As I sit down to write this article, I can’t help but marvel at the incredible changes sweeping through our industry. For the first time in my career, I feel like we’re no longer limited by our technology but by our imagination. Well, almost. Artificial Intelligence (AI) is reshaping the web design landscape in ways we could only dream of a few years ago, and I’m excited to share with you how it’s supercharging our productivity across various aspects of our work.
AI Is A Partner, Not A Competitor
Now, before we dive in, let me assure you: AI isn’t here to replace us. At least, not for a while yet. There are still crucial areas where human expertise reigns supreme. AI struggles with strategic planning that considers the nuances of human behavior and market trends. It can’t match our emotional intelligence when navigating client relationships and team dynamics. And when it comes to creative thinking that pushes boundaries and creates truly innovative solutions, we humans still have the upper hand.
But here’s the exciting part: AI is becoming an invaluable tool that’s supercharging our productivity. Think of it as having a highly capable intern at your disposal. As the Nielsen Norman Group aptly put it in their article “AI as an Intern,” we need to approach AI tools with the right mindset. Double-check their work, use them for initial drafts rather than final products, and provide specific instructions and relevant context.
The key to harnessing AI’s power lies in working with it collaboratively.
Don’t expect perfect results on the first try. Instead, engage in a back-and-forth conversation, refining the AI output through iteration. This process of continuous improvement is where AI truly shines, dramatically speeding up our workflow.
Let’s explore how AI is reshaping different areas of our industry, looking at some of the many tools available to us.
AI In Design: Unleashing Creativity And Efficiency
In the realm of design, AI is proving to be a game-changer. It’s particularly adept at:
Collaborating on layout;
Generating the perfect image;
Refining and adapting existing imagery.
Take AI in Figma, for instance. It’s become my go-to for generating dummy content and tidying up my layers. The time saved on these mundane tasks allows me to focus more on the creative aspects of design.
Generative imagery tools like Krea, which uses Flux, have revolutionized how we source visuals. Gone are the days of endlessly scrolling through stock libraries. Now, we can describe exactly what we need, and AI will create it for us. This level of customization and specificity is a game changer for creating unique, on-brand visuals.
Relume is another tool I’ve found incredibly useful. It’s great for a collaborative back-and-forth over designs or for quickly putting together designs for smaller sites. The ability to iterate rapidly with AI assistance has significantly sped up my design process.
And let’s not forget about Adobe. Their upcoming tools, such as lighting matching for composite images, are set to take our design capabilities to new heights. If you want to see more of what’s on the horizon, I highly recommend checking out the latest Adobe Max presentations.
AI In Coding: Boosting Developer Productivity
The impact of AI on coding is nothing short of revolutionary. According to a McKinsey study, developers using AI tools performed coding tasks like code generation, refactoring, and documentation 20%-50% faster on average compared to those not using AI tools. That’s a significant productivity boost!
Tools like Cursor AI and GitHub Copilot are at the forefront of this revolution, offering features such as:
AI pair programming with predictive code edits;
Natural language code editing;
Chat interfaces for asking questions and getting help.
I’ve personally been amazed by what ChatGPT 01-Preview can do. I’ve used it to build simple WordPress plugins in minutes, tasks that would have taken me significantly longer in the past.
AI In UX: Enhancing User Research And Analysis
In the field of User Experience (UX), AI is opening up new possibilities for research and analysis. It’s allowing us to:
Conduct user research at scale;
Analyze open-ended qualitative feedback;
Query analytic data using natural language;
Predict user behavior.
I’ve found ChatGPT to be an invaluable tool for data analysis, particularly when it comes to making sense of analytics and survey responses. It can quickly identify patterns and insights that might take us hours to uncover manually.
Tools like Strella are pushing the boundaries of what’s possible in user research. AI can now perform user interviews at scale, allowing us to gather insights from a much larger pool of users than ever before.
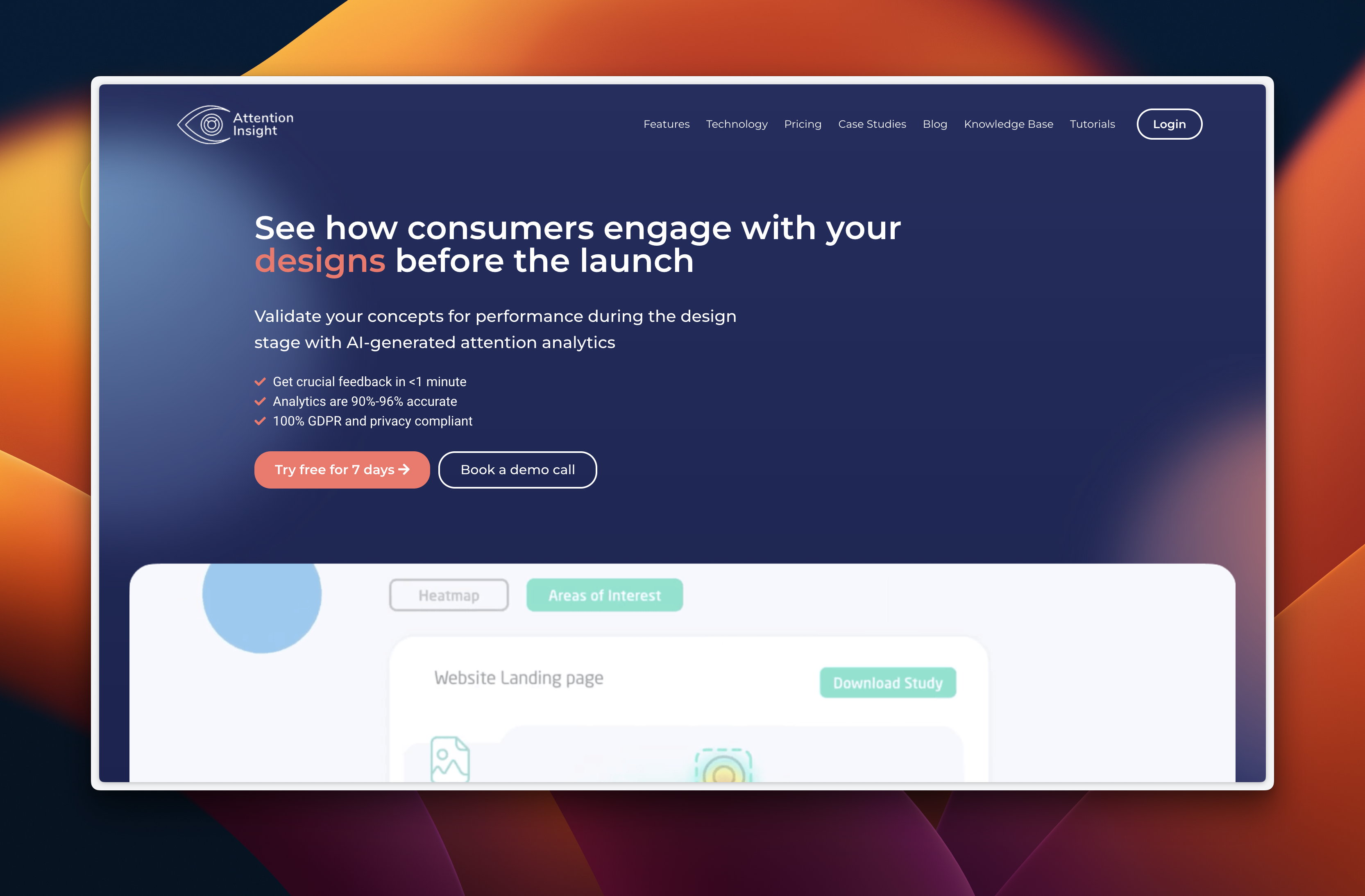
Attention Insight is another fascinating tool. It uses AI to predict where people will look on a page, providing valuable data for optimizing layouts and user interfaces.
Microsoft Clarity has also upped its game, allowing us to ask questions about our analytic insights, heatmaps, and session recordings. This natural language interface makes it easier than ever to extract meaningful insights from our data.
AI In Copywriting: Elevating Content Quality And Efficiency
When it comes to copywriting, AI is proving to be a powerful ally. It’s helping us:
Transform poor-quality stakeholder content into web-optimized copy;
Brainstorm value propositions and create high-converting copy;
Craft compelling business cases and strategy documentation;
Write standard operating procedures.
Notion AI has become one of my go-to tools for content creation. It combines the best of ChatGPT and Claude, allowing it to draw upon a wide range of provided source material to write detailed documentation, articles, and reports.
ChatGPT has been a game-changer for improving the quality of website copy. It can take user questions and bullet-point answers from subject specialists and transform them into web-optimized content. I’ve found it particularly useful for defining value propositions and writing high-converting copy.
For refining existing content, the Hemingway Editor is invaluable. It can take the existing copy and make it clearer, more concise, and easier to scan — essential qualities for effective web content.
AI In Administration: Streamlining Mundane Tasks
AI isn’t just transforming the technical aspects of our work; it’s also making a significant impact on those mundane administrative tasks that often eat up our time. By leveraging AI, we can streamline various aspects of our daily workflow, allowing us to focus more on high-value activities.
Here are some ways AI is helping us tackle administrative tasks more efficiently:
Getting our thoughts down faster;
Writing better emails;
Summarizing long emails or Slack threads;
Speeding up research;
Backing up arguments with relevant data.
Let me share some personal experiences with AI tools that have transformed my administrative workflow:
I’ve dramatically increased my writing speed using Flow. This tool has taken me from typing at 49 words per minute to dictating at over 95 words per minute. Not only does it allow me to dictate, but it also tidies up my words to ensure they read well and are grammatically correct.
For email writing, I’ve found Fixkey to be invaluable. It helps me rewrite or reformat copy quickly. I’ve even set up a prompt that tones down my emails when I’m feeling particularly irritable, ensuring they sound reasonable and professional.
Dealing with long email threads or Slack conversations can be time-consuming. That’s where Spark comes in handy. It summarizes lengthy threads, saving me valuable time. Interestingly, this feature is now built into iOS for all notifications, making it even more accessible.
When it comes to research, Google Notebook LLM has been a game-changer. I can feed it large amounts of data on a subject and quickly extract valuable insights. This tool has significantly sped up my research process.
Lastly, if I need to back up an argument with a statistic or quote, Perplexity has become my go-to resource. It quickly finds relevant sources I can quote, adding credibility to my work without the need for extensive manual searches.
Conclusion: Embracing AI For A More Productive Future
As I wrap up this article, I realize I’ve only scratched the surface of what AI can do for our industry. The real challenge isn’t in the technology itself but in breaking out of our established routines and taking the time to experiment with what’s possible.
I believe we need to cultivate a new habit: pausing before each new task to consider how AI could help us approach it differently. The winners in this new reality will be those who can best integrate this technology into their workflow.
AI isn’t replacing us — it’s empowering us to work smarter and more efficiently. By embracing these tools and learning to collaborate effectively with AI, we can focus more on the aspects of our work that truly require human creativity, empathy, and strategic thinking.
If you’re feeling overwhelmed by the rapid pace of change, don’t worry. We’re all learning and adapting together. Remember, the goal isn’t to become an AI expert overnight but to gradually incorporate these tools into your work in ways that make sense for you and your projects.
Gain $200 in a week
from Articles on Smashing Magazine — For Web Designers And Developers https://ift.tt/XhMYusB
Penpot is a free, open-source design tool that allows true collaboration between designers and developers. Designers can create interactive prototypes and design systems at scale, while developers enjoy ready-to-use code and make their workflow easy and fast because it's built with web technologies, works in the browser, and has already passed 33K starts on GitHub.
The UI feels intuitive and makes it easy to get things done, even for someone who’s not a designer (guilty as charged!). You can get things done in the same way and with the same quality as with other more popular and closed-source tools like Figma.
Why Open-Source Is Important
As someone who works with commercial open-source on my day-to-day, I strongly believe in it as a way to be closer to your users and unlock the next level of delivery. Being open-source creates a whole new level of accountability and flexibility for a tool.
Developers are a different breed of user. When we hit a quirk or a gap in the UX, our first instinct is to play detective and figure out why that pattern stuck out as a sore thumb to what we’ve been doing. When the code is open-source, it’s not unusual for us to jump into the source and create an issue with a proposal on how to solve it already. At least, that’s the dream.
On top of that, being open-source allows you and your team to self-host, giving you that extra layer of privacy and control, or at least a more cost-effective solution if you have the time and skills to DYI it all.
When the cards are played right, and the team is able to afford the long-term benefits, commercial open-source is a win-win strategy.
Introducing: Penpot Plugin System
Talking about the extensibility of open-source, Penpot has the PenpotHub the home for open-source templates and the newly released plugin gallery. So now, if there’s a functionality missing, you don’t need to jump into the code-base straightaway — you can create a plugin to achieve what you need. And you can even serve it from localhost!
Creating Penpot Plugins
When it comes to the plugins, creating one is extremely ergonomic. First, there are already set templates for a few frameworks, and I created one for SolidJS in this PR — the power of open-source!
When using Vite, plugins are Single-Page Applications; if you have ever built a Hello World app with Vite, you have what it takes to create a plugin. On top of that, the Penpot team has a few packages that can give you a headstart in the process:
npm install @penpot/plugin-styles
That will allow you to import with a CSS loader or a CSS import from @penpot/plugin-styles/styles.css. The JavaScript API is available through the window object, but if your plugin is in TypeScript, you need to teach it:
npm add -D @penpot/plugin-types
With those types in your node_modules, you can pop-up the tsconfig.json and add the types to the compilerOptions.
And there you are, now, the Language Service Provider in your editor and the TypeScript Compiler will accept that penpot is a valid namespace, and you’ll have auto-completion for the Penpot APIs throughout your entire project. For example, defining your plugin will look like the following:
The last step is to define a plugin manifest in a manifest.json file and make sure it’s in the outpot directory from Vite. The manifest will indicate where each asset is and what permissions your plugin requires to work:
{
"name": "Your Plugin Name",
"description": "A Super plugin that will win Penpot Plugin Contest",
"code": "/plugin.js",
"icon": "/icon.png",
"permissions": [
"content:read",
"content:write",
"library:read",
"library:write",
"user:read",
"comment:read",
"comment:write",
"allow:downloads"
]
}
Once the initial setup is done, the communication between the Penpot API and the plugin interface is done with a bidirectional messaging system, not so different than what you’d do with a Web-Worker.
So, to send a message from your plugin to the Penpot API, you can do the following:
penpot.ui.sendMessage("Hello from my Plugin");
And to receive it back, you need to add an event listener to the window object (the top-level scope) of your plugin:
window.addEventListener("message", event => {
console.log("Received from Pendpot::: ", event.data);
})
A quick performance tip: If you’re creating a more complex plugin with different views and perhaps even routes, you need to have a cleanup logic. Most frameworks provide decent ergonomics to do that; for example, React does it via their return statements.
import { makeEventListener } from "@solid-primitives/event-listener";
function Component() {
const clear = makeEventListener(window, "message", handleMessage);
// ...
return (<span>Hello!</span>)
}
In the official documentation, there’s a step-by-step guide that will walk you through the process of creating, testing, and publishing your plugin. It will even help you out.
So, what are you waiting for?
Plugin Contest: Imagine, Build, Win
Well, maybe you’re waiting for a push of motivation. The Penpot team thought of that, which is why they’re starting a Plugin Contest!
For this contest, they want a fully functional plugin; it must be open-source and include comprehensive documentation. Detailing its features, installation, and usage. The first prize is US$ 1000, and the criteria are innovation, functionality, usability, performance, and code quality. The contest will run from November 15th to December 15th.
Final Thoughts
If you decide to build a plugin, I’d love to know what you’re building and what stack you chose. Please let me know in the comments below or on BlueSky!
Gain $200 in a week
from Articles on Smashing Magazine — For Web Designers And Developers https://ift.tt/NkKj2ux
Earlier this month, we wrapped up our SmashingConfs 2024, and one subject that kept coming up over and over again — among attendees, between speakers, and even within the staff — was “what would we like to get better at next year?”
It seems like everyone has a different answer, but one thing is for sure: Smashing can help you with that. 😉
Save 30% on Books and Workshops (3+ items)
Good news for people who love a good value for a friendly price: throughout the entire month of November, you can save 30% off three or morebooks and eBooks, 30% off three or more workshops, or get the entire Smashing eBook library for $75. This is a perfect time to set yourself up for a year of learning in 2025.
