

Open-source LLMS, owing to their comparable performance with advanced proprietary LLMs, have been gaining immense popularity lately. Open-source LLMs are free to use, and you can easily modify their source code or fine-tune them on your systems.
Alibaba's Qwen and Meta's Llama series of models are two major players in the open source LLM arena. In this article, we will compare the performance of Qwen 2.5-72b and Llama 3.1-70b models for zero-shot text classification and summarization.
By the end of this article, you will have a rough idea of which model to use for your NLP tasks.
So, lets begin without ado.
We will call the Hugging Face inference API to access the Qwen and LLama models. In addition, we will need the rouge-score library to calculate ROUGE scores for text summarization tasks. The script below installs the required libraries for this article.
!pip install huggingface_hub==0.24.7
!pip install rouge-score
!pip install --upgrade openpyxl
!pip install pandas openpyxl
The script below installs the required libraries.
from huggingface_hub import InferenceClient
import os
import pandas as pd
from rouge_score import rouge_scorer
from sklearn.metrics import accuracy_score
from collections import defaultdict
To access models via the Hugging Face inference API, you will need your Hugging Face User Access tokens.
Next, create a client object for the corresponding model using the InferenceClient class from the huggingface_hub library.
You must pass the Hugging Face model path and the access token to the InferenceClientclass constructor.
The script below creates model clients for Qwen 2.5-72b and Llama 3.1-70b models.
hf_token = os.environ.get('HF_TOKEN')
#qwen 2.5 endpoint
#https://huggingface.co/Qwen/Qwen2.5-72B-Instruct
qwen_model_client = InferenceClient(
"Qwen/Qwen2.5-72B-Instruct",
token=hf_token
)
#Llama 3.1 endpoint
#https://huggingface.co/meta-llama/Llama-3.1-70B-Instruct
llama_model_client = InferenceClient(
"meta-llama/Llama-3.1-70B-Instruct",
token=hf_token
)
To get a response from the model, you can call the chat_completion() method and pass a list of system and user messages to the messages attribute of the method.
The script below defines the make_prediction() method, which accepts the model client, the system role prompt, and the user query and generates a response using the model client.
def make_prediction(model, system_role, user_query):
response = model.chat_completion(
messages=[{"role": "system", "content": system_role},
{"role": "user", "content": user_query}],
max_tokens=10,
)
return response.choices[0].message.content
Let's first generate a dummy response using the Qwen 2.5-72b.
system_role = "Assign positive, negative, or neutral sentiment to the movie review. Return only a single word in your response"
user_query = "I like this movie a lot"
make_prediction(qwen_model_client,
system_role,
user_query)
Output:
'positive'
The above output shows that the Qwen model generates the expected response.
Let's try the Llama 3.1-70b model now.
system_role = "Assign positive, negative, or neutral sentiment to the movie review. Return only a single word in your response"
user_query = "I hate this movie a lot"
make_prediction(llama_model_client,
system_role,
user_query)Output:
'negative'And voila, the Llama also makes correct predictions.
In the following two sections, we will compare the performance of the two models on custom datasets. We see how the two models fare for zero-shot text classification and summarization.
For text classification, we will use the Twitter US Airline Sentiment, which consists of positive, negative, and neutral tweets for various US airlines.
The following script imports the dataset into a Pandas DataFrame.
## Dataset download link
## https://www.kaggle.com/datasets/crowdflower/twitter-airline-sentiment?select=Tweets.csv
dataset = pd.read_csv(r"D:\Datasets\Tweets.csv")
dataset.head()
Output:
We will preprocess our dataset and select 100 tweets (34 neutral and 33 each for positive and negative sentiments).
# Remove rows where 'airline_sentiment' or 'text' are NaN
dataset = dataset.dropna(subset=['airline_sentiment', 'text'])
# Remove rows where 'airline_sentiment' or 'text' are empty strings
dataset = dataset[(dataset['airline_sentiment'].str.strip() != '') & (dataset['text'].str.strip() != '')]
# Filter the DataFrame for each sentiment
neutral_df = dataset[dataset['airline_sentiment'] == 'neutral']
positive_df = dataset[dataset['airline_sentiment'] == 'positive']
negative_df = dataset[dataset['airline_sentiment'] == 'negative']
# Randomly sample records from each sentiment
neutral_sample = neutral_df.sample(n=34)
positive_sample = positive_df.sample(n=33)
negative_sample = negative_df.sample(n=33)
# Concatenate the samples into one DataFrame
dataset = pd.concat([neutral_sample, positive_sample, negative_sample])
# Reset index if needed
dataset.reset_index(drop=True, inplace=True)
# print value counts
print(dataset["airline_sentiment"].value_counts())
Output:
airline_sentiment
neutral 34
positive 33
negative 33
Name: count, dtype: int64
Next, we will define the predict_sentiment() function, which accepts the model client, the system prompt, and the user query and generates a model response.
def predict_sentiment(model, system_role, user_query):
response = model.chat_completion(
messages=[{"role": "system", "content": system_role},
{"role": "user", "content": user_query}],
max_tokens=10,
)
return response.choices[0].message.content
In the next step, we will iterate through the 100 tweets in our dataset and predict sentiment for each tweet using the Qwen 2.5-72b and Llama 3.1-70b models, as shown in the following script.
models = {
"qwen2.5-72b": qwen_model_client,
"llama3.1-70b": llama_model_client
}
tweets_list = dataset["text"].tolist()
all_sentiments = []
exceptions = 0
for i, tweet in enumerate(tweets_list, 1):
for model_name, model_client in models.items():
try:
print(f"Processing tweet {i} with model {model_name}")
system_role = "You are an expert in annotating tweets with positive, negative, and neutral emotions"
user_query = (
f"What is the sentiment expressed in the following tweet about an airline? "
f"Select sentiment value from positive, negative, or neutral. "
f"Return only the sentiment value in small letters.\n\n"
f"tweet: {tweet}"
)
sentiment_value = predict_sentiment(model_client, system_role, user_query)
all_sentiments.append({
'tweet_id': i,
'model': model_name,
'sentiment': sentiment_value
})
print(i, model_name, sentiment_value)
except Exception as e:
print("===================")
print("Exception occurred with model:", model_name, "| Tweet:", i, "| Error:", e)
exceptions += 1
print("Total exception count:", exceptions)
Output:

Finally, we will convert the predictions for both models into a Pandas Dataframe. We will then fetch the predictions for the individual models and compare them with the actual sentiment values in the datasets to calculate accuracy.
# Convert results to DataFrame and calculate accuracy for each model
results_df = pd.DataFrame(all_sentiments)
for model_name in models.keys():
model_results = results_df[results_df['model'] == model_name]
accuracy = accuracy_score(model_results['sentiment'], dataset["airline_sentiment"].iloc[:len(model_results)])
print(f"Accuracy for {model_name}: {accuracy}")
Output:
Accuracy for qwen2.5-72b: 0.8
Accuracy for llama3.1-70b: 0.77The above output shows that the Qwen 2.5-72b model achieves 80% accuracy while the Llama-3.1-70b model achieves 77% accuracy. Qwen 2.5-72b model wins the battle for zero-shot text classification.
Let's now see which model performs better for zero-shot text summarization.
We will use the News Articles Dataset to summarise text using the Qwen and Llama models.
The following script imports the dataset into Pandas DataFrame.
# Kaggle dataset download link
# https://github.com/reddzzz/DataScience_FP/blob/main/dataset.xlsx
dataset = pd.read_excel(r"D:\Datasets\dataset.xlsx")
dataset = dataset.sample(frac=1)
print(dataset.shape)
dataset.head()
Output:
Next, we will check the average number of characters in all summaries. We will use this number as output tokens in the LLM model response.
dataset['summary_length'] = dataset['human_summary'].apply(len)
average_length = dataset['summary_length'].mean()
print(f"Average length of summaries: {average_length:.2f} characters")Output:
Average length of summaries: 1168.78 charactersWe will define the generate_summary() helper method, which takes in the model client, the system prompt, and the user query as parameters and returns the model client response.
def generate_summary(model, system_role, user_query):
response = model.chat_completion(
messages=[{"role": "system", "content": system_role},
{"role": "user", "content": user_query}],
max_tokens=1200,
)
return response.choices[0].message.content
We will also define the calculate_rouge helper method that takes in actual and predicted summaries as parameters and returns ROUGE scores.
# Function to calculate ROUGE scores
def calculate_rouge(reference, candidate):
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
scores = scorer.score(reference, candidate)
return {key: value.fmeasure for key, value in scores.items()}
Finally, we will iterate through the first 20 articles in the dataset and summarize them using the Qwen 2.5-72b and Llama 3.1-70b models. We will use the generate_summary() function to generate the summary of the model and then use the calculate_rouge() method to calculate ROUGE scores for the prediction.
We create a Pandas DataFrame that contains ROUGE scores for all article summaries generated via the Qwen 2.5-72b and Llama 3.1-70b models.
models = {"qwen2.5-72b": qwen_model_client,
"llama3.1-70b": llama_model_client}
results = []
i = 0
for _, row in dataset[:20].iterrows():
article = row['content']
human_summary = row['human_summary']
i = i + 1
for model_name, model_client in models.items():
print(f"Summarizing article {i} with model {model_name}")
system_role = "You are an expert in creating summaries from text"
user_query = f"Summarize the following article in 1150 characters. The summary should look like human created:\n\n{article}\n\nSummary:"
generated_summary = generate_summary(model_client, system_role, user_query)
rouge_scores = calculate_rouge(human_summary, generated_summary)
results.append({
'model': model_name,
'article_id': row.id,
'generated_summary': generated_summary,
'rouge1': rouge_scores['rouge1'],
'rouge2': rouge_scores['rouge2'],
'rougeL': rouge_scores['rougeL']
})
# Create a DataFrame with results
results_df = pd.DataFrame(results)
Output:

Finally, we can take the average ROUGE scores of all the article summaries to compare the two models.
average_scores = results_df.groupby('model')[['rouge1', 'rouge2', 'rougeL']].mean()
average_scores_sorted = average_scores.sort_values(by='rouge1', ascending=False)
print("Average ROUGE scores by model:")
average_scores_sorted.head()Output:
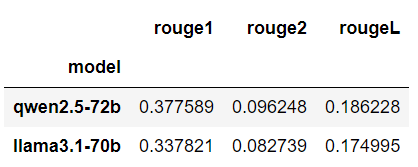
The Qwen model wins here as well for all ROUGE scores.
Open-source LLMs are quickly catching up with proprietary models. Qwen 2.5-72B has already surpassed GPT-4 turbo, introduced at the beginning of this year.
In this article, you saw a comparison between Qwen 2.5-72b and Llama 3.1-70b models for zero-shot text classification and summarization. The Qwen model performs better than Llama on both tasks.
I encourage you to use the Qwen model for text generation tasks like Chatbot development and share your work with us.