

Yesterday, Happy Prime owner and engineer Jeremy Felt released Shortnotes, a plugin for writing notes from the WordPress editor. The intention is for users to create short pieces of content, such as that found on Twitter, Instagram, and similar social networks. However, it does not come with a front-end posting interface, at least not in version 1.0.
The plugin works just like the post and page editor. It should be straightforward for most users.
While the Shortnotes plugin is relatively bare-bones for now, it serves as a foundation of something that could be more. Part of what makes social networks appealing is the ease of publishing quick content. Publishing notes through the plugin requires visiting the WordPress admin, clicking “Add New,” writing the content, publishing, and clicking a new link to view it on the front end. A quick-publishing interface either through a Dashboard widget or a front-end form would be a useful addition.
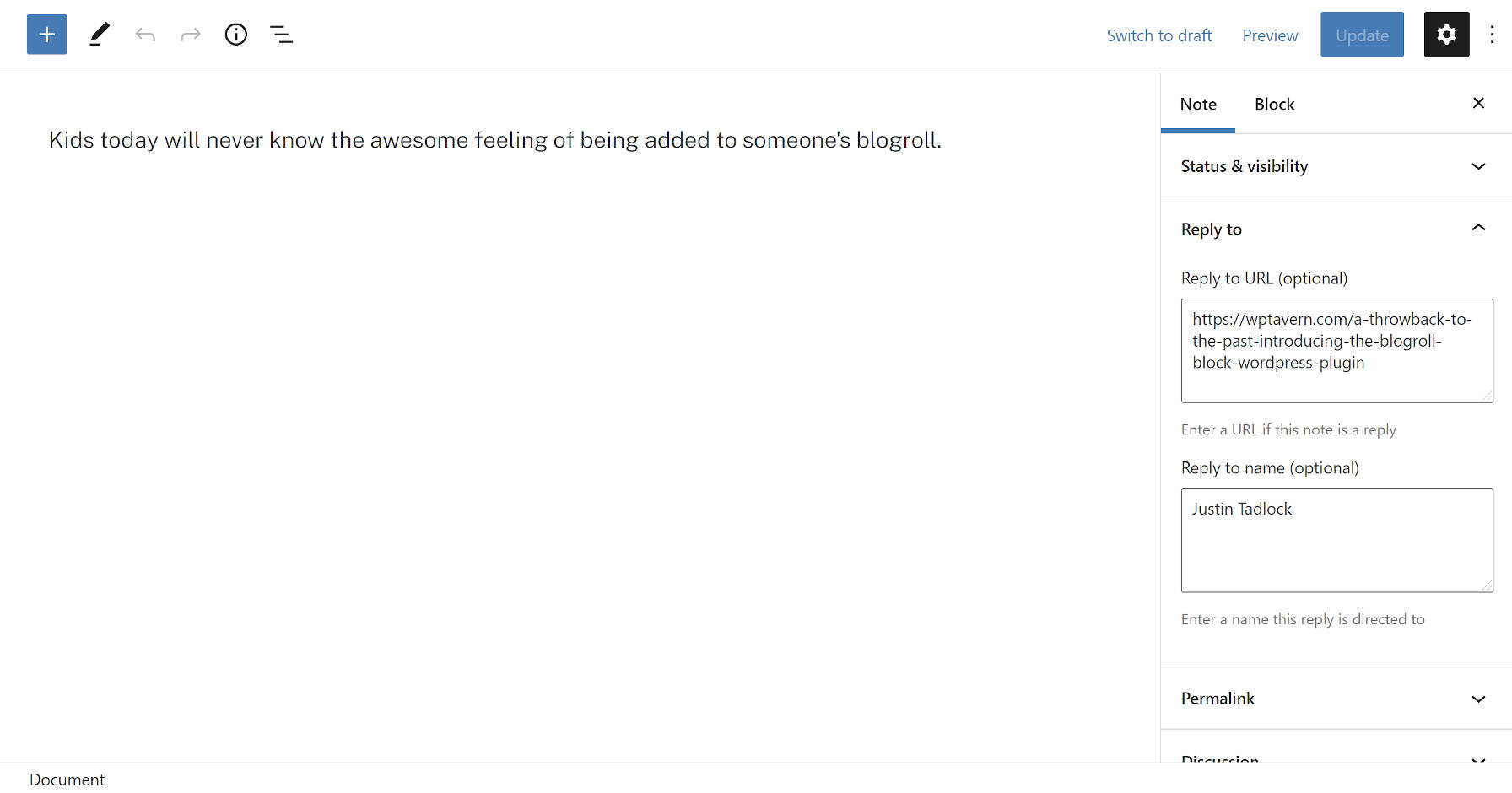
Some new concepts that not all users may be familiar with are the “Reply to URL” and “Reply to name” fields. These are semantic fields for creating a note in reply to another post or person on the web. The plugin will automatically output this reply link on the front end.
The plugin integrates with the Webmention plugin. A Webmention is a standardized protocol for mentions and conversations across the web. The goal is a decentralized social “network” of sorts where everyone owns and controls their content. It is an alternative to what IndieWeb calls the “corporate” web in which large tech companies have control.
When entering a Reply to URL, Shortnotes will automatically send that URL through the Webmentions plugin system. It will also parse URLs in the post content as webmentions if they exist.
