In a 2017 speech titled “Stop trying to fix disability,” YouTube and motivational speaker Molly Burke says, “I live in a world that wasn’t built for me, but what if it was?” Burke was born with a rare, genetic eye disease that caused her to go blind. In this short but moving 8 minute video, she contends that making the world accessible helps everyone. She introduces the concept of universal design to her audience in simple terms:
“Universal design [is] designing and building everything to be accessed, enjoyed, and understood to its fullest extent by everyone, regardless of their size, their age, their ability, or their perceived disability.”
“Every product they release, I could buy at a store, open up, and use on my own independently, with no extra cost and no assistance needed,” she said. “I ask you to imagine how liberating, how empowering it is to be shown by a company that they view you as belonging to their customers, when so many others tell you the exact opposite.”
In honor of Global Accessibility Awareness Day, I wanted to highlight this video that tells just one person’s story on the powerful impact of technology that is built with everyone in mind. Burke’s speech is a poignant reminder of how designers and builders can extend a sense of belonging to their customers by making their products accessible.
It occurred to me while we were talking about flexbox and gap that one reason we sometimes reach for flexbox is to chuck some boxes in a row and space them out a little.
My brain still reaches for flexbox in that situation, and with gap, it probably will continue to do so. It’s worth noting though that grid can do the same thing in its own special way.
They all look equal width there, but that’s only because there is no content in them. With content, you’ll see the boxes start pushing on each other based on the natural width of that content. If you need to exert some control, you can always set width / min-width / max-width on the elements that fall into those columns — or, set them with grid-template-columns but without setting the actual number of columns, then letting the min-content dictate the width.
Another thought… if you only want the whole grid itself to be as wide as the content (i.e. less than 100% or auto, if need be) then be aware that display: inline-grid; is a thing.
PHP and WordPress version checks are coming to the WordPress theme system — finally. The feature was pulled into core WordPress three days ago. It will prevent end-users from installing or activating a theme that is incompatible with their current version of PHP or WordPress. The change is slated to land in WordPress 5.5.
This feature has long been on many theme authors’ wish lists, particularly PHP version checking. Plugins authors gained the ability to support specific PHP versions starting with WordPress 5.2. However, theme authors were left feeling like the second-class citizens they usually are when it comes to the addition of core features, waiting patiently as plugin authors received the new and shiny tools they were looking forward to.
Previously, the code for manually handling version checking within individual themes was more complex than in plugins. Theme authors needed to run compatibility checks after theme switch and block theme previews in the customizer using two different methods, depending on the user’s WordPress version. That is assuming theme authors were covering all their bases.
Users had no real way of knowing whether a theme would work on their site before installing and attempting to activate it. It was a poor user experience, even when a theme gracefully failed for the end-user.
This user experience has also held back some theme authors from transitioning to newer versions of PHP. For years, many were supporting PHP 5.2. Slowly, some of these same authors are now making the move toward newer features up to PHP 5.6, which is now the minimum that WordPress supports. However, not many have made the jump to PHP 7 and newer.
Until now, there has been no mechanism for letting the user know they need to upgrade their PHP to use a particular theme.
Some theme authors may choose to continue supporting older versions of PHP, such as 5.6, for a potentially wider user base. However, developers who want to switch to newer features can now do so with the support of the core platform.
Changes for Users
New WordPress and PHP versions added to Twenty Twenty theme.
Users who are browsing the WordPress theme directory may begin to notice new information available for some themes. Similar to plugins, visitors should see a WordPress Version and PHP Version listed for some themes. For example, the Twenty Twenty theme now lists the following minimum requirements:
WordPress Version: 4.7 or higher
PHP Version: 5.2.4 or higher
Not all themes will have these numbers listed yet. It will take some time before older themes are updated with the data required to populate these fields.