Build Your Own Bundle!
Our hardcover books are our editorial flagships. They deliver in-depth knowledge and expertise shared by experts from the industry. No fluff or theory, only practical tips and insights you can apply to your work right away.
No matter if you want to complete your existing Smashing book collection or start one from scratch, you can now pick and mix your favorite books and eBooks from our Smashing Books line-up to create a bundle tailored to your needs. Or take a look at our bundle recommendations below for some inspiration.
Throughout the month of November, the 30% book discount will automatically apply to your cart once you add three or more items. Please note that the discount can’t be combined with other discounts.
Once you’ve decided which books should go into your bundle, we’ll pack everything up safely and send the parcel right to your doorstep from our warehouse in Germany. Shipping is free worldwide. Check delivery times.
Book Bundle Recommendations
We know decisions can be hard, that’s why we collected some ideas for themed book bundles to make the choice at least a bit easier. These bundles are perfect if you want to enhance your skills in one particular field.
You can click on each book title to jump to the details and add the book to your cart. The discount will be applied during checkout.
Front-End Bundle
Save 30% on the complete bundle.
Regular price (hardcover + PDF, ePUB, Kindle versions): $146.25
Bundle price: $102.38
Front-End Bundle dives deep into the challenges front-end developers face in their work every day — whether it’s performance, TypeScript and Image Optimization. You’ll learn practical strategies to make your workflow more efficient, but also gain precious insights into how teams at Instagram, Shopify, Netflix, eBay, Figma, Spotify tackle common challenges and frustrations.
Save 30% on the complete bundle.
Regular price (hardcover + PDF, ePUB, Kindle versions): $146.25
Bundle price: $102.38
Design Best Practices Bundle is all about creating respectful, engaging experiences that put your users’ well-being and privacy first. The practical and tactical tips help you encourage users to act — without employing dark patterns and manipulative techniques — and grow a sustainable digital business that becomes more profitable as a result.
Save 30% on the complete bundle.
Regular price (hardcover + PDF, ePUB, Kindle versions): $144.00
Bundle price: $100.80
A lot of websites these days look rather generic. Our Interface Design Bundle will make you think outside the box, exploring how you can create compelling, effective user experiences, with clear intent and purpose — for both desktop and mobile.
Save 30% on the complete bundle.
Regular price (hardcover + PDF, ePUB, Kindle versions): $292.50
Bundle price: $204.75
The Big Design Bundle shines a light on the fine little details that go into building cohesive, human-centered experiences. Covering everything from design systems to form design patterns, mobile design to UX, and data privacy to ethical design, it provides you with a solid foundation for designing products that stand out from the crowd.
Get all eBooks for $75. You’re more of an eBook kind of person? The bundle-up discounts do apply to eBooks, too, of course. Or take a look at our Smashing Library to save even more: It includes 68 eBooks (including all our latest releases) for $75 (PDF, ePUB, and Kindle formats). Perfect to keep all your favorite books close when you’re on the go.
Bundle Up On Online Workshops: 30% Off On 3+ Workshops
To prepare for the challenges that 2025 might have in store for you, you can now bundle up 3 or more online workshops and save 30% on the total price with code BUNDLEUP. Please note that the discount can’t be combined with other discounts. Take a look at all our upcoming workshops and start your smashing learning journey this winter.
Custom Bundles To Fit Your Needs!
Do you need a custom bundle? At Smashing, we would love to know how we can help you and your team make the best of 2025. Let’s think big!
We’d be happy to craft custom bundles that work for you:
Group discounts on large teams for Smashing Membership,
Bulk discounts on books or other learning materials for education or non-profit groups,
Door prize packages for meetups and events,
...any other possibilities for your team, your office, your career path. Let us know via contact form!
We are always looking for new ways to support our community. Please contact us if you’d like us to craft a custom bundle for your needs, or if you have any questions at all. Let’s have a great year!
Community Matters ❤️
Producing a book or a workshop takes quite a bit of time, and we couldn’t pull it off without the support of our wonderful community. A huge shout-out to Smashing Members for their kind, ongoing support. 👏 Happy learning, everyone!
Gain $200 in a week
from Articles on Smashing Magazine — For Web Designers And Developers https://ift.tt/fqVSvcm
Another title from A Book Apart has been re-released for free. The latest? Tim Brown’s Flexible Typesetting. I may not be the utmost expert on typography and its best practices but I do remember reading this book (it’s still on the shelf next to me!) thinking maybe, just maybe, I might be able to hold a conversation about it with Robin when I finished it.
I still think I’m in “maybe” territory but that’s not Tim’s fault — I found the book super helpful and approachable for noobs like me who want to up our game. For the sake of it, I’ll drop the chapter titles here to give you an idea of what you’ll get.
What is typsetting?
Preparing text and code (planning is definitely part of the typesetting process)
Selecting typefaces (this one helped me a lot!)
Shaping text blocks (modern CSS can help here)
Crafting compositions (great if you’re designing for long-form content)
The State of CSS 2024 survey wrapped up and the results are interesting, as always. Even though each section is worth analyzing, we are usually most hyped about the section on the most used CSS features. And if you are interested in writing about web development (maybe start writing with us 😉), you will specifically want to check out the feature’s Reading List section. It holds the features that survey respondents wish to read about after completing the survey and is usually composed of up-and-coming features with low community awareness.
One of the features I was excited to see was my 2024 top pick: CSS Anchor Positioning, ranking in the survey’s Top 4. Just below, you can find Scroll-Driven Animations, another amazing feature that gained broad browser support this year. Both are elegant and offer good DX, but combining them opens up new possibilities that clearly fall into what most of us would have considered JavaScript territory just last year.
I want to show one of those possibilities while learning more about both features. Specifically, we will make the following blog post in which footnotes pop up as comments on the sides of each text.
For this demo, our requirements will be:
Pop the footnotes up when they get into the screen.
Attach them to their corresponding texts.
The footnotes are on the sides of the screen, so we need a mobile fallback.
The Foundation
To start, we will use the following everyday example of a blog post layout: title, cover image, and body of text:
The only thing to notice about the markup is that now and then we have a paragraph with a footnote at the end:
<main class="post">
<!-- etc. -->
<p class="note">
Super intereseting information!
<span class="footnote"> A footnote about it </span>
</p>
</main>
Positioning the Footnotes
In that demo, the footnotes are located inside the body of the post just after the text we want to note. However, we want them to be attached as floating bubbles on the side of the text. In the past, we would probably need a mix of absolute and relative positioning along with finding the correct inset properties for each footnote.
However, we can now use anchor positioning for the job, a feature that allows us to position absolute elements relative to other elements — rather than just relative to the containment context it is in. We will be talking about “anchors” and “targets” for a while, so a little terminology as we get going:
Anchor: This is the element used as a reference for positioning other elements, hence the anchor name.
Target: This is an absolutely-positioned element placed relative to one or more anchors. The target is the name we will use from now on, but you will often find it as just an “absolutely positioned element” in other resources.
I won’t get into each detail, but if you want to learn more about it I highly recommend our Anchor Positioning Guide for complete information and examples.
The Anchor and Target
It’s easy to know that each .footnote is a target element. Picking our anchor, however, requires more nuance. While it may look like each .note element should be an anchor element, it’s better to choose the whole .post as the anchor. Let me explain if we set the .footnote position to absolute:
.footnote {
position: absolute;
}
You will notice that the .footnote elements on the post are removed from the normal document flow and they hover visually above their .note elements. This is great news! Since they are already aligned on the vertical axis, we just have to move them on the horizontal axis onto the sides using the post as an anchor.
This is when we would need to find the correct inset property to place them on the sides. While this is doable, it’s a painful choice since:
You would have to rely on a magic number.
It depends on the viewport.
It depends on the footnote’s content since it changes its width.
Elements aren’t anchors by default, so to register the post as an anchor, we have to use the anchor-name property and give it a dashed-ident (a custom name starting with two dashes) as a name.
.post {
anchor-name: --post;
}
In this case, our target element would be the .footnote. To use a target element, we can keep the absolute positioning and select an anchor element using the position-anchor property, which takes the anchor’s dashed ident. This will make .post the default anchor for the target in the following step.
Instead of choosing an arbitrary inset value for the .footnote‘s left or right properties, we can use the anchor() function. It returns a <length> value with the position of one side of the anchor, allowing us to always set the target’s inset properties correctly. So, we can connect the left side of the target to the right side of the anchor and vice versa:
.footnote {
position: absolute;
position-anchor: --post;
/* To place them on the right */
left: anchor(right);
/* or to place them on the left*/
right: anchor(left);
/* Just one of them at a time! */
}
However, you will notice that it’s stuck to the side of the post with no space in between. Luckily, the margin property works just as you are hoping it does with target elements and gives a little space between the footnote target and the post anchor. We can also add a little more styles to make things prettier:
Lastly, all our .footnote elements are on the same side of the post, if we want to arrange them one on each side, we can use the nth-of-type() selector to select the even and odd notes and set them on opposite sides.
We use nth-of-type() instead of nth-child since we just want to iterate over .note elements and not all the siblings.
Just remember to remove the last inset declaration from .footnote, and tada! We have our footnotes on each side. You will notice I also added a little triangle on each footnote, but that’s beyond the scope of this post:
The View-Driven Animation
Let’s get into making the pop-up animation. I find the easiest part since both view and scroll-driven animation are built to be as intuitive as possible. We will start by registering an animation using an everyday @keyframes. What we want is for our footnotes to start being invisible and slowly become bigger and visible:
@keyframes pop-up {
from {
opacity: 0;
transform: scale(0.5);
}
to {
opacity: 1;
}
}
That’s our animation, now we just have to add it to each .footnote:
.footnote {
/* ... */
animation: pop-up linear;
}
This by itself won’t do anything. We usually would have set an animation-duration for it to start. However, view-driven animations don’t run through a set time, rather the animation progression will depend on where the element is on the screen. To do so, we set the animation-timeline to view().
This makes the animation finish just as the element is leaving the screen. What we want is for it to finish somewhere more readable. The last touch is setting the animation-range to cover 0% cover 40%. This translates to, “I want the element to start its animation when it’s 0% in the view and end when it’s at 40% in the view.”
You may have noticed that this approach to footnotes doesn’t work on smaller screens since there is no space at the sides of the post. The fix is easy. What we want is for the footnotes to display as normal notes on small screens and as comments on larger screens, we can do that by making our comments only available when the screen is bigger than a certain threshold, which is about 1200px. If it isn’t, then the notes are displayed on the body of the post as any other note you may find on the web.
Now our comments should be displayed on the sides only when there is enough space for them:
Wrapping Up
If you also like writing about something you are passionate about, you will often find yourself going into random tangents or wanting to add a comment in each paragraph for extra context. At least, that’s my case, so having a way to dynamically show comments is a great addition. Especially when we achieved using only CSS — in a way that we couldn’t just a year ago!
We’ve all had that moment. You’re optimizing the performance of some website, scrutinizing every millisecond it takes for the current page to load. You’ve fired up Google Lighthouse from Chrome’s DevTools because everyone and their uncle uses it to evaluate performance.
After running your 151st report and completing all of the recommended improvements, you experience nirvana: a perfect 100% performance score!
Time to pat yourself on the back for a job well done. Maybe you can use this to get that pay raise you’ve been wanting! Except, don’t — at least not using Google Lighthouse as your sole proof. I know a perfect score produces all kinds of good feelings. That’s what we’re aiming for, after all!
Google Lighthouse is merely one tool in a complete performance toolkit. What it’s not is a complete picture of how your website performs in the real world. Sure, we can glean plenty of insights about a site’s performance and even spot issues that ought to be addressed to speed things up. But again, it’s an incomplete picture.
What Google Lighthouse Is Great At
I hear other developers boasting about perfect Lighthouse scores and see the screenshots published all over socials. Hey, I just did that myself in the introduction of this article!
Lighthouse might be the most widely used web performance reporting tool. I’d wager its ubiquity is due to convenience more than the quality of its reports.
Open DevTools, click the Lighthouse tab, and generate the report! There are even many ways we can configure Lighthouse to measure performance in simulated situations, such as slow internet connection speeds or creating separate reports for mobile and desktop. It’s a very powerful tool for something that comes baked into a free browser. It’s also baked right into Google’s PageSpeed Insights tool!
And it’s fast. Run a report in Lighthouse, and you’ll get something back in about 10-15 seconds. Try running reports with other tools, and you’ll find yourself refilling your coffee, hitting the bathroom, and maybe checking your email (in varying order) while waiting for the results. There’s a good reason for that, but all I want to call out is that Google Lighthouse is lightning fast as far as performance reporting goes.
To recap: Lighthouse is great at many things!
It’s convenient to access,
It provides a good deal of configuration for different levels of troubleshooting,
And it spits out reports in record time.
And what about that bright and lovely animated green score — who doesn’t love that?!
OK, that’s the rosy side of Lighthouse reports. It’s only fair to highlight its limitations as well. This isn’t to dissuade you or anyone else from using Lighthouse, but more of a heads-up that your score may not perfectly reflect reality — or even match the scores you’d get in other tools, including Google’s own PageSpeed Insights.
It Doesn’t Match “Real” Users
Not all data is created equal in capital Web Performance. It’s important to know this because data represents assumptions that reporting tools make when evaluating performance metrics.
The data Lighthouse relies on for its reporting is called simulated data. You might already have a solid guess at what that means: it’s synthetic data. Now, before kicking simulated data in the knees for not being “real” data, know that it’s the reason Lighthouse is super fast.
You know how there’s a setting to “throttle” the internet connection speed? That simulates different conditions that either slow down or speed up the connection speed, something that you configure directly in Lighthouse. By default, Lighthouse collects data on a fast connection, but we can configure it to something slower to gain insights on slow page loads. But beware! Lighthouse then estimates how quickly the page would have loaded on a different connection.
“[Simulated throttling] reduces variability between tests. But if there’s a single slow render-blocking request that shares an origin with several fast responses, then Lighthouse will underestimate page load time.
Lighthouse averages optimistic and pessimistic estimates when it’s unsure exactly which nodes block rendering. In practice, metrics may be closer to either one of these, depending on which dependency graph is more correct.”
And again, the environment is a configuration, not reality. It’s unlikely that your throttled conditions match the connection speeds of an average real user on the website, as they may have a faster network connection or run on a slower CPU. What Lighthouse provides is more like “on-demand” testing that’s immediately available.
That makes simulated data great for running tests quickly and under certain artificially sweetened conditions. However, it sacrifices accuracy by making assumptions about the connection speeds of site visitors and averages things in a way that divorces it from reality.
While simulated throttling is the default in Lighthouse, it also supports more realistic throttling methods. Running those tests will take more time but give you more accurate data. The easiest way to run Lighthouse with more realistic settings is using an online tool like the DebugBear website speed test or WebPageTest.
It Doesn’t Impact Core Web Vitals Scores
These Core Web Vitals everyone talks about are Google’s standard metrics for measuring performance. They go beyond simple “Your page loaded in X seconds” reports by looking at a slew of more pertinent details that are diagnostic of how the page loads, resources that might be blocking other resources, slow user interactions, and how much the page shifts around from loading resources and content. Zeunert has another great post here on Smashing Magazine that discusses each metric in detail.
The main point here is that the simulated data Lighthouse produces may (and often does) differ from performance metrics from other tools. I spent a good deal explaining this in another article. The gist of it is that Lighthouse scores do not impact Core Web Vitals data. The reason for that is Core Web Vitals relies on data about real users pulled from the monthly-updated Chrome User Experience (CrUX) report. While CrUX data may be limited by how recently the data was pulled, it is a more accurate reflection of user behaviors and browsing conditions than the simulated data in Lighthouse.
The ultimate point I’m getting at is that Lighthouse is simply ineffective at measuring Core Web Vitals performance metrics. Here’s how I explain it in my bespoke article:
“[Synthetic] data is fundamentally limited by the fact that it only looks at a single experience in a pre-defined environment. This environment often doesn’t even match the average real user on the website, who may have a faster network connection or a slower CPU.”
I emphasized the important part. In real life, users are likely to have more than one experience on a particular page. It’s not as though you navigate to a site, let it load, sit there, and then close the page; you’re more likely to do something on that page. And for a Core Web Vital metric that looks for slow paint in response to user input — namely, Interaction to Next Paint (INP) — there’s no way for Lighthouse to measure that at all!