Users may also notice that the note title field is missing. This is intentional. The plugin automatically generates titles. They are needed for the <title> tag, which tools like search engines use.
The idea is for titles to not appear as part of the theme layout. Because most themes are not coded to check for post-type support before displaying them, there is a high chance that a user’s theme will output the auto-generated title on the front end. For now, that means editing a bit of theme code for those who do not want them to appear. Felt has an example of how he modified this for his site’s custom Twenty Twenty-One child theme. In the long run, as more themes begin supporting the upcoming site editor, users will be able to make this customization directly in the WordPress admin.
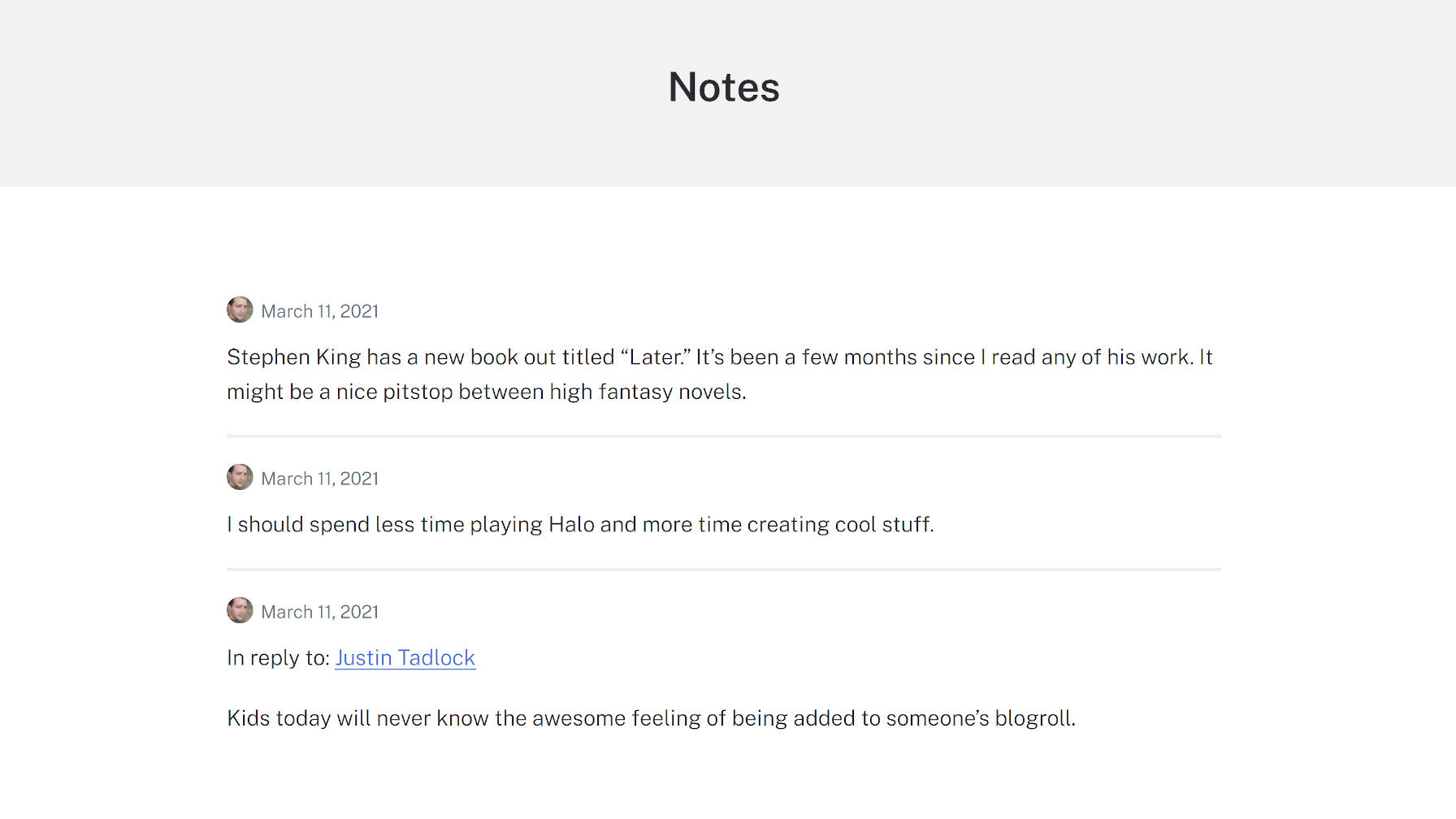
With a few tweaks like removing the title and some minor CSS adjustments, I was able to create a clean Notes archive page using the Genesis Block theme:
One of my interests in checking this project out was diving into a real-world example of a plugin that limited which blocks could be used with the editor. The notes post type only allows the Paragraph, Image, and Gallery blocks. Again, the idea is to replicate the feel of what you can do on social networks. Overall, this feature worked as it should, limiting the notes to a subset of blocks.
However, I ran across a bug with the block editor. All block patterns, regardless of what blocks they contained, appeared in the inserter. Clicking on one containing a disallowed block would not insert it into a post. However, the editor did add a pop-up note that it had. There is a GitHub issue for this bug that has seen little movement since it was opened in June 2020.
Felt created a plugin to solve this called Unregister Broken Patterns. It removes any patterns that contain blocks that a post type does not support. At best, it is a temporary measure and needs to be addressed in WordPress.


