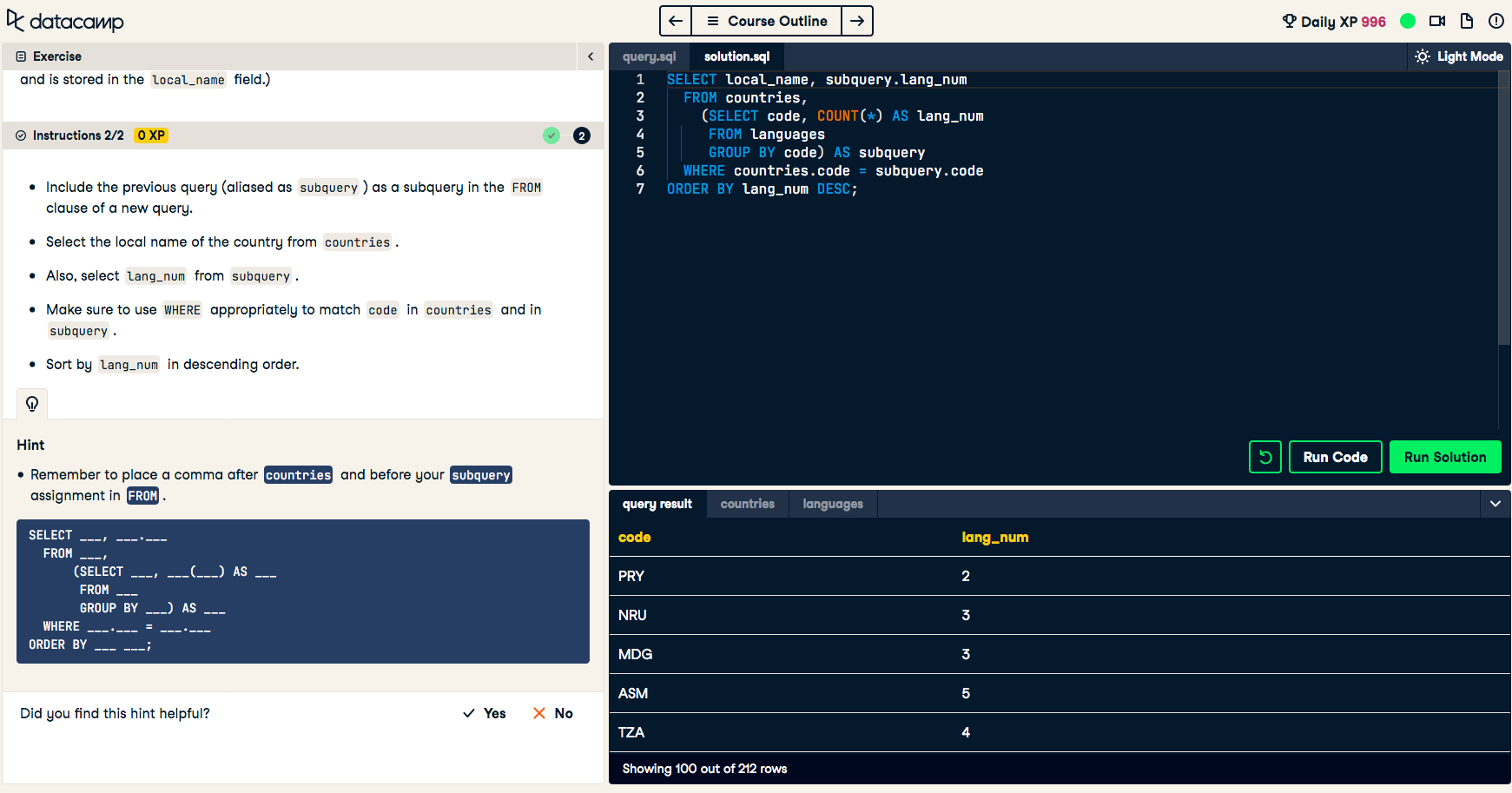
Hi everyone I am wondering if someone can help me understand why the Sub-Query's SELECT statement ended up producing the column name 'Code' vs. the initial SELECT statment call 'local_name' in the below screenshot Thanks in advance!

Tips, Expertise, Articles and Advice from the Pro's for Your Website or Blog to Succeed

Hi everyone I am wondering if someone can help me understand why the Sub-Query's SELECT statement ended up producing the column name 'Code' vs. the initial SELECT statment call 'local_name' in the below screenshot Thanks in advance!

Stripe, a provider of a payment processing platform, is launching an embedded finance API called Stripe Treasury. The new API will allow partners to embed banking services into their platform or online marketplace.

The new Crawl Stats in Google Search Console shows a breakdown of how much googlebot recrawls existing content for refreshing its index, and how much is discovery of new content.
Has anyone been working on increasing the rate of new content and seeing that correlate to a linear increase in traffic?

If you are missing your festive meetups this year or just fancy seeing some friendly faces and learning some new things join us on December 17th for another Smashing Meets event.
Tickets are only 10 USD (and free for our lovely Smashing Members). The fun starts at 9AM ET (Eastern Time) or 15:00 CET (Central European Time) on the 17th December.
Ok. This is important. Smashing Meets by @smashingconf was soooo much fun. I will have to tune in whenever the timezone suits, it was an absolute blast!!!
— Mandy Michael (@Mandy_Kerr) May 19, 2020
This time, we will have talks from three speakers—Adekunle Oduye, Ben Hong, and Michelle Barker. There will be an interface design challenge and chance to network and meet other attendees. Just like an in-person meetup but you won’t have to go out in the cold!
If you want to know more about how our Smashing Meets events work, we have a review of a previous event, see some of the videos, or just head on over to the event page and get a ticket! I hope to see you there.