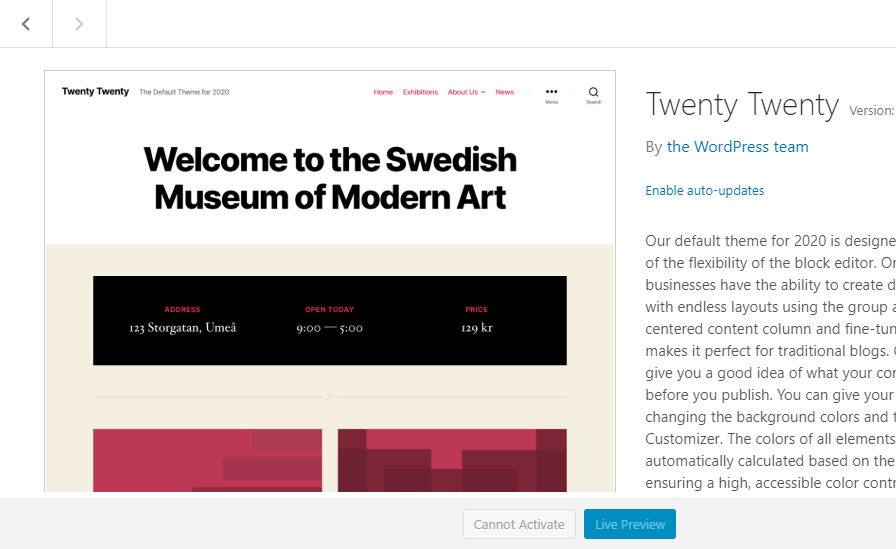
In WordPress 5.5, the admin interface for themes will change. When attempting to install or activate a theme, WordPress will prevent such actions. If a user searches for a theme that has an incompatible WordPress or PHP version, the normal installation button will be replaced with a disabled button that reads “Cannot Install.” If a theme is installed but not activated, the activation link will similarly be replaced with a disabled “Cannot Activate” button. Users will also not be allowed to live preview incompatible themes.
Cannot activate Twenty Twenty theme with incompatible PHP version.
The feature works the same from within the customizer interface as it does via the themes screen in the WordPress admin.
Changes for Theme Authors
The WordPress Themes Team recently announced two new required headers for theme authors to place in their style.css files. The first required field is Tested up to, which is the latest version of WordPress the theme has been tested against. The second is a Requires PHP field, which is the minimum PHP version the theme supports.
It is unclear is why the team decided to require those two fields but not the Requires at least field, which represents the minimum WordPress version needed. Most likely, theme authors will want to place all three headers in their themes.
Theme authors who will still support versions of WordPress earlier than 5.5 will want to continue using their old compatibility checks. However, this is the first step in phasing such code out.
One of the exciting things about WordCamps going virtual is the community gaining access to more events and presentations than ever before, from anywhere in the world. Even in this new online-only format, local camps still retain their unique character as they feature speakers from their respective communities.
WordCamp Kent (Ohio) is one of these upcoming events that has been forced online by the pandemic. Organizers will be broadcasting all sessions on the weekend of May 30-31, and tickets are free for anyone who wants to attend.
The schedule for this particular event runs heavy on the business and marketing side of working with WordPress, with very few talks geared towards developers. If you are a freelancer, run an agency, or have a WordPress product business, you will find WordCamp Kent’s program more tailored to topics that help you improve client services.
The schedule on the first day of the event is divided into two tracks: Freelance/Business and User/Marketing. These sessions will run alongside live Q&A and a Help Desk managed by volunteers in the #wp-help-desk channel in the NEO WordPress Slack workspace. The second day of the event will be also be split into two tracks: Freelance/Business/Developer and WordPress 101/User.
Topics include designing websites for generating leads, improving your business model for freelancers and small businesses, client consultations, content marketing, and customer support.
This Kent, Ohio, WordCamp may not have made it on your radar in the past, but the pandemic has opened up events in some ways. It forces a greater number of camps online and allows attendees to join any event without the travel expenses that would ordinarily be prohibitive. In the past, many people who were not local would simply opt to save their money for the bigger camps. The WordPress community has a greater potential to accelerate their learning opportunities, as more smaller camps gain a global audience online.
Looking for the most customizable WordPress theme? Finding the best WordPress theme that functions and looks exactly how you want can be a daunting task – if not impossible. With hundreds of free and premium...