

Never published this before, so this is a DaniWeb.com Exclusive :)
If your WP-Site has a lot of K-Links, you should consider using this script.
It definetly works. For now...
You can not defend your site against all kinds of attacks, but on one of the most common, you can significantly decrease the negative effects:
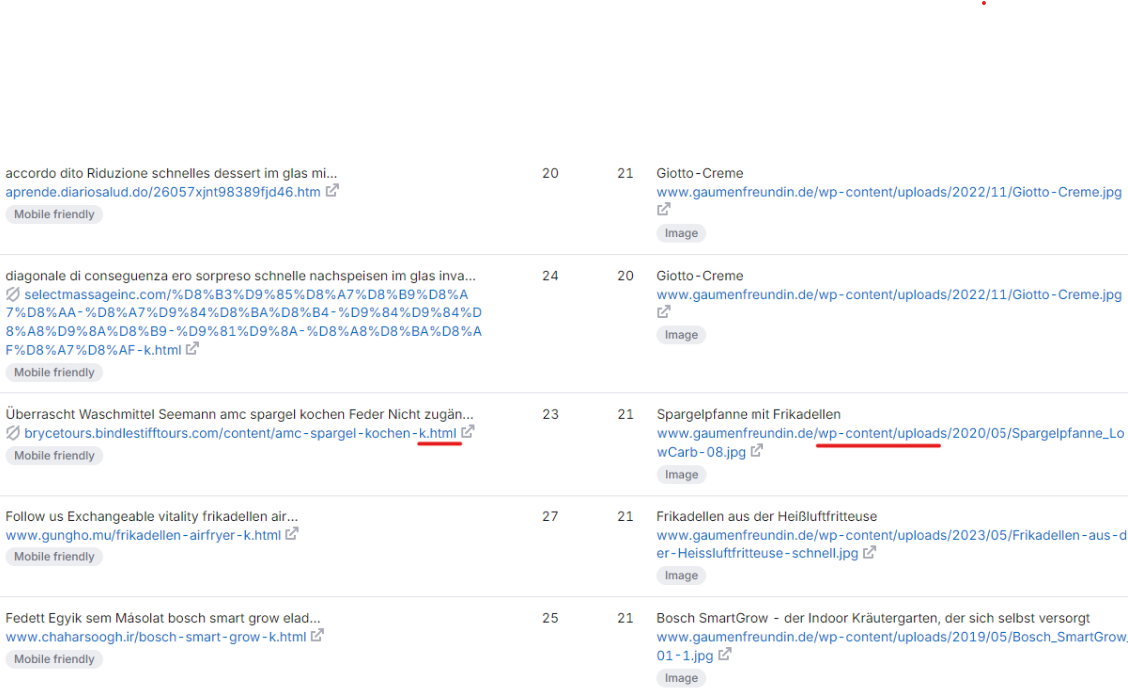
"K-Links" (new version: C-Links), where Image Hotlinking is used to generate Links, targeting mainly Wordpress Instances.
Examples:
k-links.png
this is why they're called "K-Links/C-Links". They always end with "-k.html" oder "-c.html"
The basic Anti-Hotlinking-Script can help in reducing the amount of traffic, when hotlinking is abused to burn your bandwith.
But i have never seen it recover any visibility losses in the SERPs.
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_REFERER} !^$
RewriteCond %{HTTP_REFERER} !^http(s)?://(www\\.)?daniweb.com [NC]
RewriteCond %{HTTP_REFERER} !^http(s)?://(www\\.)?google.com [NC]
RewriteCond %{HTTP_REFERER} !^http(s)?://(www\\.)?bing.com [NC]
RewriteCond %{HTTP_REFERER} !^http(s)?://(www\\.)?yahoo.com [NC]
RewriteCond %{HTTP_REFERER} !^http(s)?://(www\\.)?duckduckgo.com [NC]
RewriteRule \\.(jpg|jpeg|png|gif|avif|webp|svg)$ /nohotlink.html [L]
</IfModule>
---
content nohotlink.html:
<body>
<h1>Hotlinking not allowed</h1>
<p>Too view our images, please visit our <a href="<https://daniweb.com/>">Website</a>.</p>
</body>It integrates the "Whitelist" directly into .htaccess, which is not optimal.
I had a case, where this caused problems, because the Whitelist was huge (1000+ Domains).
So i found this solution with "RewriteMap", which i integradted into this Script to put the whitelist inside a .txt file.
This also was easier for the client, as he might needs to add entries to the whitelist and like this does not have to edit the htaccess everytime.
I have also set the link inside the HTML to rel="nofollow".
I did get some nice results with this!
Even if there are still other DoFollow-Links on the Hotlinking Site, the presence of this one nofollow-link seems to reduce the toxicity of each one.
Important: Dont link the actual Canonical URl from your Main Page from nohotlink.html!
If your Domain is https://daniweb.com for example, you link to http://www.daniweb.com (with "www" and "http").
I experimented a lot with this and set the Canonical of the nohotlink.html to the Main Page, tested with noindex, nofollow robots tag, but it was all a mess.
If anybody is as deep into this stuff as i am, i will be happy to discuss.
Feel free to share your thoughts!
Disclaimer: Please use at your own risk, only if you know, what you are doing. Don't make me responsible, if you make mistakes. They are yours, not mine.


{kind=link}