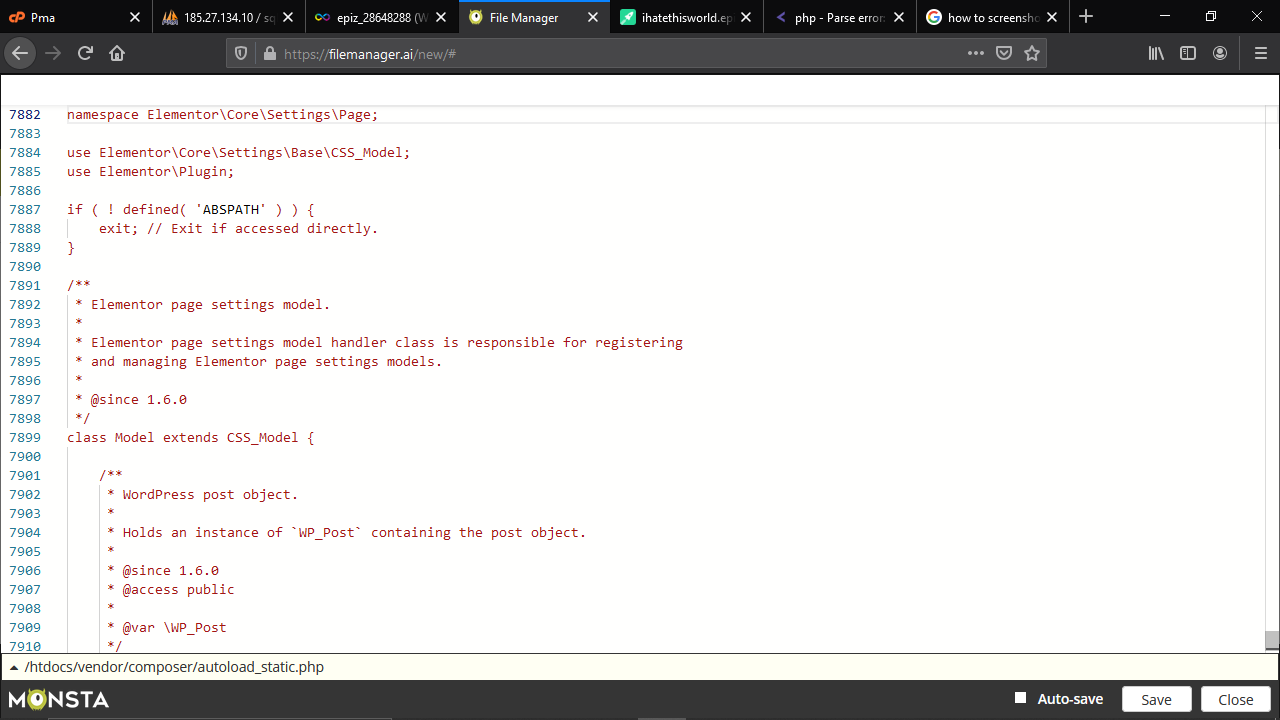
Hi, I'm using a MDB database that i would like to filter based on selections made in 2 comboboxes.
say: cmbBase and cmbMix.
cmbBase connects to "Base"
cmbMix connects to "Mix"
I have use the automated database method in C#
Click Here
private void BaseMixBindingNavigatorSaveItem_Click(object sender, EventArgs e)
{
this.Validate();
this.BaseMixBindingSource.EndEdit();
this.tableAdapterManager.UpdateAll(this.DSBaseMixDataSet);
}
private void frmImport_Load(object sender, EventArgs e)
{
//filter out doubles
cmbBase.DataSource = DSBaseMixDataSet.BaseMix.Select(x => x.Base).Distinct().ToList();
}The problem is that i have no idea how i can filter the other combobox in such a way that it only shows the data in the next row of the selcted combobox.
So if i select "A" in cmbBase, cmbMix should only show the values "A+1; A+3; A+6" if there were only a few values i could use an if function, but this is a database with a lot of numbers. I tried many of the solutions i found, but none of them work as i expected. Anyone that can help me out here?