

In a previous article, I compared GPT-4o mini vs. GPT-4o and GPT-3.5 Turbo for zero-shot text summarization. The results showed that the GPT-4o mini achieves almost similar performance for zero-shot text classification at a much-reduced price compared to the other models.
I will compare Meta Llama 3.1 70b with OpenAI GPT-4o snapshot for zero-shot text summarization in this article. Meta Llama 3.1 series consists of Meta's state-of-the-art LLMs, including Llama 3.1 8b, Llama 3.1 70b, and Llama 3.1 405b. On the other hand, [OpenAI GPT-4o[(https://platform.openai.com/docs/models)] snapshot is OpenAIs latest LLM. We will use the Groq API to access Meta Llama 3.1 70b and the OpenAI API to access GPT-4o snapshot model.
So, let's begin without ado.
The following script installs the Python libraries you will need to run scripts in this article.
!pip install openai
!pip install groq
!pip install rouge-score
!pip install --upgrade openpyxl
!pip install pandas openpyxl
The script below installs the required libraries into your Python application.
import os
import time
import pandas as pd
from rouge_score import rouge_scorer
from openai import OpenAI
from groq import Groq
This article will summarize the text in the News Articles with Summary dataset. The dataset consists of article content and human-generated summaries.
The following script imports the CSV dataset file into a Pandas DataFrame.
# Kaggle dataset download link
# https://github.com/reddzzz/DataScience_FP/blob/main/dataset.xlsx
dataset = pd.read_excel(r"D:\Datasets\dataset.xlsx")
dataset = dataset.sample(frac=1)
dataset['summary_length'] = dataset['human_summary'].apply(len)
average_length = dataset['summary_length'].mean()
print(f"Average length of summaries: {average_length:.2f} characters")
print(dataset.shape)
dataset.head()
Output:
The content column stores the article's text, and the human_summary column contains the corresponding human-generated summaries.
We also calculate the average number of characters in the human-generated summaries, which we will use to generate summaries via the LLM models.
We are now ready to summarize articles using GPT-4o snapshot and Llama 3.1 70b.
First, we'll create an instance of the OpenAI class, which we'll use to interact with various OpenAI language models. When initializing this object, you must provide your OpenAI API Key.
Additionally, we'll define the calculate_rouge() function, which computes the ROUGE-1, ROUGE-2, and ROUGE-L scores by comparing the LLM-generated summaries with the human-generated ones.
ROUGE scores are used to evaluate the quality of machine-generated text, such as summaries, by comparing them with human-generated text. ROUGE-1 evaluates the overlap of unigrams (single words), ROUGE-2 considers bigrams (pairs of consecutive words), and ROUGE-L focuses on the longest common subsequence between the two texts.
client = OpenAI(
# This is the default and can be omitted
api_key = os.environ.get('OPENAI_API_KEY'),
)
# Function to calculate ROUGE scores
def calculate_rouge(reference, candidate):
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
scores = scorer.score(reference, candidate)
return {key: value.fmeasure for key, value in scores.items()}
Next, we will iterate through the first 20 articles in the dataset and call the GPT-4o snapshot model to produce a summary of the article with a target length of 1150 characters. We will use 1150 characters because the average length of the human-generated summaries is 1168 characters. Next, the LLM-generated and human-generated summaries are passed to the calculate_rouge() function, which returns ROUGE scores for the LLM-generated summaries. These ROUGE scores, along with the generated summaries, are stored in the results list.