It’s the same deal for a metric like Cumulative Layout Shift (CLS) that measures the“visible stability” of a page layout because layout shifts often happen lower on the page after a user has scrolled down. If Lighthouse relied on CrUX data (which it doesn’t), then it would be able to make assumptions based on real users who interact with the page and can experience CLS. Instead, Lighthouse waits patiently for the full page load and never interacts with parts of the page, thus having no way of knowing anything about CLS.
But It’s Still a “Good Start”
That’s what I want you to walk away with at the end of the day. A Lighthouse report is incredibly good at producing reports quickly, thanks to the simulated data it uses. In that sense, I’d say that Lighthouse is a handy “gut check” and maybe even a first step to identifying opportunities to optimize performance.
But a complete picture, it’s not. For that, what we’d want is a tool that leans on real user data. Tools that integrate CrUX data are pretty good there. But again, that data is pulled every month (28 days to be exact) so it may not reflect the most recent user behaviors and interactions, although it is updated daily on a rolling basis and it is indeed possible to query historical records for larger sample sizes.
Even better is using a tool that monitors users in real-time.
Data pulled directly from the site of origin is truly the gold standard data we want because it comes from the source of truth. That makes tools that integrate with your site the best way to gain insights and diagnose issues because they tell you exactly how your visitors are experiencing your site.
I’ve written about using the Performance API in JavaScript to evaluate custom and Core Web Vitals metrics, so it’s possible to roll that on your own. But there are plenty of existing services out there that do this for you, complete with visualizations, historical records, and true real-time user monitoring (often abbreviated as RUM). What services? Well, DebugBear is a great place to start. I cited Matt Zeunert earlier, and DebugBear is his product.
So, if what you want is a complete picture of your site’s performance, go ahead and start with Lighthouse. But don’t stop there because you’re only seeing part of the picture. You’ll want to augment your findings and diagnose performance with real-user monitoring for the most complete, accurate picture.
Gain $200 in a week
from Articles on Smashing Magazine — For Web Designers And Developers https://ift.tt/A2ChNPD
We had fun in my previous article exploring the goodness of scrolly animations supported in today’s versions of Chrome and Edge (and behind a feature flag in Firefox for now). Those are by and large referred to as “scroll-driven” animations. However, “scroll triggering” is something the Chrome team is still working on. It refers to the behavior you might have seen in the wild in which a point of no return activates a complete animation like a trap after our hapless scrolling user ventures past a certain point. You can see JavaScript examples of this on the Wow.js homepage which assembles itself in a sequence of animated entrances as you scroll down. There is no current official CSS solution for scroll-triggered animations — but Ryan Mulligan has shown how we can make it work by cleverly combining the animation-timeline property with custom properties and style queries.
That is a very cool way to combine new CSS features. But I am not done being overly demanding toward the awesome emergent animation timeline technology I didn’t know existed before I read up on it last month. I noticed scroll timelines and view timelines are geared toward animations that play backward when you scroll back up, unlike the Wow.js example where the dogs roll in and then stay. Bramus mentions the same point in his exploration of scroll-triggered animations. The animations run in reverse when scrolling back up. This is not always feasible. As a divorced Dad, I can attest that the Tinder UI is another example of a pattern in which scrolling and swiping can have irreversible consequences.
Scroll till the cows come home with Web-Slinger.css
Believe it or not, with a small amount of SCSS and no JavaScript, we can build a pure CSS replacement of the Wow.js library, which I hereby christen “Web-Slinger.css.” It feels good to use the scroll-driven optimized standards already supported by some major browsers to make a prototype library. Here’s the finished demo and then we will break down how it works. I have always enjoyed the deliberately lo-fi aesthetic of the original Wow.js page, so it’s nice to have an excuse to create a parody. Much profession, so impress.
Teach scrolling elements to roll over and stay
Web-Slinger.css introduces a set of class names in the format .scroll-trigger-n and .on-scroll-trigger-n. It also defines --scroll-trigger-n custom properties, which are inherited from the document root so we can access them from any CSS class. These conventions are more verbose than Wow.js but also more powerful. The two types of CSS classes decouple the triggers of our one-off animations from the elements they trigger, which means we can animate anything on the page based on the user reaching any scroll marker.
Here’s a basic example that triggers the Animate.css animation “flipInY” when the user has scrolled to the <div> marked as .scroll-trigger-8.
A more advanced use is the sticky “Cownter” (trademark pending) at the top of the demo page, which takes advantage of the ability of one trigger to activate an arbitrary number of animations anywhere in the document. The Cownter increments as new cows appear then displays a reset button once we reach the final scroll trigger at the bottom of the page.
Sidenote: If you have doubts about the utility of style queries, behold the age-old cow pluralization problem solved in pure CSS.
How does Web Slinger like to sling it?
The secret is based on an iconic thought experiment by the philosopher Friedrich Nietzsche who once asked: If the view() function lets you style an element once it comes into view, what if you take that opportunity to style it so it can never be scrolled out of view? Would that element not stare back into you for eternity?
This idea sounded too good to be true, reminiscent of the urge when you meet a genie to ask for unlimited wishes. But it works! The next puzzle piece is how to use this one-way animation technique to control something we’d want to display to the user. Divs that instantly stick to the ceiling as soon as they enter the viewport might have their place on a page discussing the movie Alien, but most of the time this type of animation won’t be something we want the user to see.
That’s where named view progress timelines come in. The empty scroll trigger element only has the job of sticking to the top of the viewport as soon as it enters. Next, we set the timeline-scope property of the <body> element so that it matches the sticky element’s view-timeline-name. Now we can apply Ryan’s toggle custom property and style query tricks to let each sticky element trigger arbitrary one-off animations anywhere on the page!
View CSS code
/** Each trigger element will cause a toggle named with
* the convention `--scroll-trigger-n` to be flipped
* from 0 to 1, which will unpause the animation on
* any element with the class .on-scroll-trigger-n
**/
:root {
animation-name: run-scroll-trigger-1, run-scroll-trigger-2 /*etc*/;
animation-duration: 1ms;
animation-fill-mode: forwards;
animation-timeline: --trigger-timeline-1, --trigger-timeline-2 /*etc*/;
timeline-scope: --trigger-timeline-1, --trigger-timeline-2 /*etc*/;
}
@property --scroll-trigger-1 {
syntax: "<integer>";
initial-value: 0;
inherits: true;
}
@keyframes run-scroll-trigger-1 {
to {
--scroll-trigger-1: 1;
}
}
/** Add this class to arbitrary elements we want
* to only animate once `.scroll-trigger-1` has come
* into view, default them to paused state otherwise
**/
.on-scroll-trigger-1 {
animation-play-state: paused;
}
/** The style query hack will run the animations on
* the element once the toggle is set to true
**/
@container style(--scroll-trigger-1: 1) {
.on-scroll-trigger-1 {
animation-play-state: running;
}
}
/** The trigger element which sticks to the top of
* the viewport and activates the one-way animation
* that will unpause the animation on the
* corresponding element marked with `.on-scroll-trigger-n`
**/
.scroll-trigger-1 {
view-timeline-name: --trigger-timeline-1;
}
Trigger warning
We generate the genericized Web-Slinger.css in 95 lines of SCSS, which isn’t too bad. The drawback is that the more triggers we need, the larger the compiled CSS file. The numbered CSS classes also aren’t semantic, so it would be great to have native support for linking a scroll-triggered element to its trigger based on IDs, reminiscent of the popovertargetattribute for HTML buttons — except this hypothetical attribute would go on each target element and specify the ID of the trigger, which is the opposite of the way popovertarget works.
<!-- This is speculative — do not use -->
<scroll-trigger id="my-scroll-trigger"></scroll-trigger>
<div class="rollIn" scrolltrigger="my-scroll-trigger">Hello world</div>
Do androids dream of standardized scroll triggers?
As I mentioned at the start, Bramus has teased that scroll-triggered animations are something we’d like to ship in a future version of Chrome, but it still needs a bit of work before we can do that. I’m looking forward to standardized scroll-triggered animations built into the browser. We could do worse than a convention resembling Web-Slinger.css for declaratively defining scroll-triggered animations, but I know I am not objective about Web Slinger as its creator. It’s become a bit of a sacred cow for me so I shall stop milking the topic — for now.
Feel free to reference the prototype Web-Slinger.css library in your experimental CodePens, or fork the library itself if you have better ideas about how scroll-triggered animations could be standardized.
Every generation is different in very unique ways, with different habits, views, standards, and expectations. So when designing for Gen Z, what do we need to keep in mind? Let’s take a closer look at Gen Z, how they use tech, and why it might be a good idea to ignore common design advice and do the opposite of what is usually recommended instead.
This article is part of our ongoing series on UX. You can find more details on design patterns and UX strategy in Smart Interface Design Patterns 🍣 — with live UX training coming up soon. Free preview.
Gen Z: Most Diverse And Most Inclusive
When we talk about Generation Z, we usually refer to people born between 1995 and 2010. Of course making universal statements about a cohort where some are adults in their late 20s and others are school students is at best ineffective and at worst wrong — yet there are some attributes that stand out compared to earlier generations.
Gen Z is the most diverse generation in terms of race, ethnicity, and identity. Research shows that young people today are caring and proactive, and far from being “slow, passive and mindless” as they are often described. In fact, they are willing to take a stand and break their habits if they deeply believe in a specific purpose and goal. Surely there are many distractions along that way, but the belief in fairness and sense of purpose has enormous value.
Their values reflect that: accessibility, inclusivity, sustainability, and work/life balance are top priorities for Gen Zs, and they value experiences, principles, and social stand over possessions.
What Gen Z Deeply Cares About
Gen Z grew up with technology, so unsurprisingly digital experiences are very familiar and understood by them. On the other hand, digital experiences are often suboptimal at best — slow, inaccessible, confusing, and frustrating. Plus, the web is filled with exaggerations and generic but fluffy statements. So it’s not a big revelation that Gen Zs are highly skeptical of brands and advertising by default (rightfully so!), and rely almost exclusively on social circles, influencers, and peers as main research channels.
They might sometimes struggle to spot what’s real and what’s not, but they are highly selective about their sources. They are always connected and used to following events live as they unfold, so unsurprisingly, Gen Z tends to have little patience.
And sure enough, Gen Z loves short-form content, but that doesn’t necessarily equate to a short attention span. Attention span is context-dependent, as documentaries and literature are among Gen Z’s favorites.
Designing For Gen Z
Most design advice on Gen Z focuses on producing “short form, snackable, bite-sized” content. That content is optimized for very short attention spans, TikTok-alike content consumption, and simplified to the core messaging. I would strongly encourage us to do the opposite.
We shouldn’t discount Gen Z as a generation with poor attention spans and urgent needs for instant gratification. Gen Zs have very strong beliefs and values, but they are also inherently curious and want to reshape the world. We can tell a damn good story. Captivate and engage. Make people think. Many Gen Zs are highly ambitious and motivated, and they want to be challenged and to succeed. So let’s support that. And to do that, we need to remain genuine and authentic.
Remain Genuine And Authentic
As Michelle Winchester noted, Gen Zs have very diverse perspectives and opinions, and they possess a discerning ability to detect disingenuous content. That’s also where mistrust towards AI comes into play, along with AI fatigue. As Nilay Patel mentioned on Ezra Klein Show, today when somebody says that something is “AI-generated”, usually it’s not a praise, but rather a testament how poor and untrustworthy it actually is.
Gen Z expects better. Hence brands that value sincerity, honesty, and authenticity are perceived as more trustworthy compared to brands that don’t have an opinion, don’t take a stand, don’t act for their beliefs and principles. For example, the “Keep Beauty Real” campaign by Dove (shown below) showcases the value of genuine human beauty, which is so often missed and so often exaggerated to extremes by AI.
Gareth Ford Williams has put together a visual language of closed captions and has kindly provided a PDF cheatsheet that is commonly used by professional captioners. There are some generally established rules about captioning, and here are some that I found quite useful when working on captioning for my own video course:
Divide your sentences into two relatively equal parts like a pyramid (40ch per line for the top line, a bit less for the bottom line);
Always keep an average of 20 to 30 characters per second;
A sequence should only last between 1 and 8 seconds;
Always keep a person’s name or title together;
Do not break a line after conjunction;
Consider aligning multi-lined captions to the left.
On YouTube, users can select a font used for subtitles and choose between monospaced and proportional serif and sans-serif, casual, cursive, and small-caps. But perhaps, in addition to stylistic details, we could provide a careful selection of fonts to help audiences with different needs. This could include a dyslexic font or a hyper-legible font, for example.
Additionally, we could display presets for various high contrast options for subtitles. This gives users a faster selection, requiring less effort to configure just the right combination of colors and transparency. Still, it would be useful to provide more sophisticated options just in case users need them.
Support Intrinsic Motivation
On the other hand, in times of instant gratification with likes, reposts, and leaderboards, people often learn that a feeling of achievement comes from extrinsic signals, like reach or attention from other people. The more important it is to support intrinsic motivation.
As Paula Gomes noted, intrinsic motivation is characterized by engaging in behaviors just for their own sake. People do something because they enjoy it. It is when they care deeply for an activity and enjoy it without needing any external rewards or pressure to do it.
Typically this requires 3 components:
Competence involves the need to feel capable of achieving a desired outcome.
Autonomy is about the need to feel in control of your own actions, behaviors, and goals.
Relatedness reflects the need to feel a sense of belonging and attachment to other people.
In practical terms, that means setting people up for success. Preparing the knowledge and documents and skills they need ahead of time. Building knowledge up without necessarily rewarding them with points. It also means allowing people to have a strong sense of ownership of the decisions and the work they are doing. And adding collaborative goals that would require cooperation with team members and colleagues.
Encourage Critical Thinking
The younger people are, the more difficult it is to distinguish between what’s real and what isn’t. Whenever possible, show sources or at least explain where to find specific details that back up claims that you are making. Encourage people to make up their mind, and design content to support that — with scientific papers, trustworthy reviews, vetted feedback, and diverse opinions.
And: you don’t have to shy away from technical details. Don’t make them mandatory to read and understand, but make them accessible and available in case readers or viewers are interested.
In times where there is so much fake, exaggerated, dishonest, and AI-generated content, it might be just enough to be perceived as authentic, trustworthy, and attention-worthy by the highly selective and very demanding Gen Z.
Good Design Is For Everyone
I keep repeating myself like a broken record, but better accessibility is better for everyone. As you hopefully have noticed, many attributes and expectations that we see in Gen Z are beneficial for all other generations, too. It’s just good, honest, authentic design. And that’s the very heart of good UX.
What I haven’t mentioned is that Gen Z genuinely appreciates feedback and values platforms that listen to their opinions and make changes based on their feedback. So the best thing we can do, as designers, is to actively involve Gen Z in the design process. Designing with them, rather than designing for them.
And, most importantly: with Gen Z, perhaps for the first time ever, inclusion and accessibility is becoming a default expectation for all digital products. With it comes the sense of fairness, diversity, and respect. And, personally, I strongly believe that it’s a great thing — and a testament how remarkable Gen Zs actually are.
Wrapping Up
Large parts of Gen Z aren’t mobile-first, but mobile-only.
To some, the main search engine is YouTube, not Google.
Some don’t know and have never heard of Internet Explorer.
Trust only verified customer reviews, influencers, friends.
Used to follow events live as they unfold → little patience.
Sustainability, reuse, work/life balance are top priorities.
Prefer social login as the fastest authentication method.
Typically ignore or close cookie banners, without consent.
Rely on social proof, honest reviews/photos, authenticity.
Most likely generation to provide a referral to a product.
Typically turn on subtitles for videos by default.
I’ve just launched “How To Measure UX and Design Impact” 🚀 (8h), a new practical guide for UX leads to measure UX impact on business. Use the code 🎟 IMPACT to save 20% off today. And thank you for your kind and ongoing support, everyone! Jump to details.
Gain $200 in a week
from Articles on Smashing Magazine — For Web Designers And Developers https://ift.tt/2lFfadh
In this article, I try to summarize the best practices mentioned by various accessibility experts and their work (like this, this, and this) into a single article that’s easy to read, understand, and apply.
Let’s begin.
What are tooltips?
Tooltips are used to provide simple text hints for UI controls. Think of them as tips for tools. They’re basically little bubbles of text content that pop up when you hover over an unnamed control (like the bell icon in Stripe).
