
`;
Notice that we wrote pure CSS code within the literal but there are a few exceptions. Styled-components allows us to pass props. You can learn more about this in the documentation.
Apart from defining global styles, we can define styles for individual pages.
For instance, here is the style for the PersonListPage.js defined in PersonStyle.js in the styles folder.
import styled from "styled-components";
import { deviceWidth, colors } from "./definition";
export const PersonsListContainer = styled.div`
margin: 50px 80px;
@media ${deviceWidth.tablet} {
margin: 50px 10px;
}
a {
text-decoration: none;
}
.top {
display: flex;
justify-content: flex-end;
padding: 5px;
.MuiSvgIcon-root {
cursor: pointer;
&:hover {
color: ${colors.darkred};
}
}
}
.personslist {
margin-top: 20px;
display: grid;
place-items: center;
grid-template-columns: repeat(5, 1fr);
@media ${deviceWidth.laptop} {
grid-template-columns: repeat(4, 1fr);
}
@media ${deviceWidth.tablet} {
grid-template-columns: repeat(3, 1fr);
}
@media ${deviceWidth.tablet_md} {
grid-template-columns: repeat(2, 1fr);
}
@media ${deviceWidth.mobile_lg} {
grid-template-columns: repeat(1, 1fr);
}
grid-gap: 30px;
.person {
width: 200px;
position: relative;
img {
width: 100%;
}
.content {
position: absolute;
bottom: 0;
left: 8px;
border-right: 2px solid ${colors.goldish};
border-left: 2px solid ${colors.goldish};
border-radius: 10px;
width: 80%;
margin: 20px auto;
padding: 8px 10px;
background-color: ${colors.transparentWhite};
color: ${colors.darkBlue};
h2 {
font-size: 1.2rem;
}
}
}
}
`;
We first imported styled from styled-components and deviceWidth from the definition file. We then defined PersonsListContainer as a div to hold our styles. Using media queries and the established breakpoints, we made the page mobile-friendly by setting various breakpoints.
Here, we have used only the standard browser breakpoints for small, large and very large screens. We also made the most of the CSS flexbox and grid to properly style and display our content on the page.
To use this style in our PersonListPage.js file, we simply imported it and added it to our page as follows.
import React from "react";
const PersonsListPage = () => {
return (
<PersonsListContainer>
...
</PersonsListContainer>
);
};
export default PersonsListPage;
The wrapper will output a div because we defined it as a div in our styles.
Adding Themes And Wrapping It Up
It’s always a cool feature to add themes to our application. For this, we need the following:
- Our custom themes defined in a separate file (in our case
definition.js file).
- The logic defined in our Redux actions and reducers.
- Calling our theme in our application and passing it through the component tree.
Let’s check this out.
Here is our theme object in the definition.js file.
export const theme = {
light: {
dark: "#0B0C10",
darkBlue: "#253858",
midDarkBlue: "#42526e",
lightBlue: "#0065ff",
normal: "#dcdcdd",
lighter: "#F4F5F7",
white: "#FFFFFF",
darkred: "#E85A4F",
lightred: "#E98074",
goldish: "#FFC400",
bodyText: "#0B0C10",
lightshadowtheme: "rgba(0, 0, 0, 0.1)"
},
dark: {
dark: "white",
darkBlue: "#06090F",
midDarkBlue: "#161B22",
normal: "#dcdcdd",
lighter: "#06090F",
white: "white",
darkred: "#E85A4F",
lightred: "#E98074",
goldish: "#FFC400",
bodyText: "white",
lightshadowtheme: "rgba(255, 255, 255, 0.9)"
}
};
We have added various color properties for the light and dark themes. The colors are carefully chosen to enable visibility both in light and dark mode. You can define your themes as you want. This is not a hard and fast rule.
Next, let's add the functionality to Redux.
We have created globalActions.js in our Redux actions folder and added the following codes.
import { SET_DARK_THEME, SET_LIGHT_THEME } from "../constants/globalConstants";
import { theme } from "../../styles/definition";
export const switchToLightTheme = () => (dispatch) => {
dispatch({
type: SET_LIGHT_THEME,
payload: theme.light
});
localStorage.setItem("theme", JSON.stringify(theme.light));
localStorage.setItem("light", JSON.stringify(true));
};
export const switchToDarkTheme = () => (dispatch) => {
dispatch({
type: SET_DARK_THEME,
payload: theme.dark
});
localStorage.setItem("theme", JSON.stringify(theme.dark));
localStorage.setItem("light", JSON.stringify(false));
};
Here, we simply imported our defined themes. Dispatched the corresponding actions, passing the payload of the themes we needed. The payload results are stored in the local storage using the same keys for both light and dark themes. This enables us to persist the states in the browser.
We also need to define our reducer for the themes.
import { SET_DARK_THEME, SET_LIGHT_THEME } from "../constants/globalConstants";
export const toggleTheme = (state = {}, action) => {
switch (action.type) {
case SET_LIGHT_THEME:
return {
theme: action.payload,
light: true
};
case SET_DARK_THEME:
return {
theme: action.payload,
light: false
};
default:
return state;
}
};
This is very similar to what we’ve been doing. We used the switch statement to check the type of action and then returned the appropriate payload. We also returned a state light that determines whether light or dark theme is selected by the user. We’ll use this in our components.
We also need to add it to our root reducer and store. Here is the complete code for our store.js.
import { createStore, applyMiddleware } from "redux";
import thunk from "redux-thunk";
import { theme as initialTheme } from "../styles/definition";
import reducers from "./reducers/index";
const theme = localStorage.getItem("theme")
? JSON.parse(localStorage.getItem("theme"))
: initialTheme.light;
const light = localStorage.getItem("light")
? JSON.parse(localStorage.getItem("light"))
: true;
const initialState = {
toggleTheme: { light, theme }
};
export default createStore(reducers, initialState, applyMiddleware(thunk));
Since we needed to persist the theme when the user refreshes, we had to get it from the local storage using localStorage.getItem() and pass it to our initial state.
Adding The Functionality To Our React Application
Styled components provide us with ThemeProvider that allows us to pass themes through our application. We can modify our App.js file to add this functionality.
Let's take a look at it.
import React from "react";
import { BrowserRouter as Router, Switch, Route } from "react-router-dom";
import { useSelector } from "react-redux";
import { ThemeProvider } from "styled-components";
function App() {
const { theme } = useSelector((state) => state.toggleTheme);
let Theme = theme ? theme : {};
return (
<ThemeProvider theme={Theme}>
<Router>
...
</Router>
</ThemeProvider>
);
}
export default App;
By passing themes through the ThemeProvider, we can easily use the theme props in our styles.
For instance, we can set the color to our bodyText custom color as follows.
color: ${(props) => props.theme.bodyText};
We can use the custom themes anywhere we need color in our application.
For example, to define border-bottom, we do the following.
border-bottom: 2px solid ${(props) => props.theme.goldish};
Conclusion
We began by delving into Sanity.io, setting it up and connecting it to our React application. Then we set up Redux and used the GROQ language to query our API. We saw how to connect and use Redux to our React app using react-redux, use styled-components and theming.
However, we only scratched the surface on what is possible with these technologies. I encourage you to go through the code samples in my GitHub repo and try your hands on a completely different project using these technologies to learn and master them.
Resources











































































")