%%time
results = []
i = 0
for _, row in dataset[:20].iterrows():
article = row['content']
human_summary = row['human_summary']
i = i + 1
print(f"Summarizing article {i}.")
prompt = f"Summarize the following article in 1150 characters. The summary should look like human created:\n\n{article}\n\nSummary:"
response = client.chat.completions.create(
model= "gpt-4o-2024-08-06",
messages=[{"role": "user", "content": prompt}],
max_tokens=1150,
temperature=0.7
)
generated_summary = response.choices[0].message.content
rouge_scores = calculate_rouge(human_summary, generated_summary)
results.append({
'article_id': row.id,
'generated_summary': generated_summary,
'rouge1': rouge_scores['rouge1'],
'rouge2': rouge_scores['rouge2'],
'rougeL': rouge_scores['rougeL']
})
Output:

The above output shows that it took 59 seconds to summarize 20 articles.
Next, we convert the results list into a results_df dataframe and display the average ROUGE scores for 20 articles.
results_df = pd.DataFrame(results)
mean_values = results_df[["rouge1", "rouge2", "rougeL"]].mean()
print(mean_values)
Output:
rouge1 0.386724
rouge2 0.100371
rougeL 0.187491
dtype: float64
The above results show that ROUGE scores obtained by GPT-4o snapshot are slightly less than the results obtained by GPT-4o model in the previous article.
Let's evaluate the summarization of GPT-4o using another LLM, GPT-4o mini, in this case.
In the following script, we define the llm_evaluate_summary() function, which accepts the original article and LLM-generated summary and evaluates it on the completeness, conciseness, and coherence criteria.
def llm_evaluate_summary(article, summary):
prompt = f"""Evaluate the following summary for the given article. Rate it on a scale of 1-10 for:
1. Completeness: Does it capture all key points?
2. Conciseness: Is it brief and to the point?
3. Coherence: Is it well-structured and easy to understand?
Article: {article}
Summary: {summary}
Provide the ratings as a comma-separated list (completeness,conciseness,coherence).
"""
response = client.chat.completions.create(
model= "gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=100,
temperature=0.7
)
return [float(score) for score in response.choices[0].message.content.strip().split(',')]
We iterate through the first 20 articles and pass the content and LLM-generated summaries to the llm_evaluate_summary() function.
scores_dict = {'completeness': [], 'conciseness': [], 'coherence': []}
i = 0
for _, row in results_df.iterrows():
i = i + 1
# Corrected method to access content by article_id
article = dataset.loc[dataset['id'] == row['article_id'], 'content'].iloc[0]
scores = llm_evaluate_summary(article, row['generated_summary'])
print(f"Article ID: {row['article_id']}, Scores: {scores}")
# Store the scores in the dictionary
scores_dict['completeness'].append(scores[0])
scores_dict['conciseness'].append(scores[1])
scores_dict['coherence'].append(scores[2])
Finally, the script below calculates and displays the average scores for completeness, conciseness, and coherence for GPT-4o snapshot summaries.
# Calculate the average scores
average_scores = {
'completeness': sum(scores_dict['completeness']) / len(scores_dict['completeness']),
'conciseness': sum(scores_dict['conciseness']) / len(scores_dict['conciseness']),
'coherence': sum(scores_dict['coherence']) / len(scores_dict['coherence']),
}
# Convert to DataFrame for better visualization (optional)
average_scores_df = pd.DataFrame([average_scores])
average_scores_df.columns = ['Completeness', 'Conciseness', 'Coherence']
# Display the DataFrame
average_scores_df.head()
Output:

In this section, we will perform a zero-shot text summarization of the same set of articles using the Llama 3.1 70b model.
You should try the Llama 3.1 405b model to get better results. However, at the time of writing this article, Groq Cloud had suspended the API calls for Llama 405b due to excessive demand. You can also try other cloud providers to run Llama 3.1 405b.
The process remains the same for text summarization using Meta Llama 3.1 70b. The only difference is that we will create an object of the Groq client in this case.
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
Next, we will iterate through the first 20 articles in the dataset, generate their summaries using the Llama 3.1 70b model, calculate ROUGE scores, and store the results in the results list.