The “Notifications” text that pops up when you hover over Stripe’s bell icon is a tooltip.
If you prefer more of a formal definition, Sarah Highley provides us with a pretty good one:
A “tooltip” is a non-modal (or non-blocking) overlay containing text-only content that provides supplemental information about an existing UI control. It is hidden by default, and becomes available on hover or focus of the control it describes.
She further goes on to say:
That definition could even be narrowed down even further by saying tooltips must provide only descriptive text.
This narrowed definition is basically (in my experience) how every accessibility expert defines tooltips:
Heydon Pickering takes things even further, saying: If you’re thinking of adding interactive content (even an ok button), you should be using dialog instead.
If your tooltip is used to label an icon — using only one or two words — you should use the aria-labelledby attribute to properly label it since it is attached to nothing else on the page that would help identify it.
You could provide contextual information, like stating the number of notifications, by giving a space-separated list of ids to aria-labelledby.
<button aria-labelledby="notifications-count notifications-label">
<!-- bell icon here -->
<span id="notifications-count">3</span>
</button>
<div role="tooltip" id="notifications-label">Notifications</div>
Providing contextual description
If your tooltip provides a contextual description of the icon, you should use aria-describedby. But, when you do this, you also need to provide an accessible name for the icon.
In this case, Heydon recommends including the label as the text content of the button. This label would be hidden visually from sighted users but read for screen readers.
Then, you can add aria-describedby to include the auxiliary description.
<button class="notifications" aria-describedby="notifications-desc">
<!-- icon for bell here -->
<span id="notifications-count">3</span>
<span class="visually-hidden">Notifications</span>
</button>
<div role="tooltip" id="notifications-desc">View and manage notifications settings</div>
Here, screen readers would say “3 notifications” first, followed by “view and manage notifications settings” after a brief pause.
Additional tooltip dos and don’ts
Here are a couple of additional points you should be aware of:
Do:
Use aria-labellebdy or aria-describedby attributes depending on the type of tooltip you’re building.
Don’t use the aria-haspopup attribute with the tooltip role because aria-haspopup signifies interactive content while tooltip should contain non-interactive content.
Don’t include essential content inside tooltips because some screen readers may ignore aria-labelledby or aria-describedby. (It’s rare, but possible.)
Tooltip limitations and alternatives
Tooltips are inaccessible to most touch devices because:
users cannot hover over a button on a touch device, and
users cannot focus on a button on a touch device.
The best alternative is not to use tooltips, and instead, find a way to include the label or descriptive text in the design.
If the “tooltip” contains a lot of content — including interactive content — you may want to display that information with a Toggletip (or just use a <dialog> element).
Toggletips exist to reveal information balloons. Often they take the form of little “i” icons.
These informational icons should be wrapped within a <button> element. When opened, screen readers can announce the text contained in it through a live region with the status role.
Speaking anymore about toggletips detracts this article from tooltips so I’ll point you to Heydon’s “Tooltips and Toggletips” article if you’re interested in chasing this short rabbit hole.
That’s all you need to know about tooltips and their current best practices!
A whole bunch of years ago, we posted on this idea here on CSS-Tricks. We figured it was time to update that and do the subject justice.
Imagine a scenario where you need to split a layout in half. Content on the left and content on the right. Basically two equal height columns are needed inside of a container. Each side takes up exactly half of the container, creating a distinct break between one. Like many things in CSS, there are a number of ways to go about this and we’re going to go over many of them right now!
One simple way we can create the appearance of a changing background is to use gradients. Half of the background is set to one color and the other half another color. Rather than fade from one color to another, a zero-space color stop is set in the middle.
This works with a single container element. However, that also means that it will take working with floats or possibly some other layout method if content needs to fill both sides of the container.
Using Absolute Positioning
Another route might be to set up two containers inside of a parent container, position them absolutely, split them up in halves using percentages, then apply the backgrounds. The benefit here is that now we have two separate containers that can hold their own content.
Absolute positioning is sometimes a perfect solution, and sometimes untenable. The parent container here will need to have a set height, and setting heights is often bad news for content (content changes!). Not to mention absolute positioned elements are out of the document flow. So it would be hard to get this to work while, say, pushing down other content below it.
Using (fake) Tables
Yeah, yeah, tables are so old school (not to mention fraught with accessibility issues and layout inflexibility). Well, using the display: table-cell; property can actually be a handy way to create this layout without writing table markup in HTML. In short, we turn our semantic parent container into a table, then the child containers into cells inside the table — all in CSS!
You could even change the display properties at breakpoints pretty easily here, making the sides stack on smaller screens. display: table; (and friends) is supported as far back as IE 8 and even old Android, so it’s pretty safe!
Using Floats
We can use our good friend the float to arrange the containers beside each other. The benefit here is that it avoids absolute positioning (which as we noted, can be messy).
In this example, we’re explicitly setting heights to get them to be even. But you don’t really get that ability with floats by default. You could use the background gradient trick we already covered so they just look even. Or look at fancy negative margin tricks and the like.
Also, remember you may need to clear the floats on the parent element to keep the document flow happy.
Using Inline-Block
If clearing elements after floats seems like a burden, then using display: inline-block is another option. The trick here is to make sure that the elements for the individual sides have no breaks or whitespace in between them in the HTML. Otherwise, that space will be rendered as a literal space and the second half will break and fall.
Again there is nothing about inline-block that helps us equalize the heights of the sides, so you’ll have to be explicit about that.
There are also other potential ways to deal with that spacing problem described above.
Using this method, we turn our parent container into a flexible box with the child containers taking up an equal share of the space. No need to set widths or heights! Flexbox just knows what to do, because the defaults are set up perfectly for this. For instance, flex-direction: row; and align-items: stretch; is what we’re after, but those are the defaults so we don’t have to set them. To make sure they are even though, setting flex: 1; on the sides is a good plan. That forces them to take up equal shares of the space.
In this demo we’re making the side flex containers as well, just for fun, to handle the vertical and horizontal centering.
Using Grid Layout
For those living on the bleeding edge, the CSS Grid Layout technique is like the Flexbox and Table methods merged into one. In other words, a container is defined, then split into columns and cells which can be filled flexibly with child elements.
CSS Anchor Positioning
This started rolling out in 2024 and we’re still waiting for full browser support. But we can use CSS Anchor Positioning to “attach” one element to another — even if those two elements are completely unrelated in the markup.
The idea is that we have one element that’s registered as an “anchor” and another element that’s the “target” of that anchor. It’s like the target element is pinned to the anchor. And we get to control where we pin it!
This sets up an .anchor and establishes a relationship with a .target element. From here, we can tell the target which side of the anchor it should pin to.
You’d be forgiven for thinking coding up both a dark and a light mode at once is a lot of work. You have to remember @media queries based on prefers-color-scheme as well as extra complications that arise when letting visitors choose whether they want light or dark mode separately from the OS setting. And let’s not forget the color palette itself! Switching from a “light” mode to a “dark” mode may involve new variations to get the right amount of contrast for an accessible experience.
It is indeed a lot of work. But I’m here to tell you it’s now a lot simpler with modern CSS!
Default HTML color scheme(s)
We all know the “naked” HTML theme even if we rarely see it as we’ve already applied a CSS reset or our favorite boilerplate CSS before we even open localhost. But here’s a news flash: HTML doesn’t only have the standard black-on-white theme, there is also a native white-on-black version.
We have two color schemes available to use right out of the box!
If you want to create a dark mode interface, this is a great base to work with and saves you from having to account for annoying details, like dark inputs, buttons, and other interactive elements.
Switching color schemes automatically based on OS preference
Without any @mediaqueries — or any other CSS at all — if all we did was declare color-scheme: light dark on the root element, the page will apply either the light or dark color scheme automatically by looking at the visitor’s operating system (OS) preferences. Most OSes have a built-in accessibility setting for your preferred color scheme — “light”, “dark”, or even “auto” — and browsers respect that setting.
html {
color-scheme: light dark;
}
We can even accomplish this without CSS directly in the HTML document in a <meta> tag:
<meta name="color-scheme" content="light dark">
Whether you go with CSS or the HTML route, it doesn’t matter — they both work the same way: telling the browser to make both light and dark schemes available and apply the one that matches the visitor’s preferences. We don’t even need to litter our styles with prefers-color-scheme instances simply to swap colors because the logic is built right in!
You can apply light or dark values to the color-scheme property. At the same time, I’d say that setting color-scheme: light is redundant, as this is the default color scheme with or without declaring it.
You can, of course, control the <meta> tag or the CSS property with JavaScript.
There’s also the possibility of applying the color-scheme property on specific elements instead of the entire page in one fell swoop. Then again, that means you are required to explicitly declare an element’s color and background-color properties; otherwise the element is transparent and inherits its text color from its parent element.
What values should you give it? Try:
Default text and background color variables
The “black” colors of these native themes aren’t always completely black but are often off-black, making the contrast a little easier on the eyes. It’s worth noting, too, that there’s variation in the blackness of “black” between browsers.
What is very useful is that this default not-pure-black and maybe-not-pure-white background-color and text color are available as <system-color> variables. They also flip their color values automatically with color-scheme!
They are: Canvas and CanvasText.
These two variables can be used anywhere in your CSS to call up the current default background color (Canvas) or text color (CanvasText) based on the current color scheme. If you’re familiar with the currentColor value in CSS, it seems to function similarly. CanvasText, meanwhile, remains the default text color in that it can’t be changed the way currentColor changes when you assign something to color.
In the following examples, the only change is the color-scheme property:
Not bad! There are many, many more of these system variables. They are case-insensitive, often written in camelCase or PascalCase for readability. MDN lists 19 <system-color> variables and I’m dropping them in below for reference.
Open to view 19 system color names and descriptions
AccentColor: The background color for accented user interface controls
AccentColorText: The text color for accented user interface controls
ActiveText: The text color of active links
ButtonBorder: The base border color for controls
ButtonFace: The background color for controls
ButtonText: The text color for controls
Canvas: The background color of an application’s content or documents
CanvasText: The text color used in an application’s content or documents
Field: The background color for input fields
FieldText: The text color inside form input fields
GrayText: The text color for disabled items (e.g., a disabled control)
Highlight: The background color for selected items
HighlightText: The text color for selected items
LinkText: The text color used for non-active, non-visited links
Mark: The background color for text marked up in a <mark> element
MarkText: The text color for text marked up in a <mark> element
SelectedItem: The background color for selected items (e.g., a selected checkbox)
SelectedItemText: The text color for selected items
VisitedText: The text visited links
Cool, right? There are many of them! There are, unfortunately, also discrepancies as far as how these color keywords are used and rendered between different OSes and browsers. Even though “evergreen” browsers arguably support all of them, they don’t all actually match what they’re supposed to, and fail to flip with the CSS color-scheme property as they should.
Egor Kloos (also known as dutchcelt) is keeping an eye on the current status of system colors, including which ones exist and the browsers that support them, something he does as part of a classless CSS framework cleverly called system.css.
Declaring colors for both modes together
OK good, so now you have a page that auto-magically flips dark and light colors according to system preferences. Whether you choose to use these system colors or not is up to you. I just like to point out that “dark” doesn’t always have to mean pure “black” just as “light” doesn’t have to mean pure “white.” There are lots more colors to pair together!
But what’s the best or simplest way to declare colors so they work in both light and dark mode?
In my subjective reverse-best order:
Third place: Declare color opacity
You could keep all the same background colors in dark and light modes, but declare them with an opacity (i.e. rgb(128 0 0 / 0.5) or #80000080). Then they’ll have the Canvas color shine through.
It’s unusable in this way for text colors, and you may end up with somewhat muted colors. But it is a nice easy way to get some theming done fast. I did this for the code blocks on this old light and dark mode demo.
Second place: Use color-mix()
Like this:
color-mix(in oklab, Canvas 75%, RebeccaPurple);
Similar (but also different) to using opacity to mute a color is mixing colors in CSS. We can even mix the system color variables! For example, one of the colors can be either Canvas or CanvasText so that the background color always mixes with Canvas and the text color always mixes with CanvasText.
We now have the CSS color-mix() function to help us with this. The first argument in the function defines the color space where the color mixing happens. For example, we can tell the function that we are working in the OKLAB color space, which is a rectangular color space like sRGB making it ideal to mix with sRGB color values for predictable results. You can certainly mix colors from different color spaces — the OKLAB/sRGB combination happens to work for me in this instance.
The second and third arguments are the colors you want to mix, and in what proportion. Proportions are optional but expressed in percentages. Without declaring a proportion, the mix is an even 50%-50% split. If you add percentages for both colors and they don’t match up to 100%, it does a little math for you to prevent breakages.
The color-mix() approach is useful if you’re happy to keep the same hues and color saturations regardless of whether the mode is light or dark.
In this example, as you change the value of the hue slider, you’ll see color changes in the themed boxes, following the theme color but mixed with Canvas and CanvasText:
You may have noticed that I used OKLCH and HSL color spaces in that last example. You may also have noticed that the HSL-based theme color and the themed paragraph were a lot more “flashy” as you moved the hue slider.
I’ve declared colors using a polar color space, like HSL, for years, loving that you can easily take a hue and go up or down the saturation and lightness scales based on need. But, I concede that it’s problematic if you’re working with multiple hues while trying to achieve consistent perceived lightness and saturation across them all. It can be difficult to provide ample contrast across a spectrum of colors with HSL.
The OKLCH color space is also polar just like HSL, with the same benefits. You can pick your hue and use the chroma value (which is a bit like saturation in HSL) and the lightness scales accurately in the same way. Both OKLCH and OKLAB are designed to better match what our eyes perceive in terms of brightness and color compared to transitioning between colors in the sRGB space.
While these color spaces may not explicitly answer the age-old question, Is my blue the same as your blue? the colors are much more consistent and require less finicking when you decide to base your whole website’s palette on a different theme color. With these color spaces, the contrasts between the computed colors remain much the same.
First place (winner!): Use light-dark()
Like this:
light-dark(lavender, saddlebrown);
With the previous color-mix() example, if you choose a pale lavender in light mode, its dark mode counterpart is very dark lavender.
The light-dark() function, conversely, provides complete control. You might want that element to be pale lavender in light mode and a deep burnt sienna brown in dark mode. Why not? You can still use color-mix() within light-dark() if you like — declare the colors however you like, and gain much more fine-grained control over your colors.
Feel free to experiment in the following editable demo:
Using color-scheme: light dark; — or the corresponding meta tag in HTML on your page —is a prerequisite for the light-dark() function because it allows the function to respect a person’s system preference, or whichever single light or dark value you have set on color-scheme.
Another consideration is that light-dark() is newly available across browsers, with just over 80% coverage across all users at the time I’m writing this. So, you might consider including a fallback in your CSS for browsers that lack support for the function.
What makes using color-scheme and light-dark() better than using @media queries?
@media queries have been excellent tools, but using them to query prefers-color-scheme only ever follows the preference set within the person’s operating system. This is fine until you (rightfully) want to offer the visitor more choices, decoupled from whether they prefer the UI on their device to be dark or light.
We’re already capable of doing that, of course. We’ve become used to a lot of jiggery-pokery with extra CSS classes, using duplicated styles, or employing custom properties to make it happen.
The joy of using color-scheme is threefold:
It gives you the basic monochrome dark mode for free!
It can natively do the mode switching based on OS mode preference.
You can use JavaScript to toggle between light and dark mode, and the colors declared in the light-dark() functions will follow it.
Light, dark, and auto mode controls
Essentially, all we are doing is setting one of three options for whether the color-scheme is light, dark, or updates auto-matically.
I advise offering all three as discrete options, as it removes some complications for you! Any new visitor to the site will likely be in auto mode because accepting the visitor’s OS setting is the least jarring default state. You then give that person the choice to stay with that or swap it out for a different color scheme. This way, there’s no need to sniff out what mode someone prefers to, for example, display the correct icon on a toggle and make it perform the correct action. There is also no need to keep an event listener on prefers-color-scheme in case of changes — your color-scheme: light dark declaration in CSS handles that for you.
Adjusting color-scheme in pure CSS
Yes, this is totally possible! But the approach comes with a few caveats:
You can’t use <button> — only radio inputs, or <options> in a <select> element.
It only works on a per page basis, not per website, which means changes are lost on reload or refresh.
The browser needs to support the :has() pseudo-selector. Most modern browsers do, but some folks using older devices might miss out on the experience.