%%time
results = []
i = 0
for _, row in dataset[:20].iterrows():
article = row['content']
human_summary = row['human_summary']
i = i + 1
print(f"Summarizing article {i}.")
prompt = f"Summarize the following article in 1150 characters. The summary should look like human created:\n\n{article}\n\nSummary:"
response = client.chat.completions.create(
model="llama-3.1-70b-versatile",
temperature = 0.7,
max_tokens = 1150,
messages=[
{"role": "user", "content": prompt}
]
)
generated_summary = response.choices[0].message.content
rouge_scores = calculate_rouge(human_summary, generated_summary)
results.append({
'article_id': row.id,
'generated_summary': generated_summary,
'rouge1': rouge_scores['rouge1'],
'rouge2': rouge_scores['rouge2'],
'rougeL': rouge_scores['rougeL']
})
Output:

The above output shows that it only took 24 seconds to process 20 article using Llama 3.1 70b. The faster processing is because Llama 3.1 70b is a smaller model than the GPT-4o snapshot. Also, Groq uses LPU (language processing unit) which is much faster for LLM inference.
Next, we will convert the results list into the results_df dataframe and display the average ROUGE scores.
results_df = pd.DataFrame(results)
mean_values = results_df[["rouge1", "rouge2", "rougeL"]].mean()
print(mean_values)
Output:
rouge1 0.335863
rouge2 0.080865
rougeL 0.170834
dtype: float64
The above output shows that the ROUGE scores for Meta Llama 3.1 70b are lower compared to the GPT-40 snapshot model. I would again stress that you should use Llama 3.1 405b to get better results.
Finally, we will evaluate the summaries generated via Llama 3.1 70b using the GPT-4o mini model for completeness, conciseness, and coherence.
client = OpenAI(
# This is the default and can be omitted
api_key = os.environ.get('OPENAI_API_KEY'),
)
scores_dict = {'completeness': [], 'conciseness': [], 'coherence': []}
i = 0
for _, row in results_df.iterrows():
i = i + 1
# Corrected method to access content by article_id
article = dataset.loc[dataset['id'] == row['article_id'], 'content'].iloc[0]
scores = llm_evaluate_summary(article, row['generated_summary'])
print(f"Article ID: {row['article_id']}, Scores: {scores}")
# Store the scores in the dictionary
scores_dict['completeness'].append(scores[0])
scores_dict['conciseness'].append(scores[1])
scores_dict['coherence'].append(scores[2])
# Calculate the average scores
average_scores = {
'completeness': sum(scores_dict['completeness']) / len(scores_dict['completeness']),
'conciseness': sum(scores_dict['conciseness']) / len(scores_dict['conciseness']),
'coherence': sum(scores_dict['coherence']) / len(scores_dict['coherence']),
}
# Convert to DataFrame for better visualization (optional)
average_scores_df = pd.DataFrame([average_scores])
average_scores_df.columns = ['Completeness', 'Conciseness', 'Coherence']
# Display the DataFrame
average_scores_df.head()
Output:
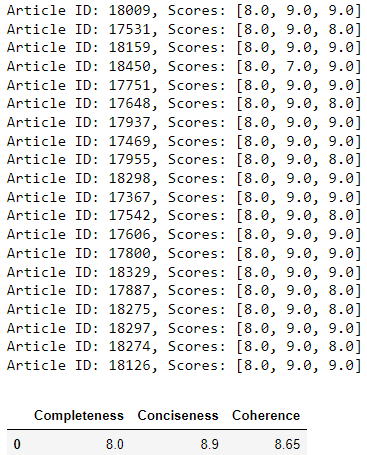
The above output shows that Llama 3.1 70b achieves performance similar to GPT-4o snapshot for text summarization when evaluated using 3rd LLM.
Meta Llama 3.1 series models are state-of-the-art open-source models. This article shows that Meta Llama 3.1 70b performs very similarly to GPT-4o snapshot for zero-shot text summarization. I stress that you use the Llama 3.1 405b model from Groq to see if you can get better results than GPT-4o.