Using the :has() pseudo-selector
This approach is almost alarmingly simple and is fantastic for a simple one-pager! Most of the heavy lifting is done with this:
The second and third rulesets above look for an attribute called value on any element that has “light” or “dark” assigned to it, then change the color-scheme to match only if that element is :checked.
This approach is not very efficient if you have a huge page full of elements. In those cases, it’s better to be more specific. In the following two examples, the CSS selectors check for value only within an element containing id="mode-switcher".
html:has(#mode-switcher [value="light"]:checked) { color-scheme: light }
/* Did you know you don't need the ";" for a one-liner? Now you do! */
Using a <select> element:
Using <input type="radio">:
We could theoretically use checkboxes for this, but since checkboxes are not supposed to be used for mutually exclusive options, I won’t provide an example here. What happens in the case of more than one option being checked? The last matching CSS declaration wins (which is dark in the examples above).
JavaScript should only do what only JavaScript can do.
This is exactly that kind of situation.
If you want to allow visitors to change the color scheme using buttons, or you would like the option to be saved the next time the visitor comes to the site, then we do need at least some JavaScript. Rather than using the :has() pseudo-selector in CSS, we have a few alternative approaches for changing the color-scheme when we add JavaScript to the mix.
Using <meta> tags
If you have set your color-scheme within a meta tag in the <head> of your HTML:
<meta name="color-scheme" content="light dark">
…you might start by making a useful constant like so:
And then you can manipulate that, assigning it light or dark as you see fit:
colorScheme.setAttribute("content", "light"); // to light mode
colorScheme.setAttribute("content", "dark"); // to dark mode
colorScheme.setAttribute("content", "light dark"); // to auto mode
This is a very similar approach to using <meta> tags but is different if you are setting the color-scheme property in CSS:
html { color-scheme: light dark; }
Instead of setting a colorScheme constant as we just did in the last example with the <meta> tag, you might select the <html> element instead:
const html = document.querySelector('html');
Now your manipulations look like this:
html.style.setProperty("color-scheme", "light"); // to light mode
html.style.setProperty("color-scheme", "dark"); // to dark mode
html.style.setProperty("color-scheme", "light dark"); // to auto mode
I like to turn those manipulations into functions so that I can reuse them:
function switchAuto() {
html.style.setProperty("color-scheme", "light dark");
}
function switchLight() {
html.style.setProperty("color-scheme", "light");
}
function switchDark() {
html.style.setProperty("color-scheme", "dark");
}
Alternatively, you might like to stay as DRY as possible and do something like this:
The following demo shows how this JavaScript-based approach can be used with buttons, radio buttons, and a <select> element. Please note that not all of the controls are hooked up to update the UI — the demo would end up too complicated since there’s no world where all three types of controls would be used in the same UI!
I opted to use onchange and onclick in the HTML elements mainly because I find them readable and neat. There’s nothing wrong with instead attaching a change event listener to your controls, especially if you need to trigger other actions when the options change. Using onclick on a button doesn’t only work for clicks, the button is still keyboard-focusable and can be triggered with Spacebar and Enter too, as usual.
Remembering the selection for repeat visits
The biggest caveat to everything we’ve covered so far is that this only works once. In other words, once the visitor has left the site, we’re doing nothing to remember their color scheme preference. It would be a better user experience to store that preference and respect it anytime the visitor returns.
The Web Storage API is our go-to for this. And there are two available ways for us to store someone’s color scheme preference for future visits.
localStorage
Local storage saves values directly on the visitor’s device. This makes it a nice way to keep things off your server, as the stored data never expires, allowing us to call it anytime. That said, we’re prone to losing that data whenever the visitor clears cookies and cache and they’ll have to make a new selection that is freshly stored in localStorage.
You pick a key name and give it a value with .setItem():
localStorage.setItem("mode", "dark");
The key and value are saved by the browser, and can be called up again for future visits:
const mode = localStorage.getItem("mode");
You can then use the value stored in this key to apply the person’s preferred color scheme.
sessionStorage
Session storage is thrown away as soon as a visitor browses away to another site or closes the current window/tab. However, the data we capture in sessionStorage persists while the visitor navigates between pages or views on the same domain.
Personally, I started with sessionStorage because I wanted my site to be as simple as possible, and to avoid anything that would trigger the need for a GDPR-compliant cookie banner if we were holding onto the person’s preference after their session ends. If most of your traffic comes from new visitors, then I suggest using sessionStorage to prevent having to do extra work on the GDPR side of things.
That said, if your traffic is mostly made up of people who return to the site again and again, then localStorage is likely a better approach. The convenience benefits your visitors, making it worth the GDPR work.
The following example shows the localStorage approach. Open it up in a new window or tab, pick a theme other than what’s set in your operating system’s preferences, close the window or tab, then re-open the demo in a new window or tab. Does the demo respect the color scheme you selected? It should!
Choose the “Auto” option to go back to normal.
If you want to look more closely at what is going on, you can open up the developer tools in your browser (F12 for Windows, CTRL+ click and select “Inspect” for macOS). From there, go into the “Application” tab and locate https://cdpn.io in the list of items stored in localStorage. You should see the saved key (mode) and the value (dark or light). Then start clicking on the color scheme options again and watch the mode update in real-time.
Accessibility
Congratulations! If you have got this far, you are considering or already providing versions of your website that are more comfortable for different people to use.
For example:
People with strong floaters in their eyes may prefer to use dark mode.
People with astigmatism may be able to focus more easily in light mode.
So, providing both versions leaves fewer people straining their eyes to access the content.
Contrast levels
I want to include a small addendum to this provision of a light and dark mode. An easy temptation is to go full monochrome black-on-white or white-on-black. It’s striking and punchy! I get it. But that’s just it — striking and punchy can also trigger migraines for some people who do a lot better with lower contrasts.
Providing high contrast is great for the people who need it. Some visual impairments do make it impossible to focus and get a sharp image, and a high contrast level can help people to better make out the word shapes through a blur. Minimum contrast levels are important and should be exceeded.
Thankfully, alongside other media queries, we can also query prefers-contrast which accepts values for no-preference, more, less, or custom.
In the following example (which uses :has() and color-mix()), a <select> element is displayed to offer contrast settings. When “Low” is selected, a filter of contrast(75%) is placed across the page. When “High” is selected, CanvasText and Canvas are used unmixed for text color and background color:
Adding a quick high and low contrast theme gives your visitors even more choice for their reading comfort. Look at that — now you have three contrast levels in both dark and light modes — six color schemes to choose from!
ARIA-pressed
ARIA stands for Accessible Rich Internet Applications and is designed for adding a bit of extra info where needed to screen readers and other assistive tech.
The words “where needed” do heavy lifting here. It has been said that, like apostrophes, no ARIA is better than bad ARIA. So, best practice is to avoid putting it everywhere. For the most part (with only a few exceptions) native HTML elements are good to go out of the box, especially if you put useful text in your buttons!
The little bit of ARIA I use in this demo is for adding the aria-pressed attribute to the buttons, as unlike a radio group or select element, it’s otherwise unclear to anyone which button is the “active” one, and ARIA helps nicely with this use case. Now a screen reader will announce both its accessible name and whether it is in a pressed or unpressed state along with a button.
Following is an example code snippet with all the ARIA code bolded — yes, suddenly there’s lots more! You may find more elegant (or DRY-er) ways to do this, but showing it this way first makes it more clear to demonstrate what’s happening.
Our buttons have ids, which we have used to target them with some more handy consts at the top. Each time we switch mode, we make the button’s aria-pressed value for the selected mode true, and the other two false:
On load, the buttons have a default setting, which is when the “Auto” mode button is active. Should there be any other mode in the localStorage, we pick it up immediately and run either switchLight() or switchDark(), both of which contain the aria-pressed changes relevant to that mode.
Finally, we have a nice little button switcher, with its state clearly shown and announced, that remembers your choice when you come back to it. Done!
Outroduction
Or whatever the opposite of an introduction is…
…don’t let yourself get dragged into the old dark vs light mode argument. Both are good. Both are great! And both modes are now easy to create at once. At the start of your next project, work or hobby, do not give in to fear and pick a side — give both a try, and give in to choice.
One of the interesting (but annoying) things about CSS is the background of children’s elements can bleed out of the border radius of the parent element. Here’s an example of a card with an inner element. If the inner element is given a background, it can bleed out of the card’s border.
The easiest way to resolve this problem is to add overflow: hidden to the card element. I’m sure that’s the go-to solution most of us reach for when this happens.
But doing this creates a new problem — content outside the card element gets clipped off — so you can’t use negative margins or position: absolute to shift the children’s content out of the card.
There is a slightly more tedious — but more effective — way to prevent a child’s background from bleeding out of the parent’s border-radius. And that is to add the same border-radius to the child element.
The easiest way to do this is allowing the child to inherit the parent’s border-radius:
.child {
border-radius: inherit;
}
If the border-radius shorthand is too much, you can still inherit the radius for each of the four corners on a case-by-case basis:
Or, for those of you who’re willing to use logical properties, here’s the equivalent. (For an easier way to understand logical properties, replace top and left with start, and bottom and right with end.)
If you have a background directly on the .card that contains the border-radius, you will achieve the same effect. So, why not?
Well, sometimes you can’t do that. One situation is when you have a .card that’s split into two, and only one part is colored in.
So, why should we do this?
Peace of mind is probably the best reason. At the very least, you know you won’t be creating problems down the road with the radius manipulation solution.
This pattern is going to be especially helpful when CSS Anchor Positioning gains full support. I expect that would become the norm popover positioning soon in about 1-2 years.
That said, for popovers, I personally prefer to move the popover content out of the document flow and into the <body> element as a direct descendant. By doing this, I prevent overflow: hidden from cutting off any of my popovers when I use anchor positioning.
Did you see this post that Chris Coyier published back in August? He experimented with CSS container query units, going all in and using them for every single numeric value in a demo he put together. And the result was… not too bad, actually.
What I found interesting about this is how it demonstrates the complexity of sizing things. We’re constrained to absolute and relative units in CSS, so we’re either stuck at a specific size (e.g., px) or computing the size based on sizing declared on another element (e.g., %, em, rem, vw, vh, and so on). Both come with compromises, so it’s not like there is a “correct” way to go about things — it’s about the element’s context — and leaning heavily in any one direction doesn’t remedy that.
I thought I’d try my own experiment but with the CSS min() function instead of container query units. Why? Well, first off, we can supply the function with any type of length unit we want, which makes the approach a little more flexible than working with one type of unit. But the real reason I wanted to do this is personal interest more than anything else.
The Demo
I won’t make you wait for the end to see how my min() experiment went:
We’ll talk about that more after we walk through the details.
A Little About min()
The min() function takes two values and applies the smallest one, whichever one happens to be in the element’s context. For example, we can say we want an element to be as wide as 50% of whatever container it is in. And if 50% is greater than, say 200px, cap the width there instead.
So, min() is sort of like container query units in the sense that it is aware of how much available space it has in its container. But it’s different in that min() isn’t querying its container dimensions to compute the final value. We supply it with two acceptable lengths, and it determines which is best given the context. That makes min() (and max() for that matter) a useful tool for responsive layouts that adapt to the viewport’s size. It uses conditional logic to determine the “best” match, which means it can help adapt layouts without needing to reach for CSS media queries.
The difference between min() and @media in that example is that we’re telling the browser to set the element’s width to 50% at a specific breakpoint of 600px. With min(), it switches things up automatically as the amount of available space changes, whatever viewport size that happens to be.
When I use the min(), I think of it as having the ability to make smart decisions based on context. We don’t have to do the thinking or calculations to determine which value is used. However, using min() coupled with just any CSS unit isn’t enough. For instance, relative units work better for responsiveness than absolute units. You might even think of min() as setting a maximum value in that it never goes below the first value but also caps itself at the second value.
I mentioned earlier that we could use any type of unit in min(). Let’s take the same approach that Chris did and lean heavily into a type of unit to see how min() behaves when it is used exclusively for a responsive layout. Specifically, we’ll use viewport units as they are directly relative to the size of the viewport.
Now, there are different flavors of viewport units. We can use the viewport’s width (vw) and height (vh). We also have the vmin and vmax units that are slightly more intelligent in that they evaluate an element’s width and height and apply either the smaller (vmin) or larger (vmax) of the two. So, if we declare 100vmax on an element, and that element is 500px wide by 250px tall, the unit computes to 500px.
That is how I am approaching this experiment. What happens if we eschew media queries in favor of only using min() to establish a responsive layout and lean into viewport units to make it happen? We’ll take it one piece at a time.
Font Sizing
There are various approaches for responsive type. Media queries are quickly becoming the “old school” way of doing it:
p { font-size: 1.1rem; }
@media (min-width: 1200px) {
p { font-size: 1.2rem; }
}
@media (max-width: 350px) {
p { font-size: 0.9rem; }
}
Sure, this works, but what happens when the user uses a 4K monitor? Or a foldable phone? There are other tried and true approaches; in fact, clamp() is the prevailing go-to. But we’re leaning all-in on min(). As it happens, just one line of code is all we need to wipe out all of those media queries, substantially reducing our code:
p { font-size: min(6vmin, calc(1rem + 0.23vmax)); }
I’ll walk you through those values…
6vmin is essentially 6% of the browser’s width or height, whichever is smallest. This allows the font size to shrink as much as needed for smaller contexts.
For calc(1rem + 0.23vmax), 1rem is the base font size, and 0.23vmax is a tiny fraction of the viewport‘s width or height, whichever happens to be the largest.
The calc() function adds those two values together. Since 0.23vmax is evaluated differently depending on which viewport edge is the largest, it’s crucial when it comes to scaling the font size between the two arguments. I’ve tweaked it into something that scales gradually one way or the other rather than blowing things up as the viewport size increases.
Finally, the min() returns the smallest value suitable for the font size of the current screen size.
And speaking of how flexible the min() approach is, it can restrict how far the text grows. For example, we can cap this at a maximum font-size equal to 2rem as a third function parameter:
p { font-size: min(6vmin, calc(1rem + 0.23vmax), 2rem); }
This isn’t a silver bullet tactic. I’d say it’s probably best used for body text, like paragraphs. We might want to adjust things a smidge for headings, e.g., <h1>:
We’ve bumped up the minimum size from 6vmin to 7.5vmin so that it stays larger than the body text at any viewport size. Also, in the calc(), the base size is now 2rem, which is smaller than the default UA styles for <h1>. We’re using 1.2vmax as the multiplier this time, meaning it grows more than the body text, which is multiplied by a smaller value, .023vmax.
This works for me. You can always tweak these values and see which works best for your use. Whatever the case, the font-size for this experiment is completely fluid and completely based on the min() function, adhering to my self-imposed constraint.
Margin And Padding
Spacing is a big part of layout, responsive or not. We need margin and padding to properly situate elements alongside other elements and give them breathing room, both inside and outside their box.
We’re going all-in with min() for this, too. We could use absolute units, like pixels, but those aren’t exactly responsive.
min() can combine relative and absolute units so they are more effective. Let’s pair vmin with px this time:
div { margin: min(10vmin, 30px); }
10vmin is likely to be smaller than 30px when viewed on a small viewport. That’s why I’m allowing the margin to shrink dynamically this time around. As the viewport size increases, whereby 10vmin exceeds 30px, min() caps the value at 30px, going no higher than that.
Notice, too, that I didn’t reach for calc() this time. Margins don’t really need to grow indefinitely with screen size, as too much spacing between containers or elements generally looks awkward on larger screens. This concept also works extremely well for padding, but we don’t have to go there. Instead, it might be better to stick with a single unit, preferably em, since it is relative to the element’s font-size. We can essentially “pass” the work that min() is doing on the font-size to the margin and padding properties because of that.
Now, padding scales with the font-size, which is powered by min().
Widths
Setting width for a responsive design doesn’t have to be complicated, right? We could simply use a single percentage or viewport unit value to specify how much available horizontal space we want to take up, and the element will adjust accordingly. Though, container query units could be a happy path outside of this experiment.
But we’re min() all the way!
min() comes in handy when setting constraints on how much an element responds to changes. We can set an upper limit of 650px and, if the computed width tries to go larger, have the element settle at a full width of 100%:
.container { width: min(100%, 650px); }
Things get interesting with text width. When the width of a text box is too long, it becomes uncomfortable to read through the texts. There are competing theories about how many characters per line of text is best for an optimal reading experience. For the sake of argument, let’s say that number should be between 50-75 characters. In other words, we ought to pack no more than 75 characters on a line, and we can do that with the ch unit, which is based on the 0 character’s size for whatever font is in use.
p {
width: min(100%, 75ch);
}
This code basically says: get as wide as needed but never wider than 75 characters.
Sizing Recipes Based On min()
Over time, with a lot of tweaking and modifying of values, I have drafted a list of pre-defined values that I find work well for responsively styling different properties:
There we go! We have a heading that scales flawlessly, a container that’s responsive and never too wide, and a grid with dynamic spacing — all without a single media query. The --size- properties declared in the variable list are the most versatile, as they can be used for properties that require scaling, e.g., margins, paddings, and so on.
The Final Result, Again
I shared a video of the result, but here’s a link to the demo.
So, is min() the be-all, end-all for responsiveness? Absolutely not. Neither is a diet consisting entirely of container query units. I mean, it’s cool that we can scale an entire webpage like this, but the web is never a one-size-fits-all beanie.
If anything, I think this and what Chris demoed are warnings against dogmatic approaches to web design as a whole, not solely unique to responsive design. CSS features, including length units and functions, are tools in a larger virtual toolshed. Rather than getting too cozy with one feature or technique, explore the shed because you might find a better tool for the job.
Gain $200 in a week
from Articles on Smashing Magazine — For Web Designers And Developers https://ift.tt/5aRKjwJ
What’s in a word? Actions. In the realm of user interfaces, a word is construed as the telltale of a control’s action. Sometimes it points us in the correct direction, and sometimes it leads us astray. We talk a lot about semantics in front-end web development, but outside of code, semantics are at the heart of copywriting where each word we convey can mean different things to different people. Words, if done right, add clarity and direction.
As a web user, I’ve come across words in user interfaces that have misled me. And not necessarily by design, either. Some words are synonymous with others and their true meaning depends entirely on context. Some words are easy to mistake for an unintended meaning because they are packed with so much meaning. A word might belong to a fellowship of interchangeable words.
Although I’m quite riled up when I misread content on a page — upset at the lack of clarity more than anything — as a developer, I can’t say I’ve always chosen the best possible words or combination of words for all the user interfaces I’ve ever made. But experience, both as a user and a developer, has elevated my commonsense when it comes to some of the literary choices I make while coding.
This article covers the words I choose for endings, to help users move away, and move on, without any confusion from the current process they are at on the screen. I went down this rabbit hole because I often find that ending something can mean many things — whether it be canceling an action, quitting an application, closing an element, navigating back, exiting a chat interaction… You get the idea. There are many ways to say that something is done, complete, and ready to move on to something else. I want to add clarity to that.
Getting Canceled
If there’s a Hall of Fame for button labels, this is the Babe Ruth of them all. “Cancel” is a widely used word to indicate an action that ends something. Cancel is a sharp, tenacious action. The person wants to bail on some process that didn’t go the way they expected it to. Maybe the page reveals a form that the person didn’t realize would be so long, so they want to back off. It could be something you have no control over whatsoever, like that person realizing they do not have their credit card information handy during checkout and they have to come back another time.
Cancel can feel personal at times, right? Don’t like the shipping costs calculated at checkout? Cancel the payment. Don’t like the newsletter? Cancel The Subscription. But really, the person only wants to undo an incorrect action or decision leaving no trace of it behind in favor of a clean slate to try again… or not.
The only times I feel betrayed by the word cancel is when the process I’m trying to end continues anyway. That comes up most when submitting forms with incorrect information. I enter something inadvertently, hit a big red Cancel button, yet the information I’ve “saved” persists to the extent that I either need to contact customer support or start looking for alternatives.
That’s the bottom line: Use “cancel” as an opportunity to confirm. It’s the person telling you, “Hey, that’s not actually what I meant to do,” and you get to step in and be the hero to wipe the mistake clean and set things up for a second chance. We’re not technically “ending” anything but rather starting clean and picking things back up for a better go. Think about that the next time you find yourself needing a label that encourages the user to try again. You might even consider synonyms that are less closely associated with closed endings, such as reset or retry.
Quitting or Exiting?
Quit window, quit tab, quit app — now we’re talking about finality. When we “quit” or “exit” something, we’re changing course. We’ve made progress in one direction and decide it’s time to chart a different path. If we’re thinking about it in terms of freeway traffic, you might say that “quitting” is akin to pulling over and killing the engine, and “exiting” is taking leaving the freeway for another road. There’s a difference, although the two terms are closely related.
As far as we’re concerned as developers, quit and exit are hard stop points in an application. It’s been put to rest. Nothing else beyond this should be possible except its rebirth when the service is restarted or reopened. So, if your page is capable of nuking the current experience and the user takes it, then quit is the better label to make that point. We’re quitting and have no plans to restart or re-engage. If you were to “quit” your job, it’s not like your employer is expecting you to report for duty on Monday… or any other day for that matter.
But here’s my general advice about the word quit: only use it if you have to. I see very few use cases where we actually want to offer someone a true way to quit something. It’s so effective at conveying finality in web interfaces that it shuts the door on any future actions. For instance, I find that cancel often works in its place. And, personally, I find that saying “cancel payment” is more widely applicable. It’s softer and less rigid in the sense that it leaves the possibility to resume a process down the road.
Quit is also a simple process. Just clear everything and be gone. But if quitting means the user might lose some valuable data or progress, then that’s something they have to be warned about. In that case, exit and save may be better guidance.
I consider Exit the gentler twin of Quit. I prefer Quit just for the ultimatum of it. I see Exit used less frequently in interfaces than I see Quit. In rare cases, I might see Exit used specifically because of its softer nature to Quit even though “quitting” is the correct semantic choice given that the user really wants to wipe things clean and the assurance that nothing is left behind. Sometimes a “tougher” term is more reassuring.
Exit, however, is an excellent choice for actions that represent the end of human-to-human interactions — things like Exit Group, Exit Chat, Exit Streaming, Exit Class. If this person is kindly saying goodbye to someone or something but open to future interactions, allow them to exit when they’re done. They’re not quitting anything and we aren’t shoving them out the door.
Going Back (and Forth)
Let’s talk about navigation. That’s the way we describe moving around the internet. We navigate from one place to another, to another, to another, and so on. It’s a journey of putting one digital foot in front of the other on the way to somewhere. That journey comes to an end when we get to our destination… or when we “quit” or “exit” the journey as we discussed above.
But the journey may take twists and turns. Not all movement is linear on the web. That’s why we often leave breadcrumbs in interfaces, right? It’s wayfinding on the web and provides people with a way to go “back” where they came from. Maybe that person forgot a step and needs to head back in order to move forward again.
In other words, back displaces people — laterally and hierarchically. Laterally, back (and its synonym, previous), backtracks across the same level in a process, for instance, between two sections of the same form, or two pages of the same document. Hierarchically, back — not to mention more explicit variants like “home” — is a level above that in the navigation hierarchy.
I like the explicit nature of saying something like “Home” when it comes to navigating someone “back” to a location or state. There’s no ambiguity there: hey, let’s go back home. Being explicit opens you up to more verbose labels but brevity isn’t always the goal. Even in iconography, adding more detail to a visual can help add clarity. The same is true with content in user interfaces. My favorite example is the classic “Back to Top” button on many pages that navigate you to the “top” of the page. We’re going “back to the top” which would not have been clear if we had used “Back” alone. Back where? That’s an important question — particularly when working with in-page anchors — and the answer may not be as obvious to others as it is to you. Communicating that level of hierarchy explicitly is a navigational feature.
While the “Back to Top” example I gave is a better illustration of lateral displacement than hierarchical displacement, I tend to avoid the label back with any sort of lateral navigation because moving laterally typically involves navigating between states more than navigating between pages. For example, the user may be navigating from a “logged in” state to a “logged out” state. In this case, I prefer being even more explicit — e.g., Save and Go Back, or Cancel and Go Home — than hierarchical navigation because we’re changing states on top of moving away from something.
Closing Down
Close is yet another term you’ll find in the wild for conveying the “end” of something. It’s quite similar to Back in the sense that it serves dual purposes. It can be for navigation — close the current page and go back — or it can be for canceling an action — close the current page, and either discard or save all the data entered so far.
I prefer Close for neither of those cases. If we’re in the context of navigation, I like the clarity of the more explicit guidance we discussed above, e.g., Go Back, Previous, or Go Home. Giving someone an instruction to Close doesn’t say where that person is going to land once navigating away from the current page. And if we’re dealing with actions, Save and Close affirms the person that their data will be saved, rather than simply “closing” it out. If we were to simply say “cancel” instead, the insinuation is that the user is quitting the action and can expect to lose their work.
The one time I do feel that “Close” is the ideal label is working with pop-up dialogues and modals. Placing “Close” at the top-right (or the block-start, inline-end edge if we’re talking logical directions) corner is more than clear enough about what happens to the pop-up or modal when clicking it. We can afford to be a little less explicit with our semantics when someone’s focus is trapped in a specific context.
The End.
I’ve saved the best for last, right? There’s no better way to connote an ending than simply calling it the “end”. It works well when we pair it with what’s ending.
End Chat. End Stream. End Webinar.
You’re terminating an established connection, not with a process, but with a human. And this is not some abrupt termination like Quit or Cancel. It’s more of a proper goodbye. Consider it also a synonym to Exit because the person ending the interaction may simply be taking a break. They’re not necessarily quitting something for good. Let’s leave the light on the front patio for them to return later and pick things back up..
And speaking of end, we’ve reached the end of this article. That’s the tricky, but liberating, thing about content semantics — some words may technically be correct but still mislead site visitors. It’s not that we’re ever trying to give someone bad directions, but it can still happen because this is a world where there are many ways of saying the same thing. Our goal is to be unambiguous and the milestone is clarity. Settling on the right word or combination of words takes effort. Anyone who has struggled with naming things in code knows about this. It’s the same for naming things outside of code.
I did not make an attempt to cover each and every word or way to convey endings. The point is that our words matter and we have all the choice and freedom in the world to find the best fit. But maybe you’ve recently run into a situation where you needed to “end” something and communicate that in an interface. Did you rely on something definitive and permanent (e.g. quit) or did you find that softer language (e.g. exit) was the better direction? What other synonyms did you consider? I’d love to know!
Finally! After so many years, we’re very happy to launch “How To Measure UX and Design Impact”, our new practical guide for designers and managers on how to set up and track design success in your company — with UX scorecards, UX metrics, the entire workflow and Design KPI trees. Neatly put together by yours truly, Vitaly Friedman. Jump to details.
In many companies, designers are perceived as disruptors, rather than enablers. Designers challenge established ways of working. They ask a lot of questions — much needed ones but also uncomfortable ones. They focus “too much” on user needs, pushing revenue projections back, often with long-winded commitment to testing and research and planning and scoping.
Almost every department in almost every company has their own clearly defined objectives, metrics and KPIs. In fact, most departments — from finance to marketing to HR to sales — are remarkably good at visualizing their impact and making it visible throughout the entire organization.
Designing a KPI tree, an example of how to connect business objectives with design initiatives through the lens of design KPIs. (Large preview)
But as designers, we rarely have a set of established Design KPIs that we regularly report to senior management. We don’t have a clear definition of design success. And we rarely measure the impact of our work once it’s launched. So it’s not surprising that moste parts of the business barely know what we actually do all day long.
Business wants results. It also wants to do more of what has worked in the past. But it doesn’t want to be disrupted — it wants to disrupt. It wants to reduce time to market and minimize expenses; increase revenue and existing business, find new markets. This requires fast delivery and good execution.
And that’s what we are often supposed to be — good “executors”. Or to put differently, “pixel pushers”.
Over years, I’ve been searching for a way to change that. This brought me to Design KPIs and UX scorecards, and a workflow to translate business goals into actionable and measurable design initiatives. I had to find a way to explain, visualize and track that incredible impact that designers have on all parts of business — from revenue to loyalty to support to delivery.
The results of that journey are now public in our new video course: “How To Measure UX and Design Impact” — a practical guide for designers, researchers and UX leads to measure and visualize UX impact on business.
About The Course
The course dives deep into establishing team-specific design KPIs, how to track them effectively, how to set up ownership and integrate metrics in design process. You’ll discover how to translate ambiguous objectives into practical design goals, and how to measure design systems and UX research.
Also, we’ll make sense of OKRs, Top Task Analysis, SUS, UMUX-Lite, UEQ, TPI, KPI trees, feedback scoring, gap analysis, and Kano model — and what UX research methods to choose to get better results. Jump to the table of contents or get your early-bird.
The setup for the video recordings. Once all content is in place, it’s about time to set up the recording.
<a class="btn btn--large btn--green btn--text-shadow" href=https://measure-ux.com>Jump to the video course →
A practical guide to UX metrics and Design KPIs
8h-video course + live UX training. Free preview.
25 chapters (8h), with videos added/updated yearly
Free preview, examples, templates, workflows
No subscription: get once, access forever
Life-time access to all videos, slides, checklists.
25 chapters, 8 hours, with practical examples, exercises, and everything you need to master the art of measuring UX and design impact. Don’t worry, even if it might seem overwhelming at first, we’ll explore things slowly and thoroughly. Taking 1–2 sessions per week is a perfectly good goal to aim for.
We can’t improve without measuring. That’s why our new video course gives you the tools you need to make sense of it all: user needs, just like business needs. (View large version)
1. Welcome
+
So, how do we measure UX? Well, let’s find out! Meet a friendly welcome message to the video course, outlining all the fine details we’ll be going through: design impact, business metrics, design metrics, surveys, target times and states, measuring UX in B2B and enterprises, design KPI trees, Kano model, event storming, choosing metrics, reporting design success — and how to measure design systems and UX research efforts.
In this segment, we’ll explore how and where we, as UX designers, make an impact within organizations. We’ll explore where we fit in the company structure, how to build strong relationships with colleagues, and how to communicate design value in business terms.
Keywords:
Design impact, design ROI, orgcharts, stakeholder engagement, business language vs. UX language, Double Diamond vs. Reverse Double Diamond, risk mitigation.
3. OKRs and Business Metrics
+
We’ll explore the key business terms and concepts related to measuring business performance. We’ll dive into business strategy and tactics, and unpack the components of OKRs (Objectives and Key Results), KPIs, SMART goals, and metrics.
Businesses often speak of leading and lagging indicators — predictive and retrospective measures of success. Let’s explore what they are and how they are different — and how we can use them to understand the immediate and long-term impact of our UX work.
Keywords:
Leading vs. lagging indicators, cause-and-effect relationship, backwards-looking and forward-looking indicators, signals for future success.
5. Business Metrics, NPS
+
We dive into the world of business metrics, from Monthly Active Users (MAU) to Monthly Recurring Revenue (MRR) to Customer Lifetime Value (CLV), and many other metrics that often find their way to dashboards of senior management.
Also, almost every business measures NPS. Yet NPS has many limitations, requires a large sample size to be statistically reliable, and what people say and what people do are often very different things. Let’s see what we as designers can do with NPS, and how it relates to our UX work.
Keywords:
Business metrics, MAU, MRR, ARR, CLV, ACV, Net Promoter Score, customer loyalty.
6. Business Metrics, CSAT, CES
+
We’ll explore the broader context of business metrics, including revenue-related measures like Monthly Recurring Revenue (MRR) and Annual Recurring Revenue (ARR), Customer Lifetime Value (CLV), and churn rate.
We’ll also dive into Customer Satisfaction Score (CSAT) and Customer Effort Score (CES). We’ll discuss how these metrics are calculated, their importance in measuring customer experience, and how they complement other well-known (but not necessarily helpful) business metrics like NPS.
If you are looking for a simple alternative to NPS, feedback scoring and gap analysis might be a neat little helper. It transforms qualitative user feedback into quantifiable data, allowing us to track UX improvements over time. Unlike NPS, which focuses on future behavior, feedback scoring looks at past actions and current perceptions.
Keywords:
Feedback scoring, gap analysis, qualitative feedback, quantitative data.
8. Design Metrics (TPI, SUS, SUPR-Q)
+
We’ll explore the landscape of established and reliable design metrics for tracking and capturing UX in digital products. From task success rate and time on task to System Usability Scale (SUS) to Standardized User Experience Percentile Rank Questionnaire (SUPR-Q) to Accessible Usability Scale (AUS), with an overview of when and how to use each, the drawbacks, and things to keep in mind.
Keywords:
UX metrics, KPIs, task success rate, time on task, error rates, error recovery, SUS, SUPR-Q.
9. Design Metrics (UMUX-Lite, SEQ, UEQ)
+
We’ll continue with slightly shorter alternatives to SUS and SUPR-Q that could be used in a quick email survey or an in-app prompt — UMUX-Lite and Single Ease Question (SEQ). We’ll also explore the “big behemoths” of UX measurements — User Experience Questionnaire (UEQ), Google’s HEART framework, and custom UX measurement surveys — and how to bring key metrics together in one simple UX scorecard tailored to your product’s unique needs.
Keywords:
UX metrics, UMUX-Lite, Single Ease Question (SEQ), User Experience Questionnaire (UEQ), HEART framework, UEQ, UX scorecards.
10. Top Tasks Analysis
+
The most impactful way to measure UX is to study how successful users are in completing their tasks in their common customer journeys. With top tasks analysis, we focus on what matters, and explore task success rates and time on task. We need to identify representative tasks and bring 15–18 users in for testing. Let’s dive into how it all works and some of the important gotchas and takeaways to consider.
Keywords:
Top task analysis, UX metrics, task success rate, time on task, qualitative testing, 80% success, statistical reliability, baseline testing.
11. Surveys and Sample Sizes
+
Designing good surveys is hard! We need to be careful on how we shape our questions to avoid biases, how to find the right segment of audience and large enough sample size, how to provide high confidence levels and low margins of errors. In this chapter, we review best practices and a cheat sheet for better survey design — along with do’s and don’ts on question types, rating scales, and survey pre-testing.
Keywords:
Survey design, question types, rating scales, survey length, pre-testing, response rates, statistical significance, sample quality, mean vs. median scores.
12. Measuring UX in B2B and Enterprise
+
Best measurements come from testing with actual users. But what if you don’t have access to any users? Perhaps because of NDA, IP concerns, lack of clearance, poor availability, and high costs of customers and just lack of users? Let’s explore how we can find a way around such restrictive environments, how to engage with stakeholders, and how we can measure efficiency, failures — and set up UX KPI programs.
To visualize design impact, we need to connect high-level business objectives with specific design initiatives. To do that, we can build up and present Design KPI trees. From the bottom up, the tree captures user needs, pain points, and insights from research, which inform design initiatives. For each, we define UX metrics to track the impact of these initiatives, and they roll up to higher-level design and business KPIs. Let’s explore how it all works in action and how you can use it in your work.
Keywords:
User needs, UX metrics, KPI trees, sub-trees, design initiatives, setting up metrics, measuring and reporting design impact, design workflow, UX metrics graphs, UX planes.
14. Event Storming
+
How do we choose the right metrics? Well, we don’t start with metrics. We start by identifying most critical user needs and assess the impact of meeting user needs well. To do that, we apply event storming by mapping critical user’s success moments as they interact with a digital product. Our job, then, is to maximize success, remove frustrations, and pave a clear path towards a successful outcome — with event storming.
Keywords:
UX mapping, customer journey maps, service blueprints, event storming, stakeholder alignment, collaborative mapping, UX lanes, critical events, user needs vs. business goals.
15. Kano Model and Survey
+
Once we have a business objective in front of us, we need to choose design initiatives that are most likely to drive the impact that we need to enable with our UX work. To test how effective our design ideas are, we can map them against a Kano model und run a concept testing survey. It gives us a user’s sentiment that we then need to weigh against business priorities. Let’s see how to do just that.
How do we design a KPI tree from scratch? We start by running a collaborative event storming to identify key success moments. Then we prioritize key events and explore how we can amplify and streamline them. Then we ideate and come up with design initiatives. These initiatives are stress tested in an impact-effort matrix for viability and impact. Eventually, we define and assign metrics and KPIs, and pull them together in a KPI tree. Here’s how it works from start till the end.
Keywords:
Uncovering user needs, impact-effort matrix, concept testing, event storming, stakeholder collaboration, traversing the KPI tree.
17. Choosing The Right Metrics
+
Should we rely on established UX metrics such as SUS, UMUX-Lite, and SUPR-Q, or should we define custom metrics tailored to product and user needs? We need to find a balance between the two. It depends on what we want to measure, what we actually can measure, and whether we want to track local impact for a specific change or global impact for the entire customer journey. Let’s figure out how to define and establish metrics that actually will help us track our UX success.
Keywords:
Local vs. global KPIs, time spans, percentage vs. absolute values, A/B testing, mapping between metrics and KPIs, task breakdown, UX lanes, naming design KPIs.
18. Design KPIs Examples
+
Different contexts will require different design KPIs. In this chapter, we explore a diverse set of UX metrics related to search quality (quality of search for top 100 search queries), form design (error frequency, accuracy), e-commerce (time to final price), subscription-based services (time to tier boundaries), customer support (service desk inquiries) and many others. This should give you a good starting point to build upon for your own product and user needs.
Keywords:
Time to first success, search results quality, form error recovery, password recovery rate, accessibility coverage, time to tier boundaries, service desk inquiries, fake email frequency, early drop-off rate, carbon emissions per page view, presets and templates usage, default settings adoption, design system health.
19. UX Strategy
+
Establishing UX metrics doesn’t happen over night. You need to discuss and decide what you want to measure and how often it should happen. But also how to integrate metrics, evaluate data, and report findings. And how to embed them into an existing design workflow. For that, you will need time — and green lights from your stakeholders and managers. To achieve that, we need to tap into the uncharted waters of UX strategy. Let’s see what it involves for us and how to make progress there.
Once you’ve established UX metrics, you will need to report them repeatedly to the senior management. How exactly would you do that? In this chapter, we explore the process of selecting representative tasks, recruiting participants, facilitating testing sessions, and analyzing the resulting data to create a compelling report and presentation that will highlight the value of your UX efforts to stakeholders.
Keywords:
Data analysis, reporting, facilitation, observation notes, video clips, guidelines and recommendations, definition of design success, targets, alignment, and stakeholder’s buy-in.
21. Target Times and States
+
To show the impact of our design work, we need to track UX snapshots. Basically, it’s four states, mapped against touch points in a customer journey: baseline (threshold not to cross), current state (how we are currently doing), target state (objective we are aiming for), and industry benchmark (to stay competitive). Let’s see how it would work in an actual project.
Keywords:
Competitive benchmarking, baseline measurement, local and global design KPIs, cross-teams metrics, setting realistic goals.
22. Measuring Design Systems
+
How do we measure the health of a design system? Surely it’s not just a roll-out speed for newly designed UI components or flows. Most teams track productivity and coverage, but we can also go beyond that by measuring relative adoption, efficiency gains (time saved, faster time-to-market, satisfaction score, and product quality). But the best metric is how early designers involve the design system in a conversation during their design work.
Keywords:
Component coverage, decision trees, adoption, efficiency, time to market, user satisfaction, usage analytics, design system ROI, relative adoption.
23. Measuring UX Research
+
Research insights often end up gaining dust in PDF reports stored on remote fringes of Sharepoint. To track the impact of UX research, we need to track outcomes and research-specific metrics. The way to do that is to track UX research impact for UX and business, through organisational learning and engagement, through make-up of research efforts and their reach. And most importantly: amplifying research where we expect the most significant impact. Let’s see what it involves.
Keywords:
Outcome metrics, organizational influence, research-specific metrics, research references, study observers, research formalization, tracking research-initiated product changes.
24. Getting Started
+
So you’ve made it so far! Now, how do you get your UX metrics initiative off the ground? By following small steps heading in the right direction. Small commitments, pilot projects, and design guilds will support and enable your efforts. We just need to define realistic goals and turn UX metrics in a culture of measurement, or simply a way of working. Let’s see how we can do just that.
Keywords:
Pilot projects, UX integration, resource assessment, evidence-driven design, establishing a baseline, culture of measurement.
25. Next Steps
+
Let’s wrap up our journey into UX metrics and Design KPIs and reflect what we have learned. What remains is the first next step: and that would be starting where you are and growing incrementally, by continuously visualizing and explaining your UX impact — however limited it might be — to your stakeholders. This is the last chapter of the course, but the first chapter of your incredible journey that’s ahead of you.
Keywords:
Stakeholder engagement, incremental growth, risk mitigation, user satisfaction, business success.
Who Is The Course For?
This course is tailored for advanced UX practitioners, design leaders, product managers, and UX researchers who are looking for a practical guide to define, establish and track design KPIs, translate business goals into actionable design tasks, and connect business needs with user needs.
What You’ll Learn
By the end of the video course, you’ll have a packed toolbox of practical techniques and strategies on how to define, establish, sell, and measure design KPIs from start to finish — and how to make sure that your design work is always on the right trajectory. You’ll learn:
How to translate business goals to UX initiatives,
The difference between OKRs, KPIs, and metrics,
How to define design success for your company,
Metrics and KPIs that businesses typically measure,
How to choose the right set of metrics and KPIs,
How to establish design KPIs focused on user needs,
How to build a comprehensive design KPI tree,
How to combine qualitative and quantitative insights,
How to choose and prioritize design work,
How to track the impact of design work on business goals,
How to explain, visualize, and defend design work,
How companies define and track design KPIs,
How to make a strong case for UX metrics.
Community Matters ❤️
Producing a video course takes quite a bit of time, and we couldn’t pull it off without the support of our wonderful community. So thank you from the bottom of our hearts! We hope you’ll find the course useful for your work. Happy watching, everyone! 🎉🥳
CSS gradients have been so long that there’s no need to rehash what they are and how to use them. You have surely encountered them at some point in your front-end journey, and if you follow me, you also know that I use them all the time. I use them for CSS patterns, nice CSS decorations, and even CSS loaders. But even so, gradients have a tough syntax that can get very complicated very quickly if you’re not paying attention.
In this article, we are not going to make complex stuff with CSS gradients. Instead, we’re keeping things simple and I am going to walk through all of the incredible things we can do with just one gradient.
Only one gradient? In this case, reading the doc should be enough, no?
No, not really. Follow along and you will see that gradients are easy at their most basic, but are super powerful if we push them — or in this case, just one — to their limits.
CSS patterns
One of the first things you learn with gradients is that we can establish repeatable patterns with them. You’ve probably seen some examples of checkerboard patterns in the wild. That’s something we can quickly pull off with a single CSS gradient. In this case, we can reach for the repeating-conic-gradient() function:
Pretty simple so far, right? You have two colors that you can easily swap out for other colors, plus the background-size property to control the square shapes.
If we change the color stops — where one color stops and another starts — we get another cool pattern based on triangles:
If you compare the CSS for the two demos we’ve seen so far, you’ll see that all I did was divide the color stops in half, 25% to 12.5% and 50% to 25%.
Another one? Let’s go!
This time I’m working with CSS variables. I like this because variables make it infinitely easier to configure the gradients by updating a few values without actually touching the syntax. The calculation is a little more complex this time around, as it relies on trigonometric functions to get accurate values.
I know what you are thinking: Trigonometry? That sounds hard. That is certainly true, particularly if you’re new to CSS gradients. A good way to visualize the pattern is to disable the repetition using the no-repeat value. This isolates the pattern to one instance so that you clearly see what’s getting repeated. The following example declares background-image without a background-size so you can see the tile that repeats and better understand each gradient:
I want to avoid a step-by-step tutorial for each and every example we’re covering so that I can share lots more examples without getting lost in the weeds. Instead, I’ll point you to three articles you can refer to that get into those weeds and allow you to pick apart our examples.
I’ll also encourage you to open my online collection of patterns for even more examples. Most of the examples are made with multiple gradients, but there are plenty that use only one. The goal of this article is to learn a few “single gradient” tricks — but the ultimate goal is to be able to combine as many gradients as possible to create cool stuff!
Grid lines
Let’s start with the following example:
You might claim that this belongs under “Patterns” — and you are right! But let’s make it more flexible by adding variables for controlling the thickness and the total number of cells. In other words, let’s create a grid!
.grid-lines {
--n: 3; /* number of rows */
--m: 5; /* number of columns */
--s: 80px; /* control the size of the grid */
--t: 2px; /* the thickness */
width: calc(var(--m)*var(--s) + var(--t));
height: calc(var(--n)*var(--s) + var(--t));
background:
conic-gradient(from 90deg at var(--t) var(--t), #0000 25%, #000 0)
0 0/var(--s) var(--s);
}
First of all, let’s isolate the gradient to better understand the repetition (like we did in the previous section).
One repetition will give us a horizontal and a vertical line. The size of the gradient is controlled by the variable --s, so we define the width and height as a multiplier to get as many lines as we want to establish the grid pattern.
What’s with “+ var(--t)” in the equation?
The grid winds up like this without it:
We are missing lines at the right and the bottom which is logical considering the gradient we are using. To fix this, the gradient needs to be repeated one more time, but not at full size. For this reason, we are adding the thickness to the equation to have enough space for the extra repetition and the get the missing lines.
And what about a responsive configuration where the number of columns depends on the available space? We remove the --m variable and define the width like this:
Instead of multiplying things, we use the round() function to tell the browser to make the element full width and round the value to be a multiple of --s. In other words, the browser will find the multiplier for us!
Resize the below and see how the grid behaves:
In the future, we will also be able to do this with the calc-size() function:
Using calc-size() is essentially the same as the last example, but instead of using 100% we consider auto to be the width value. It’s still early to adopt such syntax. You can test the result in the latest version of Chrome at the time of this writing:
Dashed lines
Let’s try something different: vertical (or horizontal) dashed lines where we can control everything.
.dashed-lines {
--t: 2px; /* thickness of the lines */
--g: 50px; /* gap between lines */
--s: 12px; /* size of the dashes */
background:
conic-gradient(at var(--t) 50%, #0000 75%, #000 0)
var(--g)/calc(var(--g) + var(--t)) var(--s);
}
Can you figure out how it works? Here is a figure with hints:
Try creating the horizontal version on your own. Here’s a demo that shows how I tackled it, but give it a try before peeking at it.
What about a grid with dashed lines — is that possible?
Yes, but using two gradients instead of one. The code is published over at my collection of CSS shapes. And yes, the responsive behavior is there as well!
Rainbow gradient
How would you create the following gradient in CSS?
You might start by picking as many color values along the rainbow as you can, then chaining them in a linear-gradient:
linear-gradient(90deg, red, yellow, green, /* etc. */, red);
Good idea, but it won’t get you all the way there. Plus, it requires you to juggle color stops and fuss with them until you get things just right.
There is a simpler solution. We can accomplish this with just one color!
background: linear-gradient(90deg in hsl longer hue, red 0 0);
I know, the syntax looks strange if you’re seeing the new color interpolation for the first time.
If I only declare this:
background: linear-gradient(90deg, red, red); /* or (90deg, red 0 0) */
…the browser creates a gradient that goes from red to red… red everywhere! When we set this “in hsl“, we’re changing the color space used for the interpolation between the colors:
background: linear-gradient(90deg in hsl, red, red);
Now, the browser will create a gradient that goes from red to red… this time using the HSL color space rather than the default RGB color space. Nothing changes visually… still see red everywhere.
The longer hue bit is what’s interesting. When we’re in the HSL color space, the hue channel’s value is an angle unit (e.g., 25deg). You can see the HSL color space as a circle where the angle defines the position of the color within that circle.
Since it’s a circle, we can move between two points using a “short” path or “long” path.
If we consider the same point (red in our case) it means that the “short” path contains only red and the “long” path runs into all the colors as it traverses the color space.
Adam Argyle published a very detailed guide on high-definition colors in CSS. I recommend reading it because you will find all the features we’re covering (this section in particular) to get more context on how everything comes together.
We can use the same technique to create a color wheel using a conic-gradient:
And while we are on the topic of CSS colors, I shared another fun trick that allows you to define an array of color values… yes, in CSS! And it only uses a single gradient as well.
Hover effects
Let’s do another exercise, this time working with hover effects. We tend to rely on pseudo-elements and extra elements when it comes to things like applying underlines and overlays on hover, and we tend to forget that gradients are equally, if not more, effective for getting the job done.
Case in point. Let’s use a single gradient to form an underline that slides on hover:
You likely would have used a pseudo-element for this, right? I think that’s probably how most people would approach it. It’s a viable solution but I find that using a gradient instead results in cleaner, more concise CSS.
Creating shapes with gradients is my favorite thing to do in CSS. I’ve been doing it for what feels like forever and love it so much that I published a “Modern Guide for Making CSS Shapes” over at Smashing Magazine earlier this year. I hope you check it out not only to learn more tricks but to see just how many shapes we can create with such a small amount of code — many that rely only on a single CSS gradient.
Some of my favorites include zig-zag borders:
…and “scooped” corners:
…as well as sparkles:
…and common icons like the plus sign:
I won’t get into the details of creating these shapes to avoid making this article long and boring. Read the guide and visit my CSS Shape collection and you’ll have everything you need to make these, and more!
Border image tricks
Let’s do one more before we put a cap on this. Earlier this year, I discovered how awesome the CSS border-image property is for creating different kinds of decorations and shapes. And guess what? border-image limits us to using just one gradient, so we are obliged to follow that restriction.
Again, just one gradient and we get a bunch of fun results. I’ll drop in my favorites like I did in the last section. Starting with a gradient overlay:
We can use this technique for a full-width background:
…as well as heading dividers:
…and even ribbons:
All of these have traditionally required hacks, magic numbers, and other workarounds. It’s awesome to see modern CSS making things more effortless. Go read my article on this topic to find all the interesting stuff you can make using border-image.
Wrapping up
I hope you enjoyed this collection of “single-gradient” tricks. Most folks I know tend to use gradients to create, well, gradients. But as we’ve seen, they are more powerful and can be used for lots of other things, like drawing shapes.
I like to add a reminder at the end of an article like this that the goal is not to restrict yourself to using one gradient. You can use more! The goal is to get a better handle on how gradients work and push them in interesting ways — that, in turn, makes us better at writing CSS. So, go forth and experiment — I’d love to see what you make!
In this third and final part of a three-part series, we’re taking a more streamlined approach to an application that supports vision-language (VLM) and text-to-speech (TTS). This time, we’ll use different models that are designed for all three modalities — images or videos, text, and audio( including speech-to-text) — in one model. These “any-to-any” models make things easier by allowing us to avoid switching between models.
Specifically, we’ll focus on two powerful models: Reka and Gemini 1.5 Pro.
Both models take things to the next level compared to the tools we used earlier. They eliminate the need for separate speech recognition models, providing a unified solution for multimodal tasks. With this in mind, our goal in this article is to explore how Reka and Gemini simplify building advanced applications that handle images, text, and audio all at once.
Overview Of Multimodal AI Models
The architecture of multimodal models has evolved to enable seamless handling of various inputs, including text, images, and audio, among others. Traditional models often require separate components for each modality, but recent advancements in “any-to-any” models like Next-GPT or 4M allow developers to build systems that process multiple modalities within a unified architecture.
Gato, for instance, utilizes a 1.2 billion parameter decoder-only transformer architecture with 24 layers, embedding sizes of 2048 and a hidden size of 8196 in its feed-forward layers. This structure is optimized for general tasks across various inputs, but it still relies on extensive task-specific fine-tuning.
GPT-4o, on the other hand, takes a different approach with training on multiple media types within a single architecture. This means it’s a single model trained to handle a variety of inputs (e.g., text, images, code) without the need for separate systems for each. This training method allows for smoother task-switching and better generalization across tasks.
Similarly, CoDi employs a multistage training scheme to handle a linear number of tasks while supporting input-output combinations across different modalities. CoDi’s architecture builds a shared multimodal space, enabling synchronized generation for intertwined modalities like video and audio, making it ideal for more dynamic multimedia tasks.
Most “any-to-any” models, including the ones we’ve discussed, rely on a few key concepts to handle different tasks and inputs smoothly:
Shared representation space
These models convert different types of inputs — text, images, audio — into a common feature space. Text is encoded into vectors, images into feature maps, and audio into spectrograms or embeddings. This shared space allows the model to process various inputs in a unified way.
Attention mechanisms
Attention layers help the model focus on the most relevant parts of each input, whether it’s understanding the text, generating captions from images, or interpreting audio.
Cross-modal interaction
In many models, inputs from one modality (e.g., text) can guide the generation or interpretation of another modality (e.g., images), allowing for more integrated and cohesive outputs.
Pre-training and fine-tuning
Models are typically pre-trained on large datasets across different types of data and then fine-tuned for specific tasks, enhancing their performance in real-world applications.
Reka Models
Reka is an AI research company that helps developers build powerful applications by offering models for a range of tasks. These tasks include generating text from videos and images, translating speech, and answering complex questions from long multimodal documents. Reka’s models can even write and execute code, providing flexible, real-world solutions for developers.
These are the three main models Reka offers:
Reka Core
A 67-billion-parameter multimodal language model designed for complex tasks. It supports inputs like images, videos, and texts while excelling in advanced reasoning and coding.
Reka Flash
A faster model with a 21-billion-parameter, designed for flexibility and rapid performance in multimodal settings.
Reka Edge (PDF)
A smaller 7-billion-parameter model was built for on-device and low-latency applications, making it efficient for local use and local or latency-sensitive applications.
Reka’s models can be fine-tuned and deployed securely, whether on the cloud, on-premises, or even on-device. Let’s start by testing Reka’s capabilities directly through its playground. This allows us to experiment with its multimodal features without writing any code, providing a hands-on way to see how the models handle various tasks, such as image and video comprehension.
Alright, we’ll kick things off by uploading an image of a diagram outline of the PaliGemma architecture and ask Reka for a detailed explanation.
Can you provide a more detailed explanation of this image?
Here’s what we get from Reka Core:
“This image is a schematic representation of a machine-learning model named PaliGemma. The model appears to be designed for multimodal input, combining both image and text data. At the top, there are two input sources: ‘Image Input’ and ‘Text Input’. The image input is processed by a ‘SigLIP Image Encoder’, which likely stands for a specific type of image encoding technique. The output of this encoder is then subjected to a ‘Linear Projection’, which is a common step in machine learning to transform data into a lower-dimensional space. The text input is directly fed into the model. Both the projected image data and the text input are then concatenated into ‘Concatenated Tokens’, which are then processed by a component labeled ‘Gemma’. The final output of the model is ‘Text Output’, which suggests that the model is designed to generate text based on the input data.”
It’s a clear and detailed breakdown of the PaliGemma architecture. The model accurately identifies image and text inputs, the SigLIP image encoder, and the linear projection step. It also grasps how the image and text inputs are combined and processed to generate text output. I should admit that the response is quite neat, offering a solid explanation of the architecture.
Let’s try a video input instead. We’ll upload the video about Genny, a software, and ask a question to see how well Reka Core handles video comprehension.
What is this video about?
“This video is a screen recording of a group of friends discussing their plans for the weekend.”
Well, it’s not a good answer compared to what LLaVA gave us in the previous article. Now let’s try a longer video, but with the Reka Flash model. The video is about a TTS model called Parler TTS. Instead of asking what the video is about, let’s prompt it like this:
I’m an AI developer, and I’m not sure how this TTS model can help me in my projects. Can you explain how I can use it or what it’s useful for?
Reka Flash generates a solid answer this time:
“Of course! This TTS (Text-to-Speech) model can be incredibly useful for developers, especially those working on projects that involve creating more human-like interactions or providing audio feedback to users. Here are some ways you can leverage this TTS model in your projects:
Accessibility: TTS models can greatly enhance the accessibility of your applications for users with visual impairments or reading difficulties. By providing spoken feedback or narrating content, you can make your applications more inclusive
Voice Assistants: You can integrate this TTS model into voice assistants or chatbots, allowing them to generate more natural-sounding responses. This can improve user experience and make interactions with your bots more engaging.
Multimedia Applications: This TTS model can be used in multimedia applications, such as e-books, educational tools, or games, to provide spoken narration or instructions. This can make the content more engaging and easier to understand.
Audio Notifications: You can use the TTS model to generate audio notifications for your applications, providing users with spoken alerts or reminders. This can be particularly useful for users who may not always have their screens visible.
Language Learning: The TTS model can be used in language learning applications to provide users with correct pronunciation and intonation. It can also generate spoken feedback or narrate lessons, making the learning process more immersive.
Audio Books: You can use the TTS model to generate audio books, allowing users to listen to written content instead of reading it. This can be especially helpful for users who prefer auditory learning or have difficulty reading.
Explainer Videos: The TTS model can be used to generate voiceovers for explainer videos, providing users with spoken narration that explains the content on the screen. This can make the content more engaging and easier to understand.
Audio Feedback: You can use the TTS model to generate audio feedback for users in your applications, such as confirming actions, providing instructions, or giving feedback on their performance. This can make the interactions more natural and intuitive.
In summary, the TTS model can be a valuable tool for developers looking to create more human-like interactions, improve accessibility, and enhance the user experience in various applications.”
It’s a good answer that’s informative and quite practical for developers. Let’s compare what happens when we try the Reka Edge model with a PDF input titled “Meta AI — Responsible Use Guide” (PDF).
As an AI developer, how can I ensure that I am following the responsible AI guidelines outlined in this document?
“To ensure that your use of AI aligns with the principles outlined in this guide, you can follow these steps and best practices:
Familiarize yourself with the principles of responsible AI, such as transparency, accountability, and user empowerment, as outlined in the guide.
Understand the potential impacts of AI on users and society, and be aware of the risks and challenges associated with the development and deployment of AI systems.
Embrace an iterative model-development mindset, continuously striving for improvement and learning from feedback and errors.
Build a responsible AI ecosystem by working with partners, experts, and communities to develop and share best practices, tools, and benchmarking resources.
Follow the guidelines and best practices outlined in the guide for each stage of model development, from data collection and preparation to fine-tuning, evaluation, and deployment.
Consider the specific use case and requirements for your AI system, and tailor your approach accordingly.
Regularly monitor and evaluate the performance and safety of your AI system and make adjustments as needed to ensure it aligns with the principles outlined in the guide.
Be transparent and accountable in your interactions with users and stakeholders, and be open to feedback and suggestions for improvement.
Stay informed about the latest developments and research in the field of AI, and be prepared to adapt your approach as needed to address new challenges and opportunities.
Follow the specific guidelines and best practices outlined in the addendum for Code Llama, such as defining content policies, evaluating and benchmarking models, and addressing input- and output-level risks.”
Reka Edge’s answer is quite thorough and detailed, too!
If you want to dive into coding, start by creating a Reka account and getting an API key. Then you can follow along with this notebook. Try out their Python SDK, and make sure to explore the different models available. It’s a great way to see how these tools work under the hood!
Gemini Models
Gemini 1.5, developed by Google DeepMind, is designed to handle complex tasks efficiently, thanks to the new Mixture-of-Experts (MoE) system. MoE is like packing several specialized models inside one big model. Instead of using the whole network for every task, Gemini 1.5 activates only the parts (or what they call “experts”) that are most relevant. This means Gemini 1.5 can tackle complex tasks with less processing power than a typical monolithic model.
We can explore Gemini’s features in Google AI Studio since it’s already baked right in. We’ll begin by uploading the following image illustrating VLM capabilities.
We’ll ask Gemini to analyze the image and extract details or concepts:
Explain this image. What are the specific details or concepts it represents?
“The image is a flowchart illustrating different types of image understanding tasks with a Vision Language Model.
Object Localization: This task aims to identify the precise location of objects within an image. The example question asks, “Is one cat behind another?”
Zero-shot Segmentation: This task involves segmenting an image into different regions based on a given label, even if the model has never seen that specific label before. The example question asks to segment “striped cat.”
Zero-shot Visual QA: This task requires answering questions about an image, even if the model has not been specifically trained to answer that type of question. The example question asks, “What is the breed of these cats?”
One-shot Learning with Instructions: This task involves providing the model with a single example and instruction to learn a new concept and apply it to other images. The example question asks, “Striped cats are called tabby cats. What is the breed of the cats in the image?”
Well, Gemini nailed it — it clearly understood the image and recognized the tasks a VLM handles. This is exactly what you’d expect from a model designed for advanced image analysis.
Now, we’ll upload another image — this time of an Italian dish — and ask Gemini if it can recognize the dishes and list the ingredients needed for them. This type of “food recognition task” will help us test its ability to identify foods and ingredients.
List the different dishes in this image, also from which country, and give me the ingredients I need to make them.
“The image shows an Italian feast with the following dishes:
Seafood Stew: A rich and flavorful stew with seafood like clams, mussels, shrimp, fish, and vegetables in a tomato broth.
Spaghetti with Tomato Sauce: Classic spaghetti pasta tossed in a simple yet flavorful tomato sauce.
Meatballs in Tomato Sauce: Tender and juicy meatballs simmered in a rich tomato sauce.
Lasagna: Layered pasta with meat sauce, cheese, and tomato sauce.
Side Salad: A refreshing side salad with mixed greens, tomatoes, and other vegetables.
Garlic Bread: Toasted bread slices rubbed with garlic and olive oil.
Marinara Sauce: A simple tomato-based sauce.
This is a typical Italian meal with various dishes showcasing the flavors of Italian cuisine.
As for the ingredients, you’ll need tomatoes for many of these dishes, specifically for the sauces and the side salad.”
Well, the model did a good job recognizing the dishes, but it also didn’t give me all the necessary ingredients. Let’s see how it does with videos instead, using the same video we used earlier with the Reka models. This time, the task will focus on action recognition.
What is the purpose of this video, and what key actions or processes are being demonstrated?
“The video is a tutorial about the importance of friendship and how it can impact our lives. It demonstrates the use of a video editing software called “Genmy” to create a video and add text subtitles. The video creator is using Genmy to:
Record their voice: This is seen at the top of the screen with the mic icon.
Add text to speech: You see the “Text to Speech” option, which is likely being used to generate subtitles or captions for the video.
Edit the timeline: They’re working with a video timeline, adding and arranging different elements.
Add voice-over: The speaker is adding commentary to the video.
Create a visually appealing presentation: They’re using a combination of video footage, text, and voice-over to create an engaging tutorial.”
Well, Gemini gave a clear breakdown of the video, identifying it as a tutorial demonstrating the Genmy video editing software to highlight how it’s used for recording voice, adding text-to-speech, editing video timelines, and allowing voice-over. Impressive!
Let’s upload one more video, the same one we used for Reka about the Parler TTS model, and ask Gemini to analyze and summarize the contents.
Summarize this video and explain how the contents might be relevant or helpful for software engineers.
“This video showcases different voice samples generated by a text-to-speech (TTS) system called “Parler-TTS.” The video highlights various voice characteristics like gender, pace, pitch, and even the simulated environment. For software engineers, this video demonstrates the progress made in TTS technology. These are some insights:
Voice Variety: The video shows that Parler-TTS can create diverse voices, potentially useful for applications needing different personas or tones.
Fine-grained Control: The video emphasizes the ability to control voice parameters like pace and pitch, showcasing the potential for customizability.
Quality and Naturalness: The video focuses on the quality of the generated speech, demonstrating the advancements made in speech synthesis, which is crucial for user experience.”
Nicely done! I can go with that answer. Gemini explains adjusting voice settings, like pitch and speed, and how having different voices can be useful. Gemini also emphasizes the importance of natural, high-quality speech, which is handy for developers working with TTS systems!
Alright, for coding, you can grab the code from Google AI Studio by clicking the Get Code button. You can choose between formatting the code in Python, Swift, and Java, among other languages.
Conclusion
Both Reka and Gemini are strong multimodal models for AI applications, but there are key differences between them to consider. Here’s a table that breaks those down:
Feature
Reka
Gemini 1.5
Multimodal Capabilities
Image, video, and text processing
Image, video, text, with extended token context
Efficiency
Optimized for multimodal tasks
Built with MoE for efficiency
Context Window
Standard token window
Up to two million tokens (with Flash variant)
Architecture
Focused on multimodal task flow
MoE improves specialization
Training/Serving
High performance with efficient model switching
More efficient training with MoE architecture
Deployment
Supports on-device deployment
Primarily cloud-based, with Vertex AI integration
Use Cases
Interactive apps, edge deployment
Suited for large-scale, long-context applications
Languages Supported
Multiple languages
Supports many languages with long context windows
Reka stands out for on-device deployment, which is super useful for apps requiring offline capabilities or low-latency processing.
On the other hand, Gemini 1.5 Pro shines with its long context windows, making it a great option for handling large documents or complex queries in the cloud.
Gain $200 in a week
from Articles on Smashing Magazine — For Web Designers And Developers https://ift.tt/jVtfH01